

一、选题的背景
选取中国租房信息这一选题基于对日益增长的租房需求的关注。随着城市化进程和人口流动加速,租房市场成为社会焦点。我们希望通过对来自不同房产信息平台的数据进行深入分析,探索租房市场的现状和特征。从社会角度,我们关心租房市场的供需状况,以及租房者和房东之间的关系。经济上,我们将关注租金水平、不同地区的价格差异,为租房者提供更全面的参考信息。技术方面,结合地理信息和周边设施数据,我们将尝试揭示租房决策背后的空间和环境因素。此外,通过对比北京、上海、深圳等城市,我们可以深入了解不同城市租房市场的异同。通过这一选题,我们旨在为租房者、房东和相关行业提供有益的洞察,为更智能、便捷的租房体验提供支持。
数据集的数据内容与数据特征分析:
1数据集包含房产信息,如地址、租金、房屋面积、朝向等。
2经过整合,还包含百度地图API获取的经纬度和周边设施信息。
3城市涵盖北京、上海、深圳,数据来源于房天下、58同城、赶集网。
4重要特征包括城市、区域、价格、面积、朝向、楼层、设施等。
二、大数据分析设计方案
数据分析的课程设计方案概述:
数据清洗和预处理:
缺失值处理、重复值去除、异常值处理。
1.探索性数据分析(EDA):
统计描述性信息,如平均租金、面积等。
不同城市、区域的租房分布情况。
房屋朝向和楼层的分布情况。
周边学校和医院数量的分布。
2.可视化分析:
利用折线图、散点图、箱线图等展示不同特征之间的关系。
绘制饼图、直方图等展示房屋朝向、楼层、设施的分布。
3.进阶分析:
分析周边设施对租金的影响。
聚类分析,识别不同类型的租房簇群。
技术难点:
数据可视化:利用Matplotlib、Seaborn等库绘制多样化的图表。
数据分析的深度和广度:通过多维度的分析,挖掘更深层次的关联和规律。
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
from pylab import mpl
import pandas as pd
mpl.rcParams['font.sans-serif'] = ['simHei']
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 查看数据的基本信息
print(df.info())
# 打印 DataFrame 的头部
print(df.head())
# 处理缺失值
print("处理缺失值前:")
