19 池化层的使用
一、常用池化层
功能:减少模型的计算量
1.最大池化
- 卷积核区域取最大值作为结果
- 参数说明
输入输出都是四维:N是batch_size,C是channel

ceil_model为True,保留不完整的部分,否则去掉 (下面案例中stride=3)
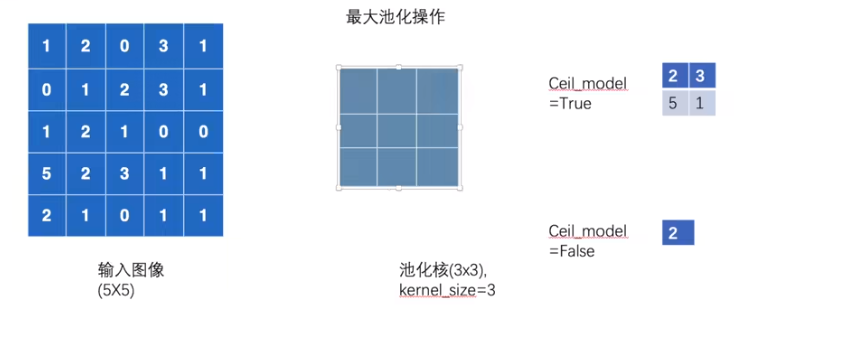
2.案例
- 矩阵的池化
点击查看代码
import torch
# 1.输入图片
from torch import nn
from torch.nn import MaxPool2d
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) #如果不指定类型,就会认为是long型,这样就会报错
# 2.输入转换为四维
input= torch.reshape(input,(-1,1,5,5)) #-1表示程序自己调节batchsize,1表示一个通道
print(input.shape)
# 3.定义神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)#stride默认为kernel_size的大小
def forward(self,input):
output=self.maxpool1(input)
return output
# 4.调用网络
tudui=Tudui()
output=tudui(input)
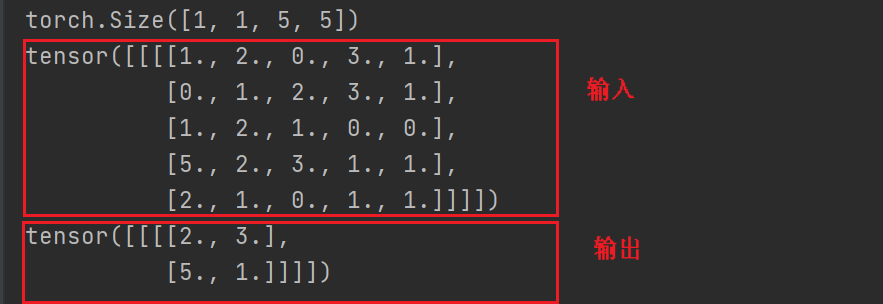
print(input)
print(output)#经过池化后的输出
结果:
- 利用公开数据集进行可视化测试
点击查看代码
import torch
# 1.输入图片
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
#1.测试集
from torch.utils.tensorboard import SummaryWriter
test_data=torchvision.datasets.CIFAR10(root="./CIFAR10_dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
test_loader=DataLoader(dataset=test_data,batch_size=64)
# 2.定义神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)#stride默认为kernel_size的大小
def forward(self,input):
output=self.maxpool1(input)
return output
# 3.调用网络
tudui=Tudui()
# 4. 可视化
writer=SummaryWriter("./logs_19_2")
step=0
for data in test_loader:# 对应数据集
imgs,target=data
writer.add_images("input",imgs,step)
output=tudui(imgs)
writer.add_images("output",output,step)
step=step+1
writer.close()
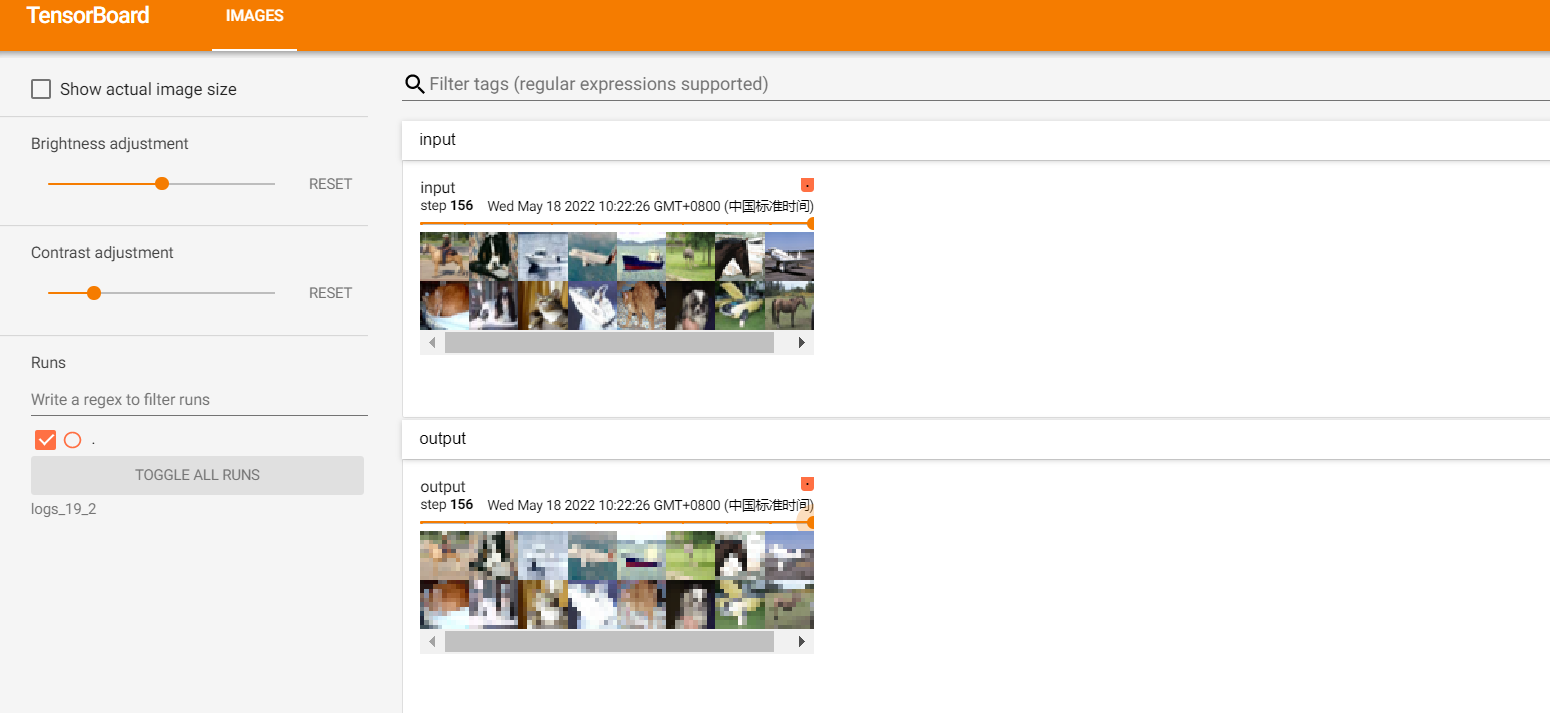
- terminal运行代码
tensorboard --logdir=logs_19_2 --host=127.0.0.1
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号