第12章 python正则表达式
正则表达式就是与中文的内容进行匹配 ,验证网站:https://regex101.com
1.常见语法
- 汉字、英文就对应文本中查找的部分
- 元字符:. * + ? \ [ ] ^ $ { } | ( )
- 点:匹配除了换行符之外的任何单个字符
- 星号:匹配前面的子表达式任意次,包括0次-n次
- 加号:匹配前面的子表达式一次或多次,不包括0次
- 花括号:前面的字符匹配指定的次数
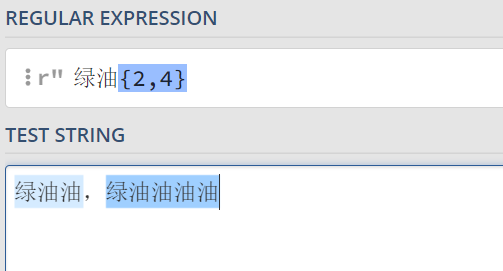
- {3,4}->至少3次、至多4次
- {4}->就是4次
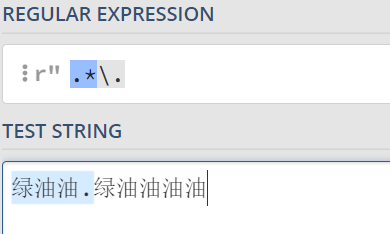
- 反斜杠:恢复. *等元字符原本的含义,形式即'\.'
- \d 匹配0-9之间任意一个数字字符,等价于表达式【0-9】
-\D 匹配任意一个不是0-9之间的数字字符,等价于表达式【^0-9】
-\s 匹配任意一个空白字符
-\S匹配任意一个非空白字符
-\w匹配任意一个文字字符,包括大小写字母、数字、下划线,纯英文要制定ASCII码格式
-\W匹配任意一个非文字字符
- \d 匹配0-9之间任意一个数字字符,等价于表达式【0-9】
- 方括号-匹配某几种类型的字符
- 【a-b】:表示从a到b
- 【abc】:表示a,b,c中任意一个字符
- 【元字符】:元字符不需要转义
- 【^】:表示非得概念,除了某种字符之外的字符
- 起始位置和单行、多行模式
^表示开头$表示结尾- re.compile(r'正则表达式',re.M)表示多行模式,默认是单行模式
- 括号 :
- 组选择()
- 问号:
- ?表示出现0或1次
- 切割字符串
- splite()结合正则表达式
- sub替换
- 参数:match
- match.group(0) 返回匹配上的整个字符串
- match.group(1) 返回第一个group分组的内容
