八爪鱼采集器
1. 基本步骤
- 自定义采集步骤
- 打开网页
- 建立列表循环
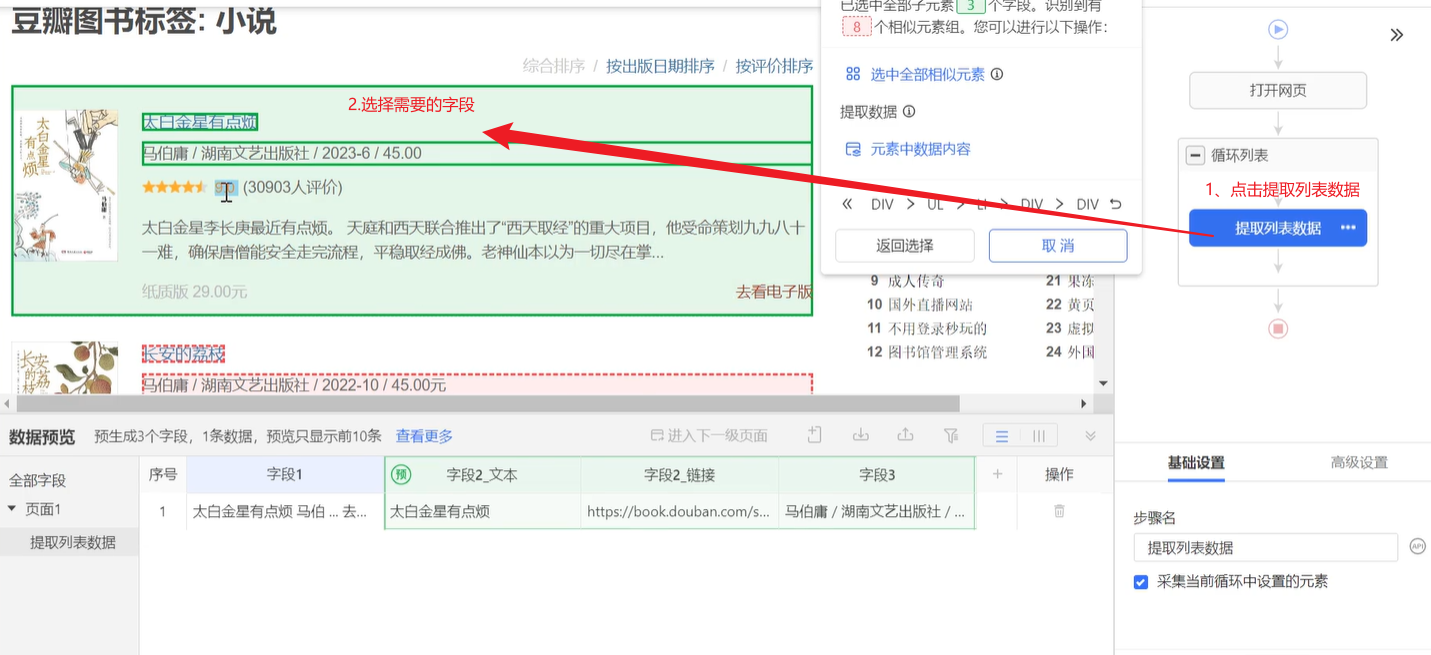
- 采集所需字段
- 建立翻页循环
- 获取爬取的字段信息
2. Xpath
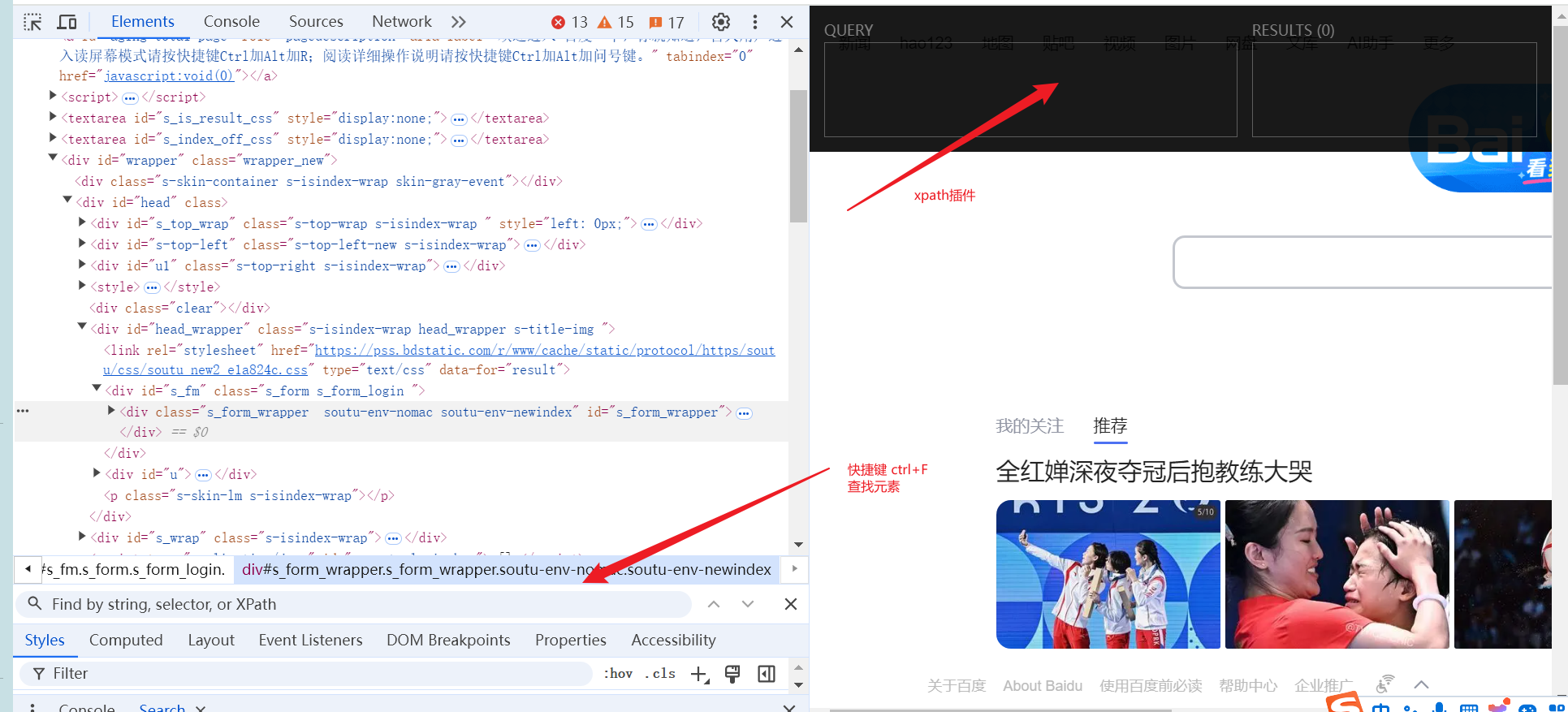
