

RabbitMQ(一 初识)
背景
在web开发过程中有遇到这样的情况:有一部分业务处理速度很慢,但它的结果对最终的返回没有影响,即使报错了,也不需要返回错误信息,只需要在另一个地方可以查询这部分业务的信息即可。例如:用户下单并成功支付,我们需要修改订单状态,并返回回去,但这中间需要做些其他操作,例如发邮件,发短信,生成相应资料,这些操作耗时但不影响返回。
这种情况下,我们就需要将这部分业务做单独处理,一种解决方式是多线程,但这样做比较占用资源,我们期望的是将这部分任务放到另一台服务器,并且不关心他们的返回。于是,我们可以采用消息队列的形式来处理任务。
rabbitMQ 简介
是一款开源的企业级消息队列,自带来集群,管理插件等,下面我们根据rabbit构建我们的队列系统
rabbitmq 安装
- 根据自己系统选择安装包,我的是macOS,
brew install rabbitmq - docker 运行
docker run -d --hostname my-rabbit -p 4369:4369 -p 5672:5672 -p 571:5671 --name some-rabbit rabbitmq:3
pika 安装
pip install pika
pika是rabbitmq最常用的python包
工作流程
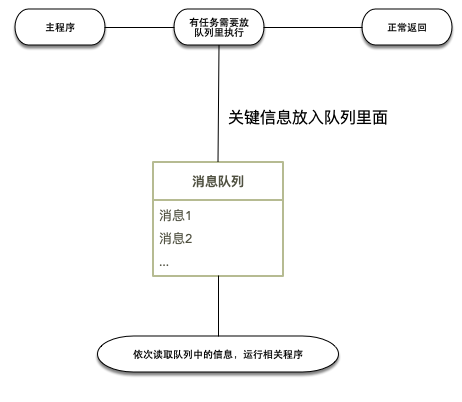
相关代码
- 将消息推送入队列的代码。运行前需要先启动rabbit服务器。
import pika
import sys
# 连接启动的rabbitmq服务器, 指定对应的host,port(默认是5672),
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 申明一个消息队列, durable 参数为消息发出后,如果没被接收,将存入队列,或者丢弃。
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
# 将消息压入队列中
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
- 接收消息并进行处理
import pika
import time
# 连接rabbitmq 服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 指定要连接的队列,
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
# 阻塞在这里,监听队列中的消息,如果有新的消息过来,调用callback进行处理
channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号