
Java 如何重写对象的 equals 方法和 hashCode 方法
前言:Java 对象如果要比较是否相等,则需要重写 equals 方法,同时重写 hashCode 方法,而且 hashCode 方法里面使用质数 31。接下来看看各种为什么。
一、需求:
对比两个对象是否相等。对于下面的 User 对象,只需姓名和年龄相等则认为是同一个对象。
二、解决方案:
需要重写对象的 equals 方法和 hashCode 方法
package com.yule.user.entity; import org.springframework.util.StringUtils; /** * 用户实体 * * @author yule * @date 2018/8/6 21:51 */ public class User { private String id; private String name; private String age; public User(){ } public User(String id, String name, String age){ this.id = id; this.name = name; this.age = age; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAge() { return age; } public void setAge(String age) { this.age = age; } @Override public String toString() { return this.id + " " + this.name + " " + this.age; } @Override public boolean equals(Object obj) { if(this == obj){ return true;//地址相等 } if(obj == null){ return false;//非空性:对于任意非空引用x,x.equals(null)应该返回false。 } if(obj instanceof User){ User other = (User) obj; //需要比较的字段相等,则这两个对象相等 if(equalsStr(this.name, other.name) && equalsStr(this.age, other.age)){ return true; } } return false; } private boolean equalsStr(String str1, String str2){ if(StringUtils.isEmpty(str1) && StringUtils.isEmpty(str2)){ return true; } if(!StringUtils.isEmpty(str1) && str1.equals(str2)){ return true; } return false; } @Override public int hashCode() { int result = 17; result = 31 * result + (name == null ? 0 : name.hashCode()); result = 31 * result + (age == null ? 0 : age.hashCode()); return result; } }
三、测试
1、创建两个对象,名字和年龄相等则对象 equals 为 true。
@Test public void testEqualsObj(){ User user1 = new User("1", "xiaohua", "14"); User user2 = new User("2", "xiaohua", "14"); System.out.println((user1.equals(user2)));//打印为 true }
四、为什么要重写 equals 方法
因为不重写 equals 方法,执行 user1.equals(user2) 比较的就是两个对象的地址(即 user1 == user2),肯定是不相等的,见 Object 源码:
public boolean equals(Object obj) { return (this == obj); }
五、为什么要重写 hashCode 方法
既然比较两个对象是否相等,使用的是 equals 方法,那么只要重写了 equals 方法就好了,干嘛又要重写 hashCode 方法呢?
其实当 equals 方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。那这又是为什么呢?看看下面这个例子就懂了。
User 对象的 hashCode 方法如下,没有重写父类的 hashCode 方法
@Override public int hashCode() { return super.hashCode(); }
使用 hashSet
@Test public void testHashCodeObj(){ User user1 = new User("1", "xiaohua", "14"); User user2 = new User("2", "xiaohua", "14"); Set<User> userSet = new HashSet<>(); userSet.add(user1); userSet.add(user2); System.out.println(user1.equals(user2)); System.out.println(user1.hashCode() == user2.hashCode()); System.out.println(userSet); }
结果
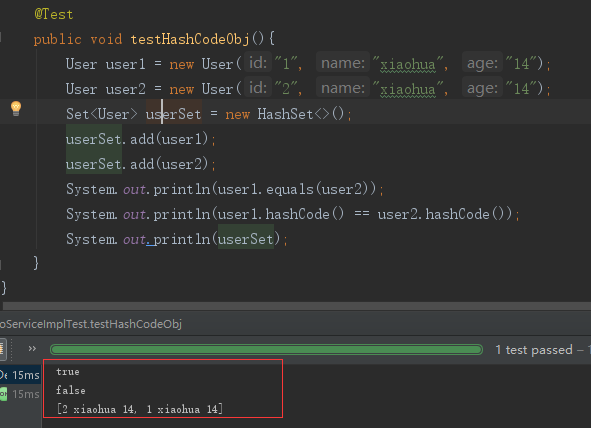
显然,这不是我们要的结果,我们是希望两个对象如果相等,那么在使用 hashSet 存储时也能认为这两个对象相等。
通过看 hashSet 的 add 方法能够得知 add 方法里面使用了对象的 hashCode 方法来判断,所以我们需要重写 hashCode 方法来达到我们想要的效果。
将 hashCode 方法重写后,执行上面结果为
@Override public int hashCode() { int result = 17; result = 31 * result + (name == null ? 0 : name.hashCode()); result = 31 * result + (age == null ? 0 : age.hashCode()); return result; }
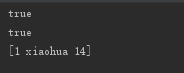
所以:hashCode 是用于散列数据的快速存取,如利用 HashSet/HashMap/Hashtable 类来存储数据时,都会根据存储对象的 hashCode 值来进行判断是否相同的。
六、如何重写 hashCode
生成一个 int 类型的变量 result,并且初始化一个值,比如17
对类中每一个重要字段,也就是影响对象的值的字段,也就是 equals 方法里有比较的字段,进行以下操作:a. 计算这个字段的值 filedHashValue = filed.hashCode(); b. 执行 result = 31 * result + filedHashValue;
七、为什么要使用 31
看一看 String hashCode 方法的源码:
/** * Returns a hash code for this string. The hash code for a * {@code String} object is computed as * <blockquote><pre> * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * </pre></blockquote> * using {@code int} arithmetic, where {@code s[i]} is the * <i>i</i>th character of the string, {@code n} is the length of * the string, and {@code ^} indicates exponentiation. * (The hash value of the empty string is zero.) * * @return a hash code value for this object. */ public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
可以从注释看出:空字符串的 hashCode 方法返回是 0。并且注释中也给了个公式,可以了解了解。
String 源码中也使用的 31,然后网上说有这两点原因:
原因一:更少的乘积结果冲突
31是质子数中一个“不大不小”的存在,如果你使用的是一个如2的较小质数,那么得出的乘积会在一个很小的范围,很容易造成哈希值的冲突。而如果选择一个100以上的质数,得出的哈希值会超出int的最大范围,这两种都不合适。而如果对超过 50,000 个英文单词(由两个不同版本的 Unix 字典合并而成)进行 hash code 运算,并使用常数 31, 33, 37, 39 和 41 作为乘子,每个常数算出的哈希值冲突数都小于7个(国外大神做的测试),那么这几个数就被作为生成hashCode值得备选乘数了。
所以从 31,33,37,39 等中间选择了 31 的原因看原因二。
原因二:31 可以被 JVM 优化
JVM里最有效的计算方式就是进行位运算了:
* 左移 << : 左边的最高位丢弃,右边补全0(把 << 左边的数据*2的移动次幂)。
* 右移 >> : 把>>左边的数据/2的移动次幂。
* 无符号右移 >>> : 无论最高位是0还是1,左边补齐0。
所以 : 31 * i = (i << 5) - i(左边 31*2=62,右边 2*2^5-2=62) - 两边相等,JVM就可以高效的进行计算啦。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号