在python中实现上述方法:
- 点的案例
content="""
苹果是绿色的
橙子是黄色的
乌鸦是黑色的
"""
import re
p=re.compile(r'.色')
for one in p.findall(content):
print(one)

- 星号的案例:.* 表示后面的任意单个字符,甚至0个
content="""
苹果,是绿色的
橙子,是黄色的
乌鸦,是黑色的
鸭梨,
"""
import re
p=re.compile(r',.*')
for one in p.findall(content):
print(one)

- 花括号的案例
- 反斜杠的案例
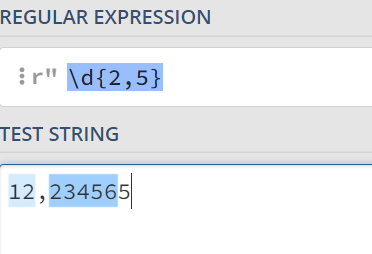
source='''
王亚辉
tony
刘文武
'''
import re
p=re.compile(r'\w{2,4}',re.A) #ASCII码格式
print(p.findall(source))
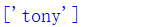
-
方括号的案例
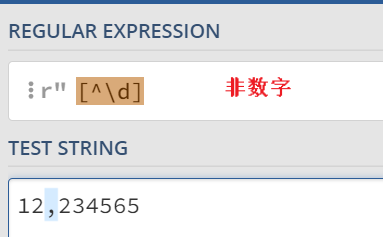
-
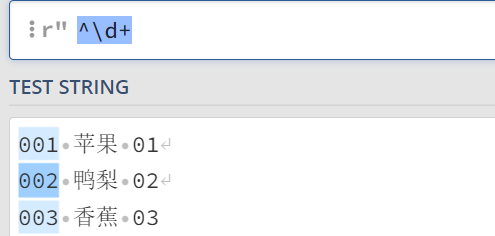
起始位置和单行、多行模式案例
开头:
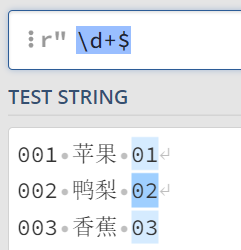
结尾:
单行模式代码:

多行模式代码:
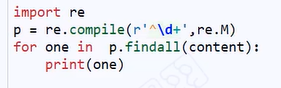
-
括号选择
组选择案例:
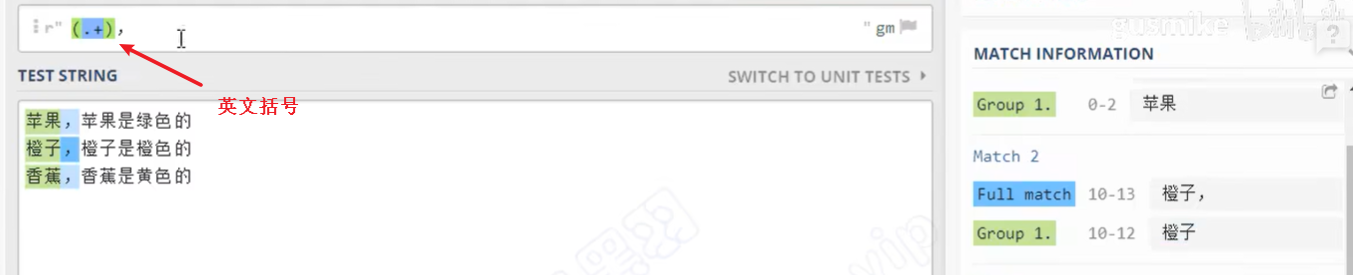
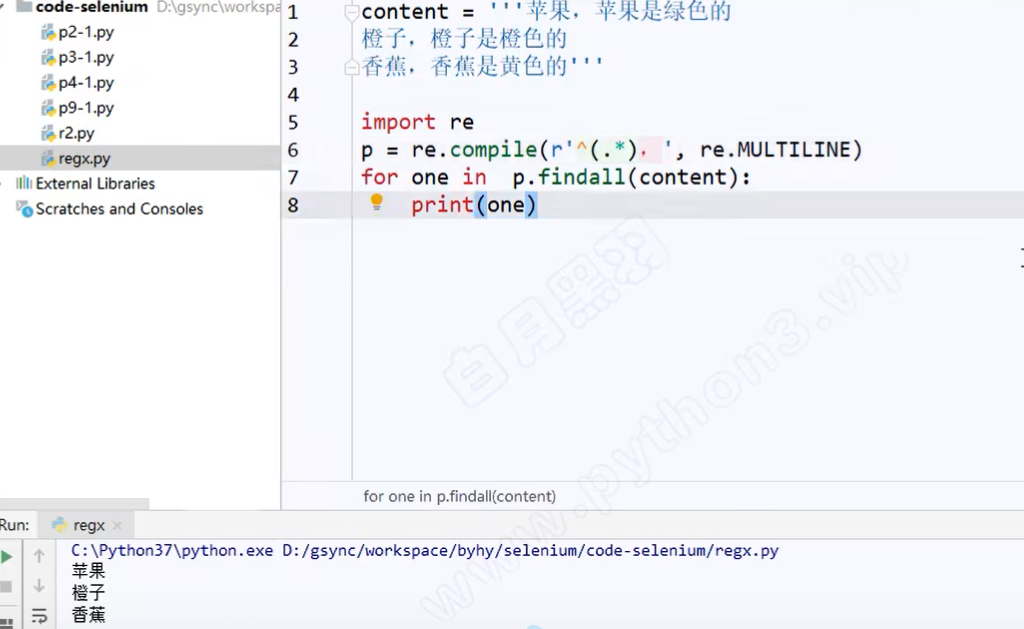
组选择代码:
多组选取:
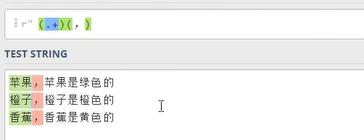
