iterrows效率测试
%%timeit
def compare(A, B):
x = A[0]
out = []
for a,b in zip(A,B):
if b>x:
out.append(True)
x = a
else:
out.append(False)
return out
df['compare'] = compare(df['A'], df['B'])
#73.2 µs ± 570 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)%%timeit
a = df.iloc[0].A#改成a = df['A'][0]效率并没提高
b = []
for idx, row in df.iterrows():
if row.B > a:
a = row.A
b.append(True)
else:
b.append(False)
df['Expected'] = b
#575 µs ± 7.42 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)进行更复杂的测试,差距还是很大
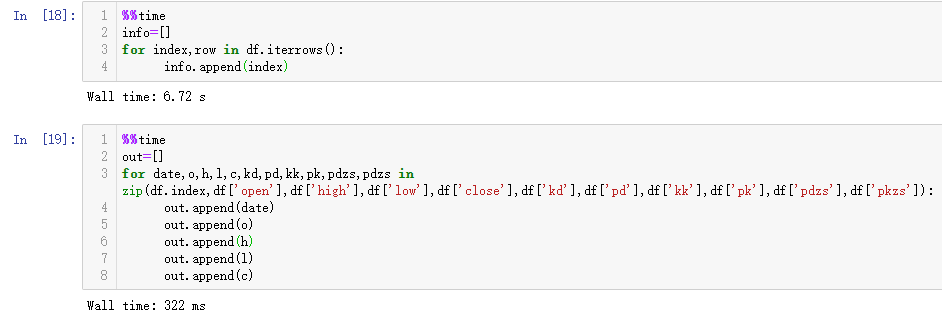
25万条数据的测试,iterrows内容很简单,速度依然没法跟zip比较

 浙公网安备 33010602011771号
浙公网安备 33010602011771号