print(df.isnull().sum())
# 填充朝向字段的缺失值
df['朝向'].fillna(df['朝向'].mode()[0], inplace=True)
print("\n处理缺失值后:")
print(df.isnull().sum())
# 处理异常值
z_scores = stats.zscore(df['价格'])
df = df[(z_scores < 3) & (z_scores > -3)]
# 处理重复值
print("\n处理重复值前:")
print(df.duplicated().sum())
df.drop_duplicates(inplace=True)
print("\n处理重复值后:")
print(df.duplicated().sum())数据清洗结果:
处理缺失值前:
link 0
租房网站名称 0
小区 0
详细地址 0
城市 0
区 0
价格 0
室 0
卫 0
厅 0
面积 0
朝向 0
所属楼层 0
总楼层 0
是否有阳台 0
信息发布人类型 0
是否有床 0
是否有衣柜 0
是否有沙发 0
是否有电视 0
是否有冰箱 0
是否有洗衣机 0
是否有空调 0
是否有热水器 0
是否有宽带 0
是否有燃气 0
是否有暖气 0
lng 0
lat 0
最近学校距离 0
周边学校个数 0
最近医院距离 0
周边医院个数 0
dtype: int64
处理缺失值后:
link 0
租房网站名称 0
小区 0
详细地址 0
城市 0
区 0
价格 0
室 0
卫 0
厅 0
面积 0
朝向 0
所属楼层 0
总楼层 0
是否有阳台 0
信息发布人类型 0
是否有床 0
是否有衣柜 0
是否有沙发 0
是否有电视 0
是否有冰箱 0
是否有洗衣机 0
是否有空调 0
是否有热水器 0
是否有宽带 0
是否有燃气 0
是否有暖气 0
lng 0
lat 0
最近学校距离 0
周边学校个数 0
最近医院距离 0
周边医院个数 0
dtype: int64
处理重复值前:
1339
处理重复值后:
03.数据可视化
1.分析租房信息数据集中各个城市的出租房屋数量分布情况。
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 统计各个城市的出租房屋数量
city_counts = df['城市'].value_counts()
