DM数据库 回表优化案例
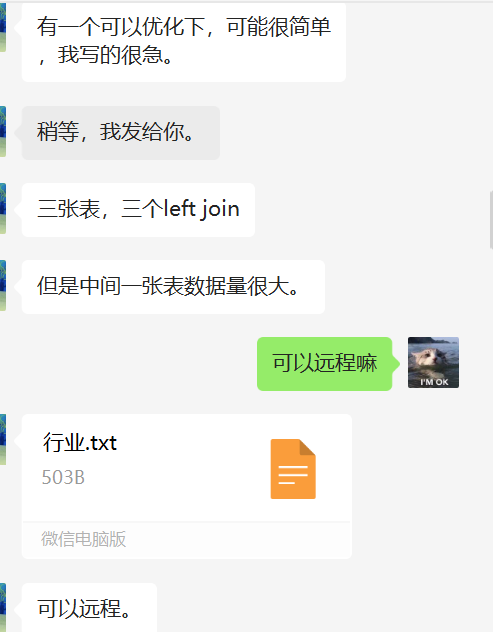
京华开发一哥们找我优化条SQL,反馈在DM数据库执行时间很慢需要 40s 才能出结果,安排。
原SQL:
SELECT A.IND_CODE, A.IND_NAME AS "specialName", COUNT(C.ORDER_ID) AS "orderCount", COUNT(CASE WHEN D.MEDIATE_RESULT IN ('达成调解协议', '双方自行和解') THEN C.ORDER_ID END) AS "successCount" FROM WCWCWC.AAAAAAAAA A LEFT JOIN WCWCWC.BBBBBBBBB B ON A.IND_CODE = B.INDUSTRY_CD LEFT JOIN WCWCWC.ccccccccccccccccc C ON B.UNISCID = C.UNISCID LEFT JOIN WCWCWC.DDDDDDDDDDDDDD D ON C.ORDER_ID = D.ORDER_ID WHERE A.IND_CODE = 'C' GROUP BY A.IND_CODE, A.IND_NAME;
执行计划:
1 #NSET2: [491, 1, 96] 2 #PRJT2: [491, 1, 96]; exp_num(4), is_atom(FALSE) 3 #HAGR2: [491, 1, 96]; grp_num(2), sfun_num(2), distinct_flag[0,0]; slave_empty(0) keys(DMTEMPVIEW_889674440.TMPCOL0, DMTEMPVIEW_889674440.TMPCOL1) 4 #PRJT2: [466, 324467, 96]; exp_num(4), is_atom(FALSE) 5 #HASH RIGHT JOIN2: [466, 324467, 96]; key_num(1), ret_null(0), KEY(D.ORDER_ID=C.ORDER_ID) 6 #CSCN2: [1, 15287, 56]; INDEX33557062(DDDDDDDDDDDDDD as D) 7 #HASH RIGHT JOIN2: [437, 324467, 96]; key_num(1), ret_null(0), KEY(C.UNISCID=B.UNISCID) 8 #CSCN2: [11, 97535, 56]; INDEX33557061(ccccccccccccccccc as C) 9 #HASH LEFT JOIN2: [386, 324467, 96]; key_num(1), partition_keys_num(0), ret_null(0), mix(0) KEY(A.IND_CODE=B.INDUSTRY_CD) 10 #INDEX JOIN LEFT JOIN2: [386, 324467, 96] ret_null(0) 11 #ACTRL: [386, 324467, 96]; 12 #BLKUP2: [1, 1, 96]; INDEX33557119(A) 13 #SSEK2: [1, 1, 96]; scan_type(ASC), INDEX33557119(AAAAAAAAA as A), scan_range['C','C'] 14 #BLKUP2: [351, 324467, 48]; IND_INDUSTRY_CD(B) 15 #SSEK2: [351, 324467, 48]; scan_type(ASC), IND_INDUSTRY_CD(BBBBBBBBB as B), scan_range[A.IND_CODE,A.IND_CODE] 16 #CSCN2: [727, 5840415, 96]; INDEX33558123(BBBBBBBBB as B)
A、B、C、D 表 所有关联列都有索引,整体SQL返回一行数据,但是要 39s 左右,非常不合理。
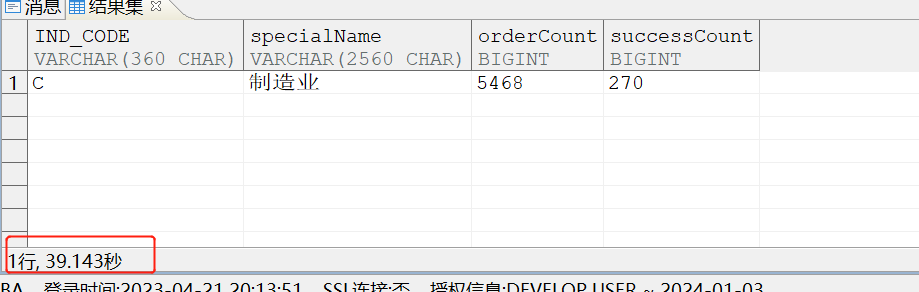
数据量如下:
