P5 Cache
一、写在前面
P5实验是搭建一个Cache模块,首先应当了解,为什么在主存之外使用Cache?Cache发挥作用的基本逻辑是怎样的?
-
为什么使用
Cache?在ppt中可以了解到,无论存取指令或数据所访问的储存单元都趋于聚集在一个较小的连续储存区域中,而存在比主存普遍采用的
DRAM储存器技术更快的储存单元电路,加之其价格较高,故不难想到设置一个容量较小的高速缓存,即Cache,来存放访问频繁的那些程序块和数据,从而提升读取效率。 -
Cache发挥作用的基本逻辑是怎样的?要了解其原理,首先需了解一些相关术语:

主存与
Cache一次交换数据的最小单位为块(Block),代表高速缓存与主存一次读写操作所能完成的数据字节数,是电路中的底层模块之一。Tag用以保存数据所在的主存数据块的地址,起到高速缓存与主存之间的联系作用。对于有效位v,是为保证读取的数据不为实验以外的其它无关数据,故只有当tag一致且v=1的时候才判定为命中。接下来,对于
Cache作用原理,这里分读、写两种情况说明:-
读取数据的时候,使用tag比对,若比对成功,即
Cache中存有输入地址处的数据,则直接将对应的数据输出(不访问主存);若没有命中,即前往主存读取数据(数据保证主存中一定存有目前读入的数据),通过传输hit信号实现。为了体现主存访问与
Cache访问的时间差异,题目要求:当读取且没命中时,先暂停五个周期(RAM输出stop信号),在第六个周期时再执行这条指令。在第六个周期时,输出数据并将数据写入Cache中(根据LRU替换策略,按照顺位更新计数器最大的Block)。注意此处应当输出从主存里读到的数据,因为Cache的写入需要一个周期,此时目标块的输出数据还未更新(即hit=0、Cache_dataout=0、stop=0)。一种输出的可行搭建方式如下:
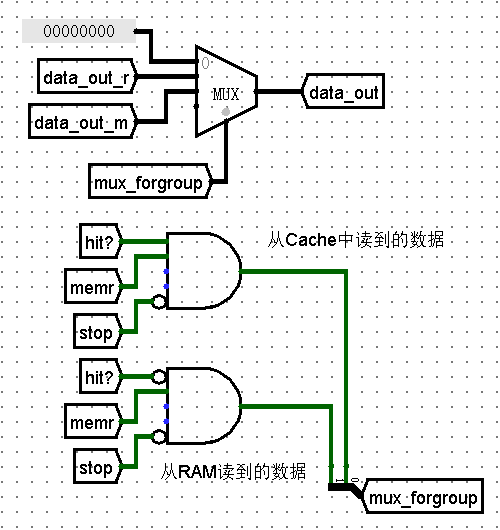
-
写入数据的时候,实现
RAM与Cache的同步写入。对于
RAM而言,若命中,则更新命中块中的数据;若不命中则不更新任何块内的数据。
到现在,
Cache在哪里节约了访问时间便清晰了:当Cache命中且不为写入状态,就不会访问RAM进行数据操作,从而达到了使用Cache的初衷。 -
-
组相连与本实验采用的
Cache规格题目要求模拟四路组相联的
Cache,那么组相连是什么?规格如何计算得来?-
组相连
组相连映射是直接映射和全相联映射的折衷。直接映射指主存中的每一块都固定映射到
Cache中的一块,全相联指主存中的块可以映射到Cache中的任意一块。那么,对于组相联而言,主存与Cache划分为相同数量的组数,主存中的组与Cache中的组一一对应,且主存中的块可以映射到Cache对应组中的任意一块,兼顾了实现成本和灵活性。或许结合图看会更易于理解:https://zhuanlan.zhihu.com/p/102293437
-
Cache规格分析题目中说明:
RAM大小为4K,Cache大小为256B,每一个Block为16B。那么题目中说的:Cache中一组有4块,RAM中一组有64块如何算得?(2^10 =1K、2^20 =1M)由于Logisim软件中一根线的最大位宽为32位(4B),而
Cache和RAM是以块为单位进行数据交换的,按照规格要求,每一个Block为16B,故在传输数据时需要四根线的位宽,这也是Block存放了128位二进制数的原因(按一定顺序存放,这里采用从高位到低位的存放方式)。Cache的组数为:总容量 /(Block大小 × 每组包含的块数)RAM每组的块数为:总容量 /(Block大小 × 通过Cache计算得到的组数)总而言之,总容量=每个
Block的大小×块数×组数,知二求一即可。P.S.对于
Cache中每组包含块的个数,不能通过规格计算出来,题目会做出规定。一个ppt上的例子:

