MapReduce实践——专利引用关系数据集分析(WordCount与倒排索引的应用组合)
 统计某专利都被哪些其他专利引用过,被引用多少次
统计某专利都被哪些其他专利引用过,被引用多少次
数据源
美国专利文献数据
链接:https://pan.baidu.com/s/1CPnKXVoYR8LhZhwp1kIBxQ
提取码:yxh1
--来自百度网盘超级会员V1的分享

实验内容
专利被引列表(Citation data set倒排)
统计某专利都被哪些其他专利引用过。
• 最终输出键值对示例:
–key: cited专利号
–value: “citing专利号1, citing专利号2
此题是对倒排索引的应用,需要在倒排索引的代码基础上进行修改,从而实现目的
相比于之前很多文件的输入相比,此题输入文件单一,内部格式单一,在Map阶段需要进行调节,而后来的Reduce操作基本与不变,因此考虑Map函数的修改即可
现在的字符串是字符+','+字符型的因此需要将
字符串按','进行划分,划分后的前者即citing,后者即cited,存入存储器即可
因此关键部分代码为
Text citing = new Text();
Text cited = new Text();
StringTokenizer itr = new StringTokenizer(value.toString(),",");
for(;itr.hasMoreTokens();)
{
if(itr.hasMoreTokens())
citing.set(itr.nextToken());
if(itr.hasMoreTokens())
cited.set(itr.nextToken());
context.write(cited,citing);//将文件名存到容器
}
完整代码为📎Quote.java
执行结果为
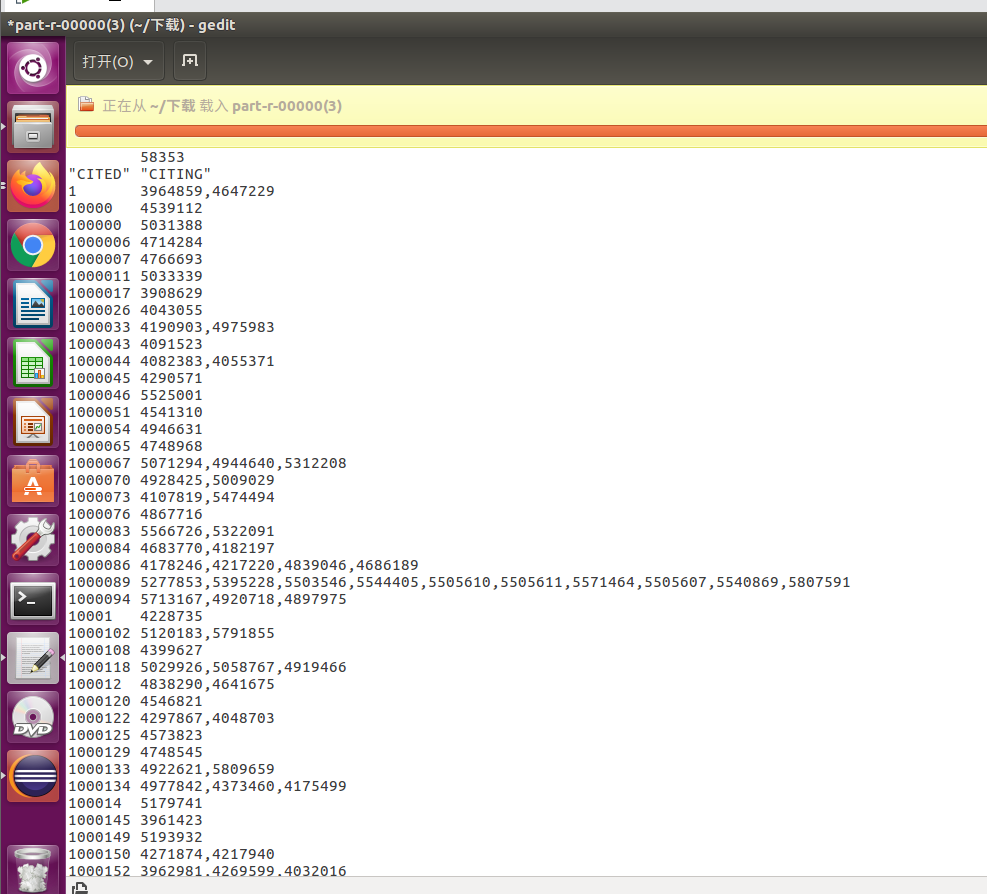
专利被引次数统计
统计某专利被其他专利引用的次数。
• 最终输出键值对示例:
–key: cited专利号
–value: 被引次数
此题是对WordCount的应用,需要在WordCount的代码基础上进行修改,从而实现目的
和上题考虑相同,考虑Map函数的修改即可
现在的字符串是字符+','+字符型的因此需要将字符串按','进行划分,划分后的前者即citing,后者即cited,将cited存入存储器,并计数即可
因此关键部分代码为
StringTokenizer itr = new StringTokenizer(value.toString(),",");
while (itr.hasMoreTokens()) {
if(itr.hasMoreTokens())
cited.set(itr.nextToken());
if(itr.hasMoreTokens())
cited.set(itr.nextToken());
context.write(cited, one);
}
完整代码为📎QuoteCount.java
执行结果为


 浙公网安备 33010602011771号
浙公网安备 33010602011771号