安装及使用
2.1 基本概念
-
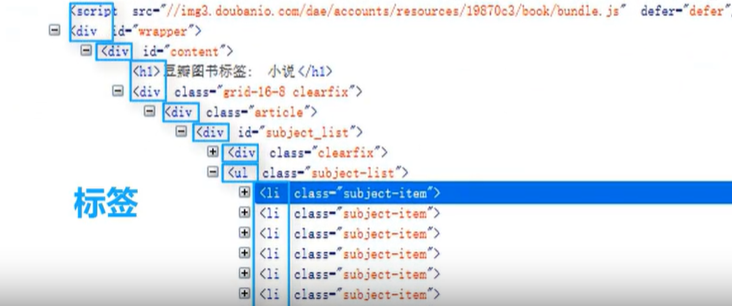
标签:
-
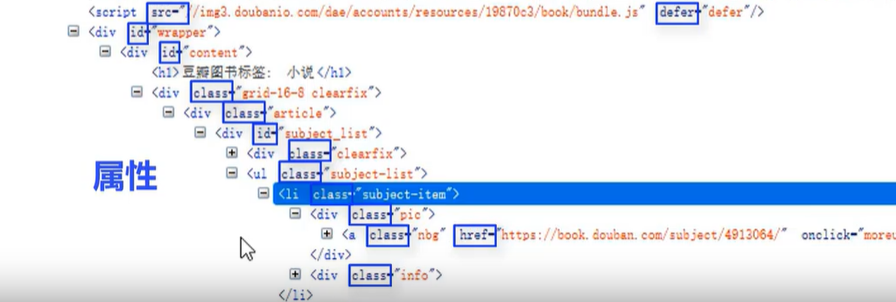
属性:
-
属性值:
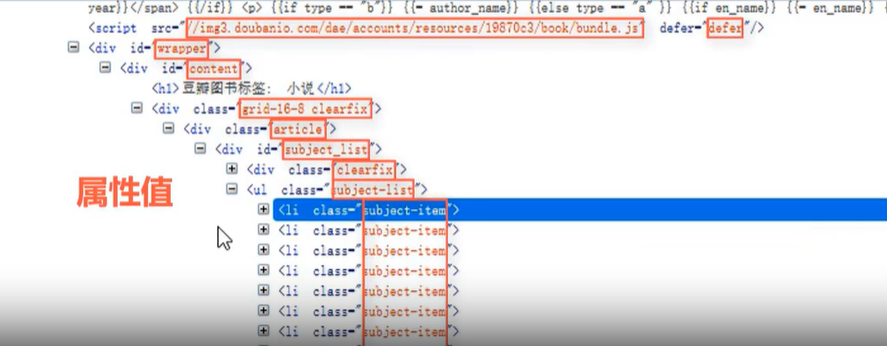
-
文本:

-
常见的HTML标签:


- /和//的区别

2.2 函数
- 每个Xpath函数有它的固定的写法,必须遵循它的写法,否则可能无法定位到元素。
- Xpath中的所有符号,例如()、[]、""、''都是英文符号,不可以写中文符号
- text()函数
- 通过文本来定位网页元素的函数,查找的是当前元素的文本。
- [text()="文本"]
注意:使用text()="文本"时,双引号内的文本必须和网页上的一模一样 例://a[text()="后页>"]
- string()函数
- 用字符串来定位网页元素的函数,查找的是当前语速机器包含的所有元素的文本。
- [string()="文本"]
注意:使用string()="文本"时,双引号内的文本必须和网页上的一模一样
- contains()函数
- 用来判读那标签的文本中是否包含XXX或者判读那某个属性的属性值是否包含XXX。
- [contains(text(),"文本")]或[contains(@属性,"属性值")]
- position()函数
- 用来定位节点的位置和范围,常用于控制循环列表的项
- [position()=<>数字]
- 案例:

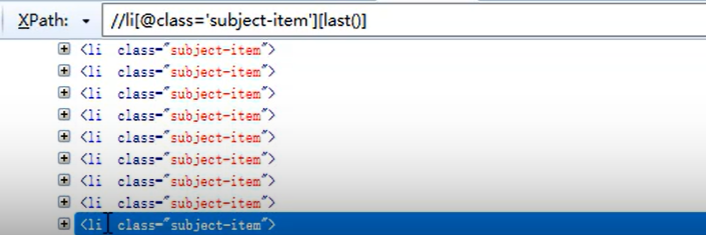
- last()函数
- 功能同position()函数一致
- [last()]
- 案例:
- and/or/not函数
- 通常用来对标签所含的属性进行界定
- [@属性1 and @属性2]、[@属性1 or @属性2]、[not(@属性1)]
- 案例:

- following-sibling函数
- 选取当前节点之后的所有同级节点,不包括它自己
- [/following-sibling:😗]
单斜杠是绝对路径
"::"后面,如果你要定位a标签就写a,定位span标签就写span,如果想全部定位就写,代表可以是任意标签。
- 案例:

- preceding-sibling函数
- 定位的是当前结点之前的所有同级节点
- count函数
- 用于判断当前结点下某种子节点的个数是否大于小于或等于某个数值
- [count(子节点标签)=<>数字]
count()仅能计算下一级的节点个数
- 案例:

2.3 修改循环列表
- 固定元素列表:就是一条XPath对应列表里的一项,如果要定位多项列表,需要在XPath里面写出每一项的XPath
- 不固定元素列表:写一条通用的语句
2.4 修改翻页的网页
- 点击“循环翻页”中的元素XPath进行修改
2.5 相对XPath:字段相对于当前循环列表项的XPath
- 提取循环列表内的数据,要提取的字段包含在循环列表内


- 提取循环列表外的数据,要提取的字段在循环列表外


- 先利用二级循环建立提取步骤
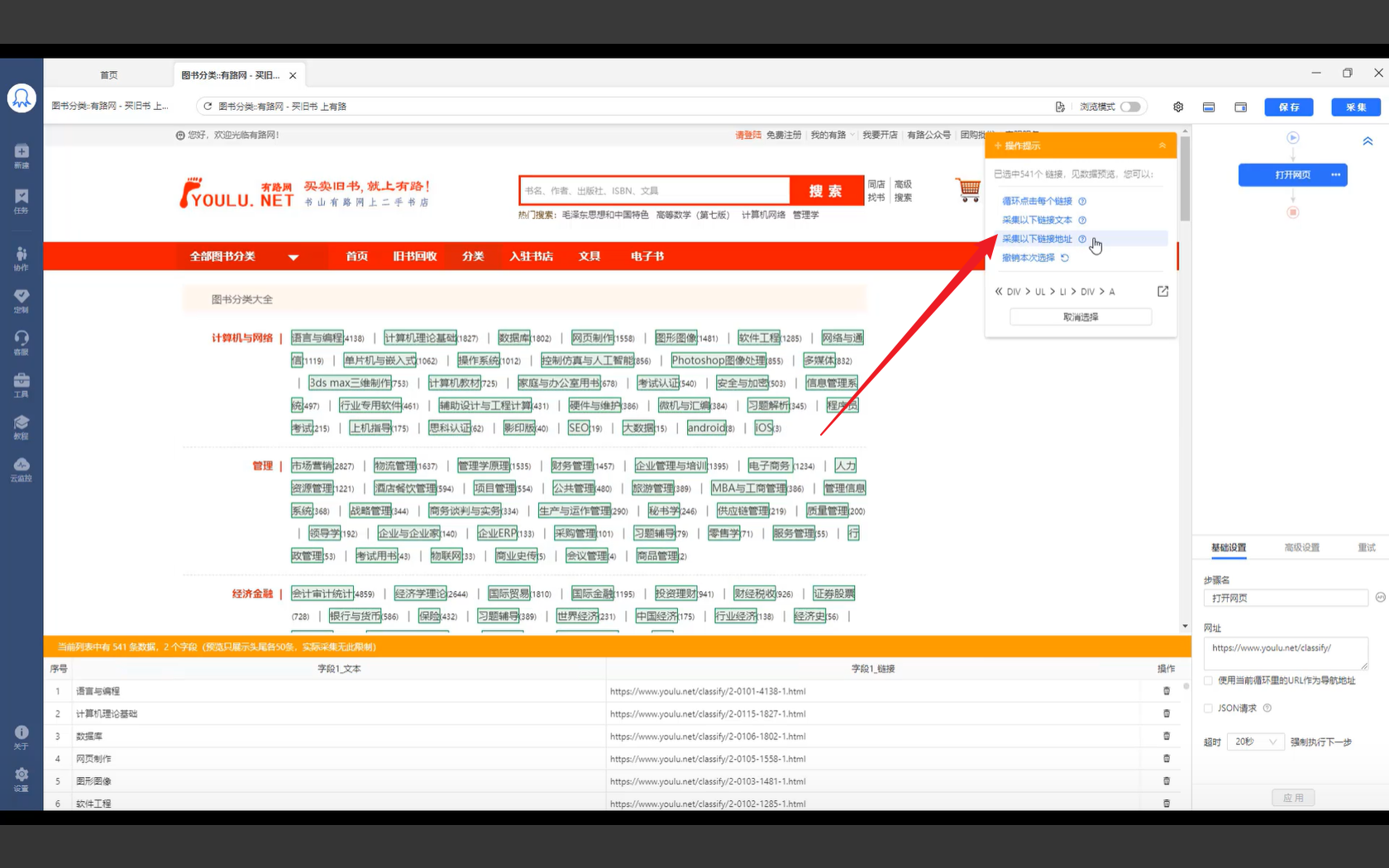
- 使得二级分类和一级分类一一对应
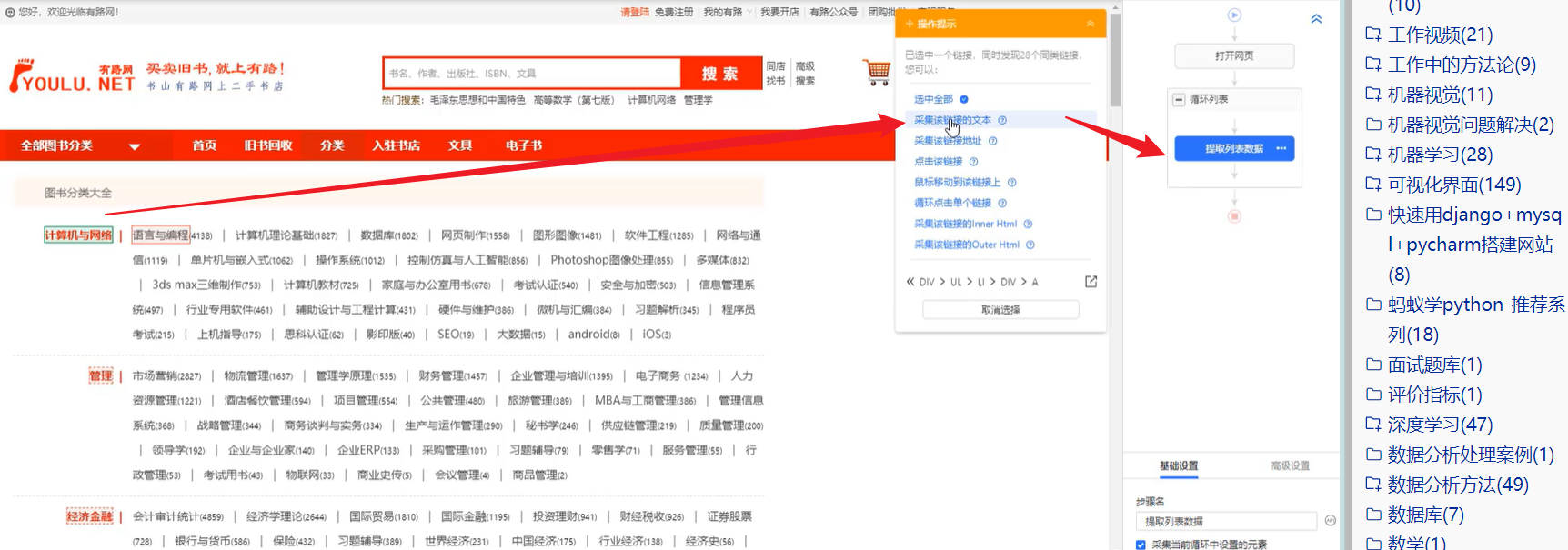


能获取二级目录的标签,然后对这个位置进行回退,再定位到一级位置
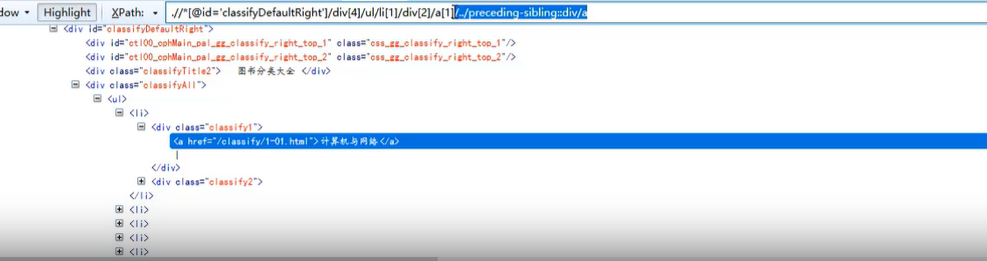
该方法只适用于提取循环外面是单个数据的,循环外饰列表的,有多行数据的不可用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号