多组选取代码:
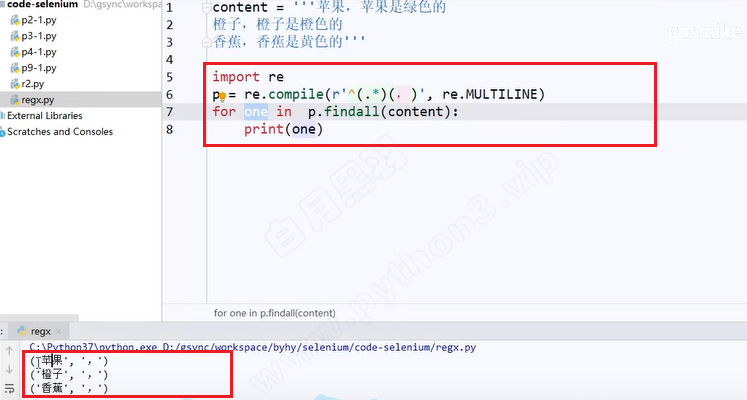
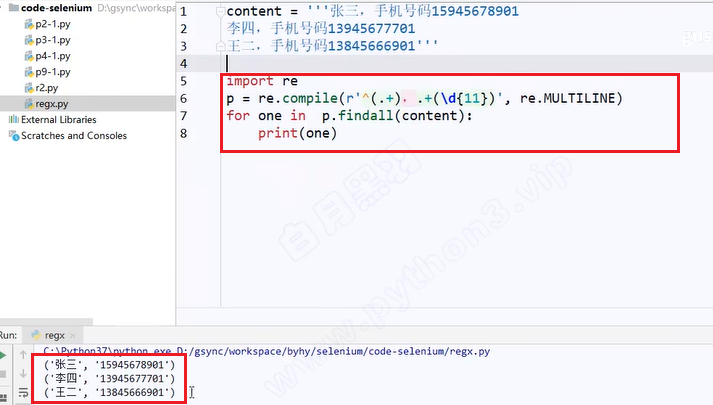
-
切割字符串

-
sub替换
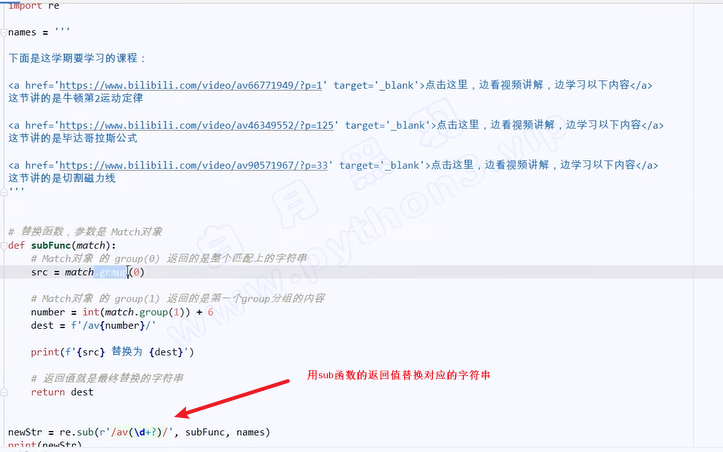
2. 贪婪模式和非贪婪模式
- 针对 * 和 + 号
- 贪婪就是全匹配,非贪婪就是截取
source='<html><head><title>Title</title>'
import re
p=re.compile(r'<.+>')
print(p.findall(source))
p1=re.compile(r'<.+?>')
print(p1.findall(source))
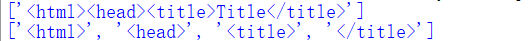
牛客刷题
1.正则查找网址
- re.match函数尝试从字符串的开头开始匹配一个模式,如果匹配成功,返回一个匹配成功的对象,否则返回None。
- re.match(pattern, string, flags = 0)
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式。如是否区分大小写、是否多行匹配等。
- re.match(pattern, string, flags = 0)
正则表达式常见的几种函数:
- re.match()函数 如果想要从源字符串的起始位置匹配一个模式
- re.search()函数 会扫描整个字符串并进行对应的匹配。
该函数与re.match()函数最大的不同是,re.match()函数从源字符串的开头进行匹配,而re.search()函数会在全文中进行检索匹配。 - re.compile() 在以上两个函数中,即便源字符串中有多个结果符合模式,也只会匹配一个结果,那么我们如何将符合模式的内容全部都匹配出来呢?
