机器学习 coursera【week10-11】
week10Large scale machine learning
10.1Gradient Descent with Large Datasets
大数据集的好处是可以让拟合更加完美,也就是说Jcv和Jtrain的误差error更小。
10.2Stochastic Gradient Descent
算法实现是通过得出某个代价函数,某个最优化目标实现;用梯度下降方法求代价函数最小值。
当数据集大时,用梯度下降方法会使得运算慢。
所以可以用随机梯度下降法运用到较大数据训练集情况。
批量梯度下降算法batch gradient algorithm
随机梯度下降法第一步:将所有数据打乱,重行排列m个训练样本
为什么一开始要将数据打乱:从一开始,到二,直至外部循环多次遍历整个训练集。(外层循环循环次数决定于模型复杂度)
随机梯度下降不需要对所有m个训练样本求和得到梯度项,只需要对单个训练样本求梯度项。

10.3Mini-Batch Gradient Descent

小批度下降介于随机梯度下降和批量梯度下降之间,通常选择b=10(原来是m),从2-100的值都是普遍的
week11photo PCR
11.1photo OCR
机器学习照片中文字识别的步骤
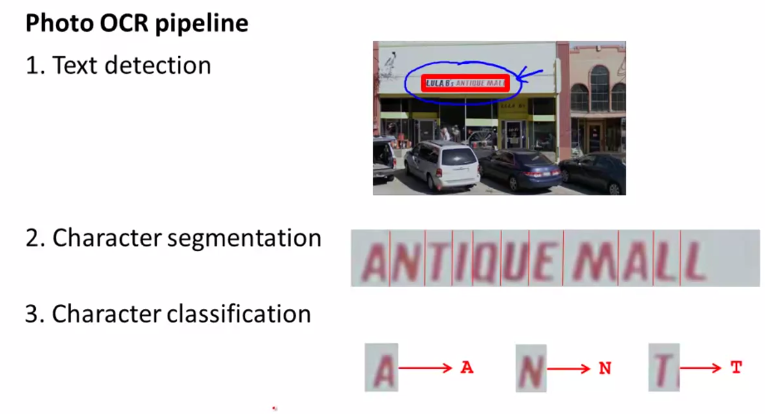
11.2Getting Lots of Data and Artificial Data
获得更多数据的两点讨论

总结,通过扭曲,变形和对称可以扩大训练样本,制造新样本。
要寻找更多样本要
第一要分析学习曲线,进行合理性检查,保证使用更多的数据能有效果;
第二要评估工时,投入的时间成本。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号