select count(1) ,'A' from WCWCWC.AAAAAAAAA union all select count(1) ,'B' from WCWCWC.BBBBBBBBB union all select count(1) ,'C' from WCWCWC.ccccccccccccccccc union all select count(1) ,'D' from WCWCWC.DDDDDDDDDDDDDD;
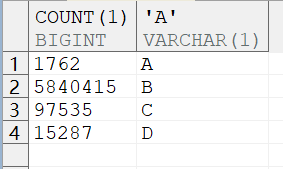
监控下缓慢的节点:
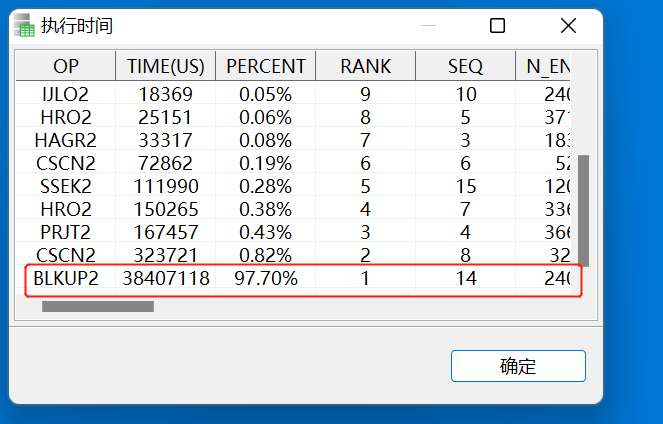
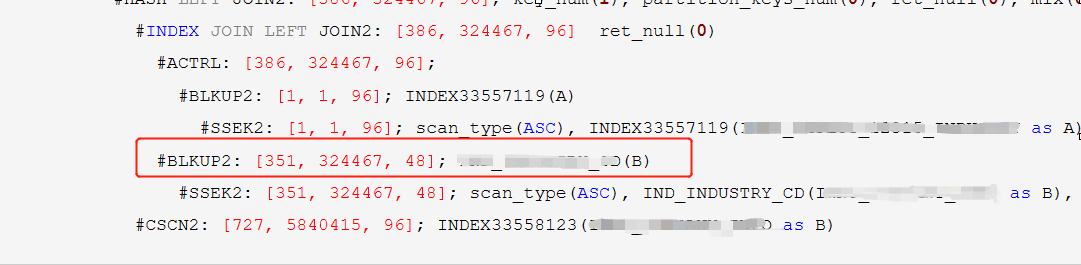
发现慢的节点是 B 表产生BLKUP2,500多W行数据回表 ,IND_INDUSTRY_CD 索引无法找到所有数据。
B表创建联合索引:
create index idx_BBBBBBBBB_1_2 on WCWCWC.BBBBBBBBB(INDUSTRY_CD,UNISCID);
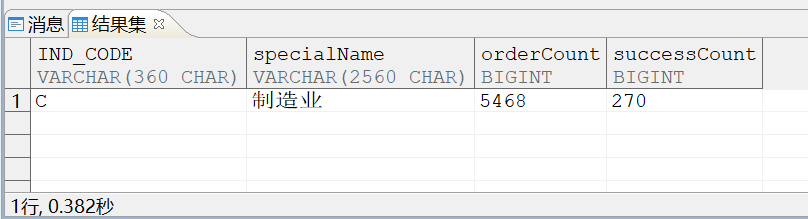
新的执行计划:
1 #NSET2: [158, 1, 96] 2 #PRJT2: [158, 1, 96]; exp_num(4), is_atom(FALSE) 3 #HAGR2: [158, 1, 96]; grp_num(2), sfun_num(2), distinct_flag[0,0]; slave_empty(0) keys(DMTEMPVIEW_889674491.TMPCOL0, DMTEMPVIEW_889674491.TMPCOL1) 4 #PRJT2: [133, 324467, 96]; exp_num(4), is_atom(FALSE) 5 #HASH RIGHT JOIN2: [133, 324467, 96]; key_num(1), ret_null(0), KEY(D.ORDER_ID=C.ORDER_ID) 6 #CSCN2: [1, 15287, 56]; INDEX33557062(DDDDDDDDDDDDDD as D) 7 #HASH RIGHT JOIN2: [104, 324467, 96]; key_num(1), ret_null(0), KEY(C.UNISCID=B.UNISCID) 8 #CSCN2: [11, 97535, 56]; INDEX33557061(ccccccccccccccccc as C) 9 #HASH LEFT JOIN2: [54, 324467, 96]; key_num(1), partition_keys_num(0), ret_null(0), mix(0) KEY(A.IND_CODE=B.INDUSTRY_CD) 10 #INDEX JOIN LEFT JOIN2: [54, 324467, 96] ret_null(0) 11 #ACTRL: [54, 324467, 96]; 12 #BLKUP2: [1, 1, 96]; INDEX33557119(A) 13 #SSEK2: [1, 1, 96]; scan_type(ASC), INDEX33557119(AAAAAAAAA as A), scan_range['C','C'] 14 #SSEK2: [49, 324467, 96]; scan_type(ASC), IDX_BBBBBBBBB_1_2(BBBBBBBBB as B), scan_range[(A.IND_CODE,min),(A.IND_CODE,max)) 15 #SSCN: [727, 5840415, 96]; IDX_BBBBBBBBB_1_2(BBBBBBBBB as B)
可以看到在创建完联合索引后,#BLKUP2: [351, 324467, 48]; 回表计划消失了,SQL也能0.3S跑出结果。
B表UNISCID字段本身就是主键,而INDUSTRY_CD字段本身有索引,开发老哥以为走了两个字段都走索引不会有什么问题,而忽略了回表计划,在大表产生回表计划是非常恐怖的事情!!!
总结:近两年感觉国产数据库市场份额越来越高了,笔者SQL优化的案例更多得也是从ORACLE、MySQL变成了DM、金仓数据库,
建议大家还是要好好深入学习下国产数据库,免得35岁被优化了找不到工作 。 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号