# 绘制城市分布图
plt.figure(figsize=(20, 16))
city_counts.plot(kind='bar', color='skyblue', rot=0)
plt.title('出租房屋城市分布')
plt.xlabel('城市')
plt.ylabel('出租房屋数量')
plt.show()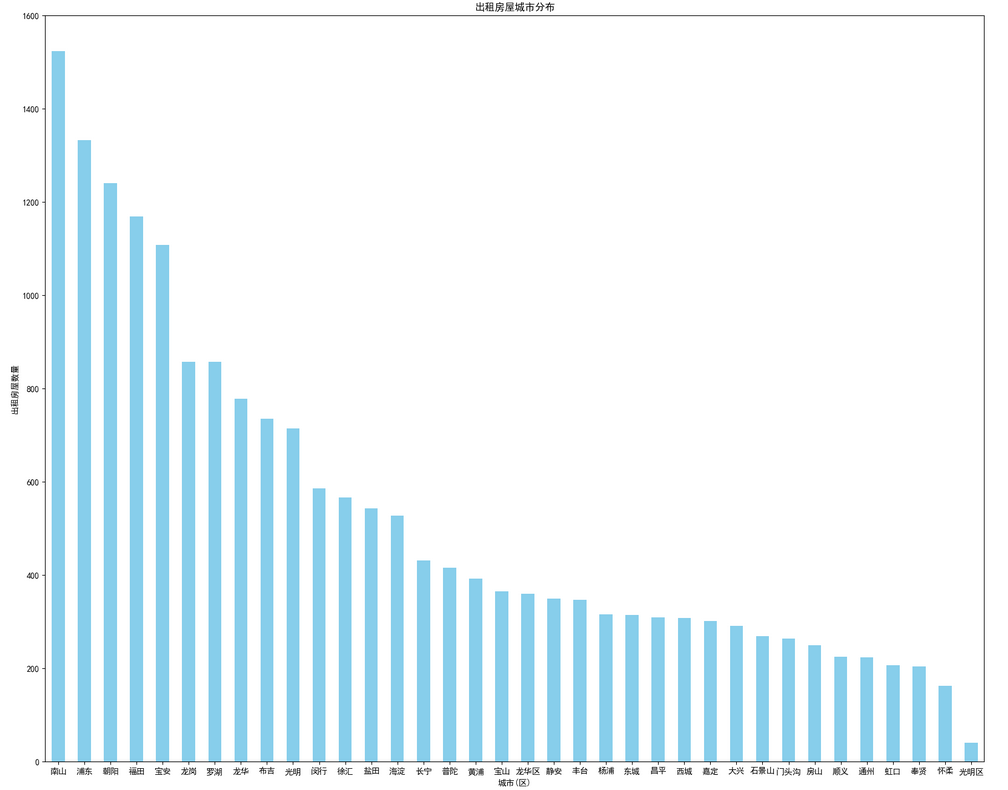
从上图可以看出南山的租房最多。
2.分析租房信息数据集中各个城市的各个区的出租房屋数量占比情况
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 处理缺失值
df.fillna(0, inplace=True)
# 统计各个区的出租房屋数量
area_counts = df.groupby(['城市', '区']).size().unstack()
# 绘制带有标题的饼图
fig, ax = plt.subplots(len(area_counts), figsize=(15, 15))
for i, (idx, row) in enumerate(area_counts.iterrows()):
# 避免出现除以零的情况
row_percentage = row / row.sum() * 100 if row.sum() != 0 else row
# 去除占比为0%的数据
row_percentage = row_percentage[row_percentage > 0]
ax[i].pie(row_percentage, labels=row_percentage.index, autopct='%1.1f%%', startangle=90)
ax[i].set_title(f"{idx}租房占比")
plt.tight_layout()
plt.show()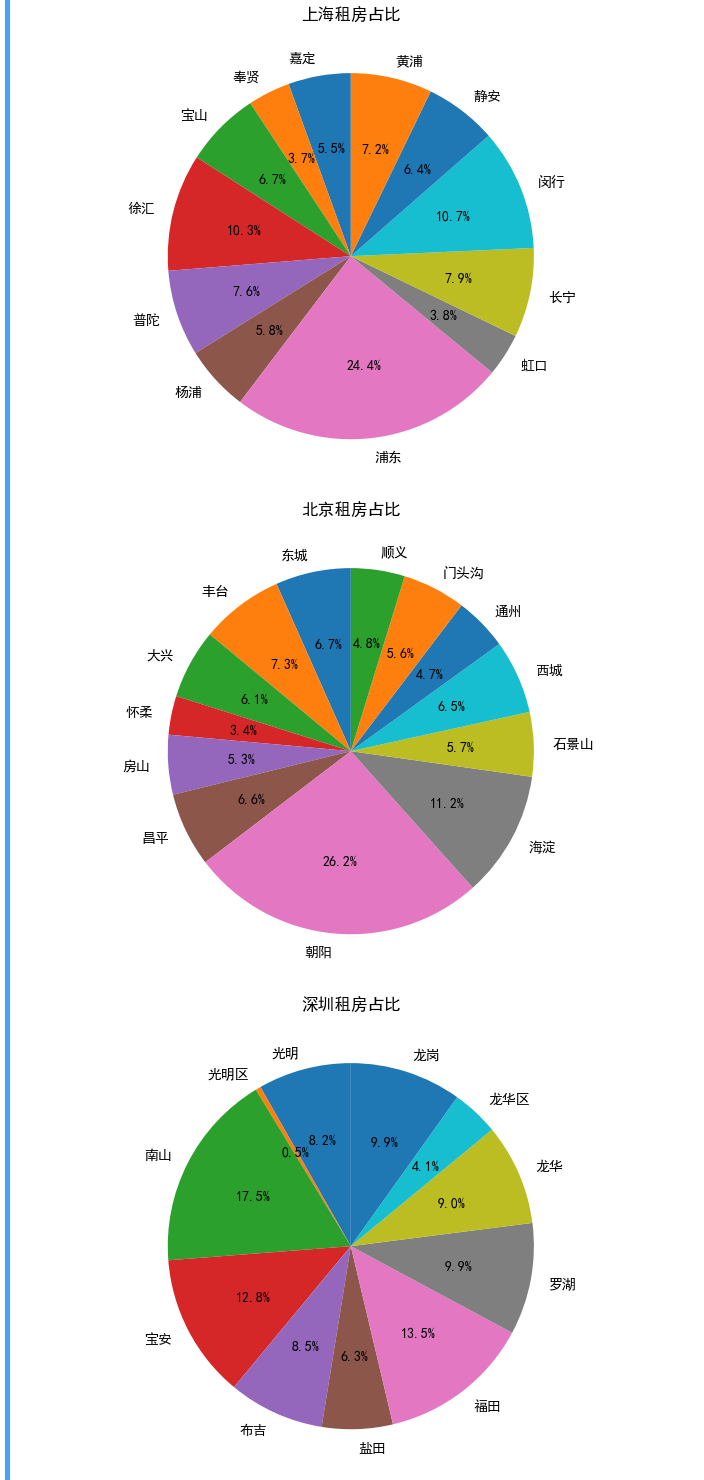
从上图可以很清楚的看到各个城市的各个区的出租房屋数量占比。
3.分析了租房信息数据集中房屋价格的分布情况
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 处理缺失值
df.fillna(0, inplace=True)
max_price = df['价格'].max()
print("最大价格:", max_price)