题目:
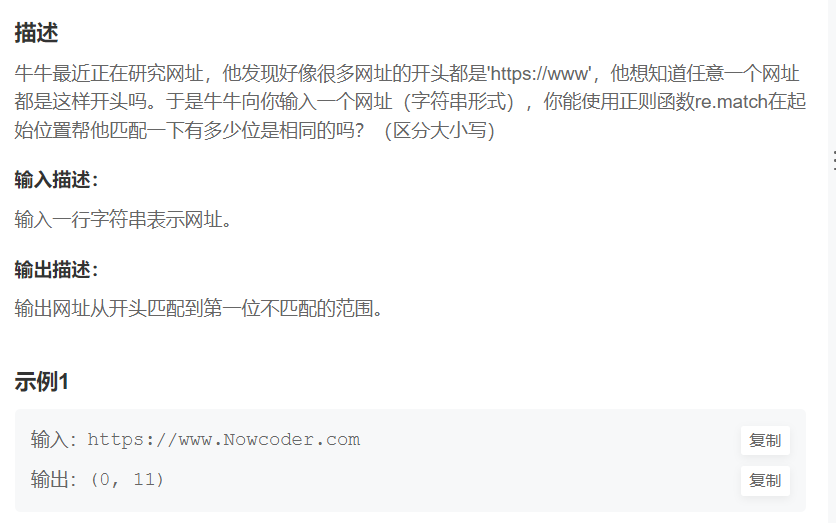
import re
print(re.match(r'https://www', input(),flags=True).span())
2.提取数字电话
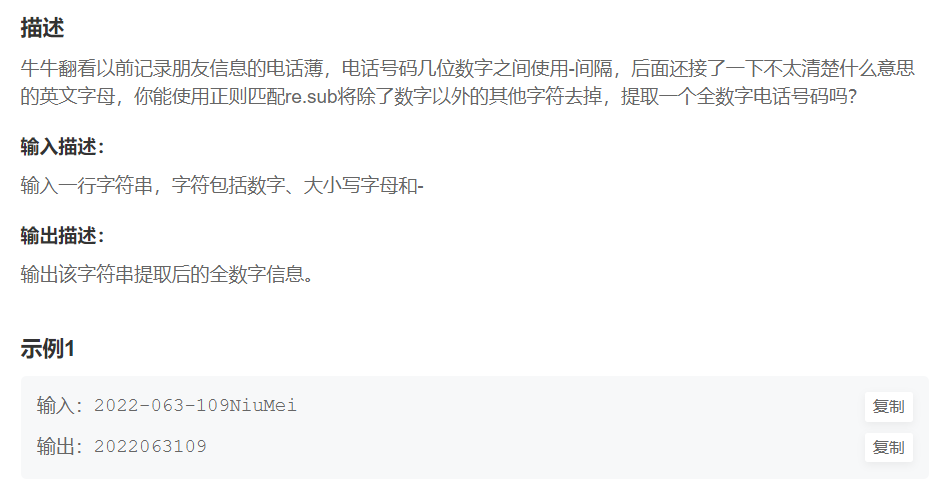
import re
s=input()
p=re.compile(r'\d')
for one in p.findall(s):
print(one,end="")
3.截断电话号码
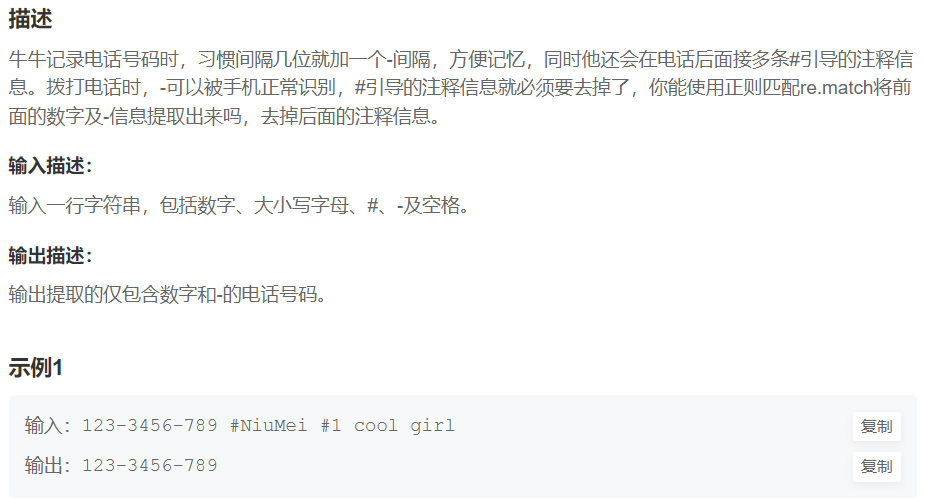
import re
s=input()
res=re.match(r'(\d*[-]?)*',s)
print(res.group())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号