-
组内块地址、组地址与块内地址的使用
组内块地址一般采用:主存地址 - 组地址(组数决定)- 组内地址(
Block容量决定)得到。组内块地址即为tag,用以判断命中;组地址决定访问
Cache和RAM中哪一个组;组内地址决定访问块中那根线的数据。由于实验采用的一根线的位宽为32位,故组内地址末两位一定为0,为操作方便,采用的输入地址的分线方式如下:
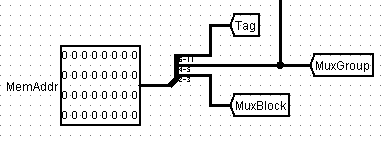
此处需注意:块内地址偏移方向为从数据低位到数据高位,若采用从高位到低位的数据存放方式,数据输出时应进行反转。
-
二、一些具体模块的说明
由于模块层层嵌套,故建议读者自底向上搭建模块,如先从Block,LRU开始搭建。
-
LRULRU模块的逻辑通过此模块的名字就可以知晓大部分,就是通过每个Block对应的Counter和它们的命中情况来判断是否需要更新某个Block的数据,其中,Block对应的Counter计算的是此Block距离最近一次数据访问过了多少个周期,计数器的数字越大,说明此Block距离最近一次数据访问过得时间越长,更新时会找到数据最大的一个Block进行更新。在计数器都相等的情况下,我们规定数据更新的顺序为1→2→3→4。
——指导书
是否命中 是否写入 LRU模块操作 命中 写入 更新命中的模块 命中 不写入 不更新数据 未命中 写入 不更新数据 未命中 不写入 按照顺位更新计数器最大的Block 根据表格可以知道,LRU会在两种情况下输出使能型号,使块内数据更新:①写入数据时,若命中则更新对应块中的数据;②读取数据时,若没有命中,则将从主存中读取的数据按照上述规则存入高速缓存中。
为实现
Counter数值的比较,可采用类似冒泡排序的方法把最大值依次浮动到最上层。注意:①若使能信号为0,则4个输出信号全为0;②提交测评的时候需要apperance与题目所给图完全一致。
-
Counter这个模块的计数其实就是为上述
LRU模块的操作服务,使用logisim自带的计数器即可。计数器归零时,有三种情况,一是进行了复位操作,二是在读取时发现命中了,三是都没有命中即将按顺位更新对应的Block数据,这样就可以表明此Block距离最近一次数据访问过了多少个周期。其中,只有复位操作可以不在时钟上升沿进行。——指导书
注意最后一句话,由于reset是异步复位的,但是其余情况的清零却要求同步,故不能把相关信号接到
Counter的reset端,而应通过载入一个0的方式使计数器清0。此外应注意当Counter的count端为1且load端为1时进行的是计数减一,而非载入操作,故应当将清零情况取反,接到Counter使能端,确保清零的正常进行。综合第二、三种情况来看,第三种情况只在读取的时候发生,故计数器清零操作只在读取的时候进行。那么第二、三种情况能否仅用
LRU输出的使能信号囊括呢?需知读入时命中并不需要更新数据块,故LRU不会输出使能信号,而此时却应当更新Counter,故不能合并。为排除LRU于写入时输出的使能信号对计数的干扰(此时计数值均保持不变),结合前面对清零操作只在读取的时候进行的分析,需将memread信号放入Counter的使能端。说了这么多,具体这么搭呢?可参照下图:
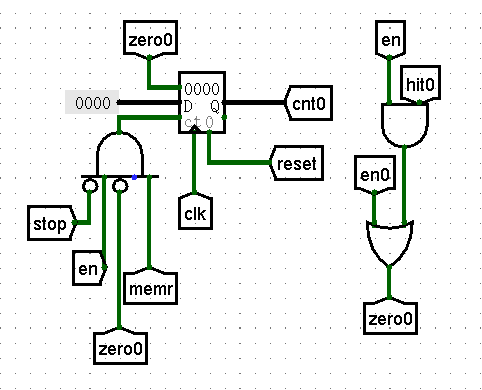
-
stop & en(对于
Group)stop是对除
RAM以外所有操作的暂停;en是根据地址译码出的使能信号。对于
Group而言,这两个信号起的作用并无差异,而综合全过程来看,真正的enable信号是将二者并起来的结果。而对于组内输出的hit信号,不应该加上stop信号,否则没有输出。因为只有hit变为1,stop才可以变为0,加上stop后相当于锁住了。
三、测试
不建议面向评测机debug,可以把自己搭建的Cache放入单周期CPU里替换原本的RAM,然后把Stop信号取反接到PC寄存器的使能上。之后添加一系列存取指令,可通过观察读取指令输出的数据是否正确、组的划分是否正确、组内通过LRU分配的行是否正确、块内的四条线是否选择正确等进行debug。
具体的测试数据可参看这位大佬给的数据:https://blog.csdn.net/u012928469/article/details/121723341

 浙公网安备 33010602011771号
浙公网安备 33010602011771号