15 DataLoader的使用
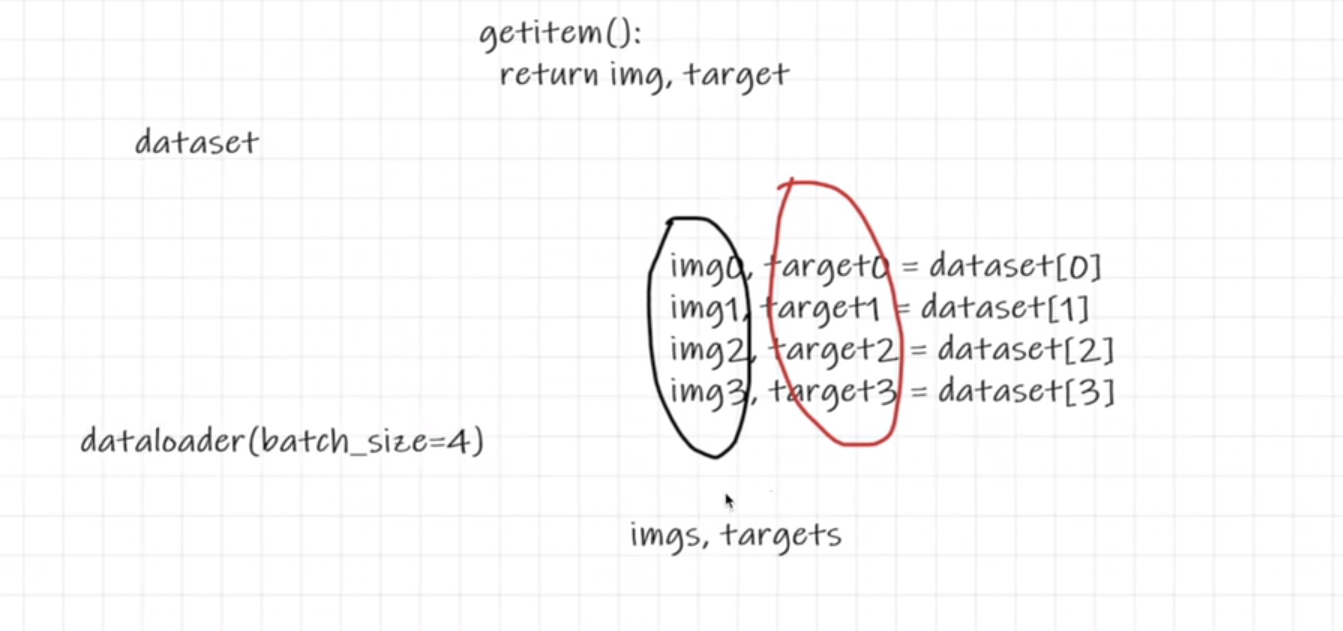
一、dataset与dataloader的区别
- dataset:数据集本身
- dataloader:提取数据集的方式
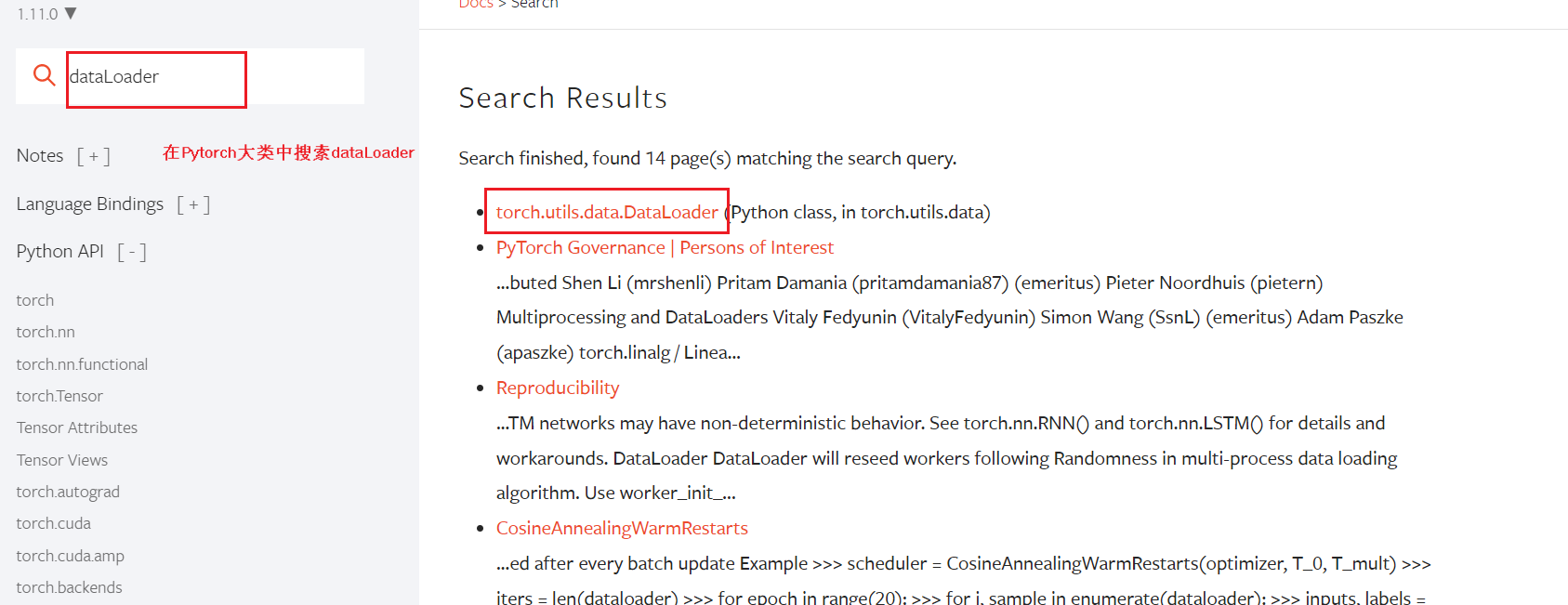
二、dataloader方法
- 方法查询和解析:
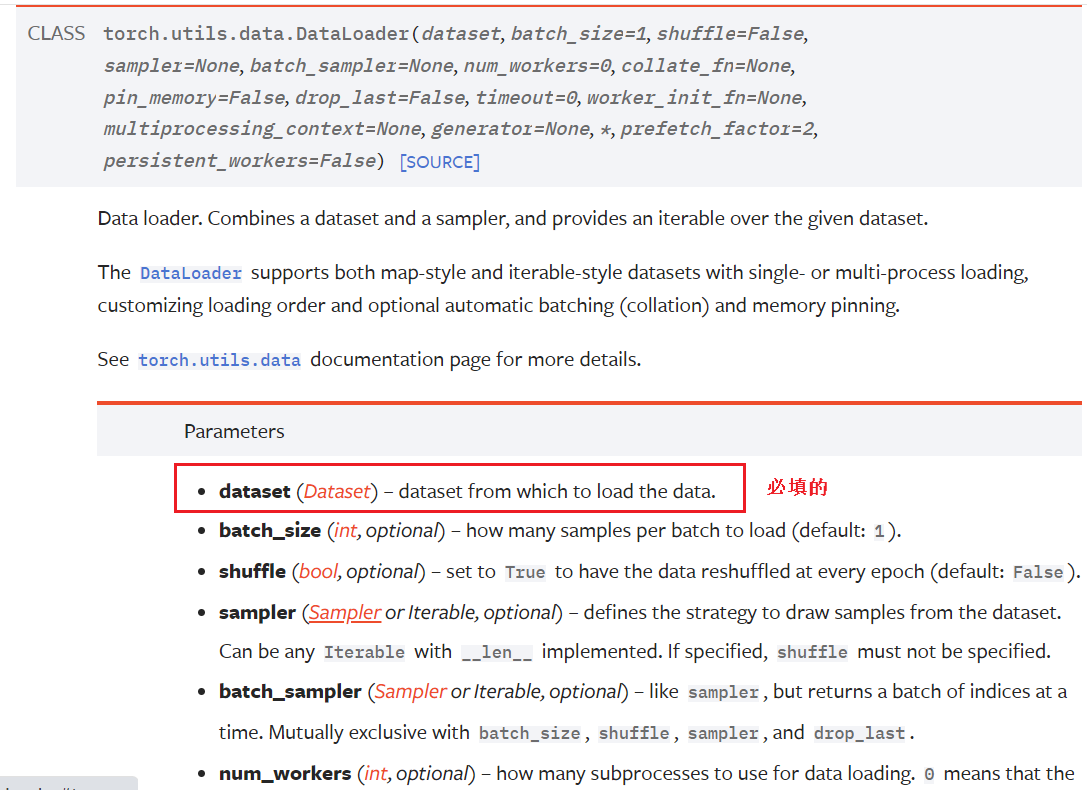
2. 参数:
- batch_size:每次抓几张
- shuffle:每次洗牌的顺序是否一样,True为不一样(一般情况),False为一样
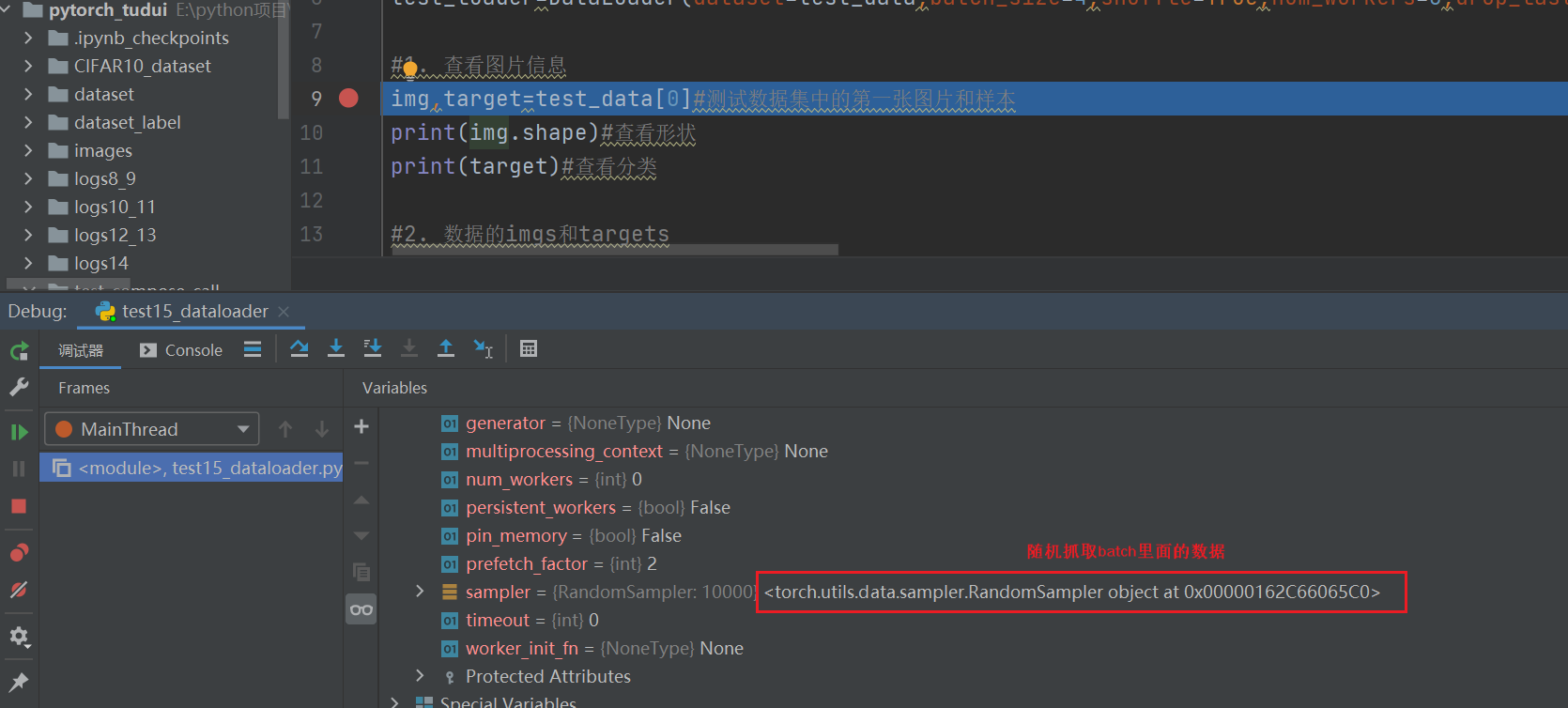
- num_workers:单个进程(设置为0)还是多个进程(大于0),多个进程比较快,但是容易报错(如下),就改为0

- drop_last:不能整除的部分,为True舍去,为False保留
- dataloader应用
- 数据的imgs和targets
for data in test_loader:
imgs,targets=data
print(imgs.shape)
print(targets)

- 随机抓取:
- add_images()及相关参数的使用:
点击查看代码
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#测试集
test_data=torchvision.datasets.CIFAR10(root="./CIFAR10_dataset",transform=torchvision.transforms.ToTensor(),train=False,download=True)
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=True)
#1. 查看图片信息
img,target=test_data[0]#测试数据集中的第一张图片和样本
print(img.shape)#查看形状
print(target)#查看分类
# #2. 数据的imgs和targets
# for data in test_loader:
# imgs,targets=data
# print(imgs.shape)
# print(targets)
#3. 把batchsize改为64 进行展示
writer=SummaryWriter("logs_15")
step=0
for data in test_loader:
imgs,targets=data
# writer.add_images("test_data",imgs,step) #这个注意是添加images 而不是image
writer.add_images("test_data_drop_last", imgs, step) # 这个注意是添加images 而不是image
step+=1 #控制执行几次
#4. 测试shuffle参数 看每次取样是否相同
for epoch in range(2):
step=0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step += 1 # 控制执行几次
writer.close()
执行代码:
tensorboard --logdir=logs_15 --host=127.0.0.1
运行效果:

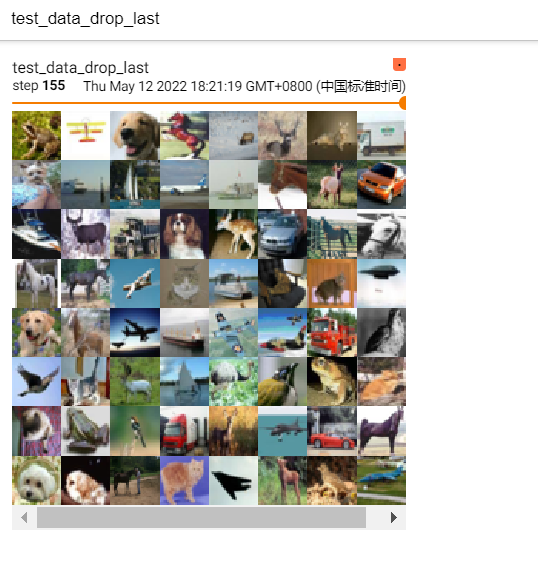
drop_last=False 的效果:
表示取余部分不去掉
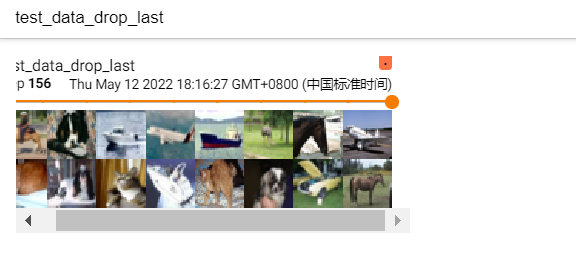
drop_last=True 的效果:
表示取余部分去掉
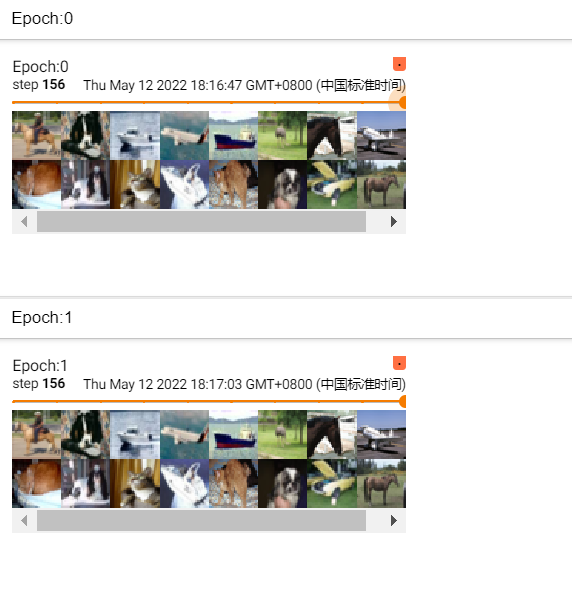
shuffle=False的效果:
表示每次取样的图片都相同,但是一般情况下,令其为True

 浙公网安备 33010602011771号
浙公网安备 33010602011771号