# 对价格进行分桶处理
price_bins = [0, 500, 1000, 1500, 2000, 2500, 3000, 5000, 10000, 20000, 50000, 100000,500000]
df['价格区间'] = pd.cut(df['价格'], bins=price_bins)
# 画出价格的直方图
plt.figure(figsize=(15, 8))
df['价格区间'].value_counts().sort_index().plot(kind='bar', color='skyblue', edgecolor='black',rot=0)
plt.title('租房价格分布')
plt.xlabel('价格区间')
plt.ylabel('数量')
plt.show()
# 画出价格的箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(x=df['价格区间'], y=df['价格'])
plt.title('租房价格分布箱线图')
plt.xlabel('价格区间')
plt.ylabel('价格')
plt.show() 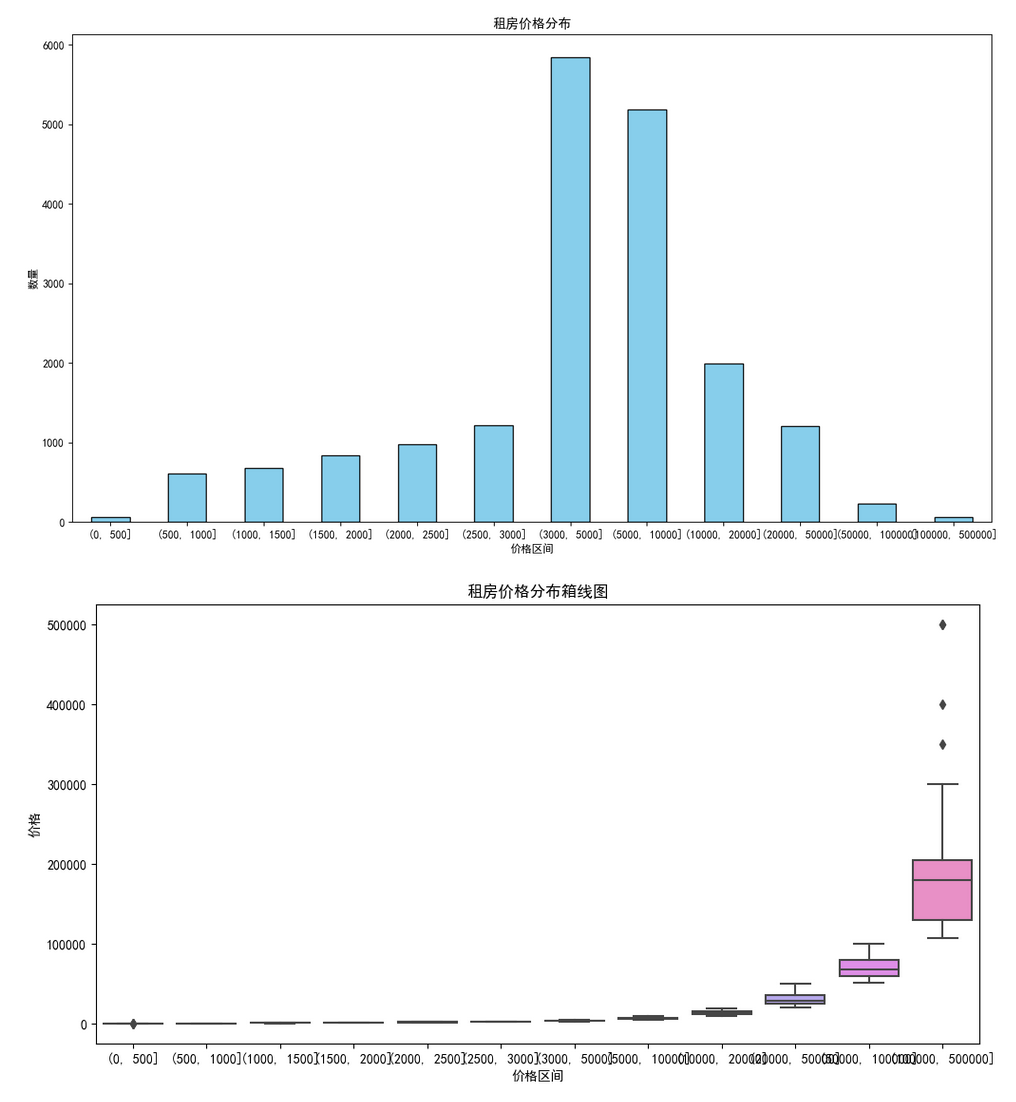
从上图可以很明显的看出价格很多都在3000-10000之间。
4.分析租房信息数据集中房屋面积的分布情况
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 获取 '面积' 列的最大值和最小值
max_area = df['面积'].max()
min_area = df['面积'].min()
# 去掉最大和最小值,获取 '面积' 列的数据
filtered_areas = df['面积'][(df['面积'] > min_area) & (df['面积'] < max_area)]
# 绘制直方图
plt.hist(filtered_areas, bins=100, color='blue', edgecolor='black')
# 添加标签和标题
plt.xlabel('房屋面积')
plt.ylabel('数量')
plt.title('房屋面积分布图(去掉最大和最小值)')
# 显示图形
plt.show()
# 绘制直方图
plt.hist(filtered_areas, bins=40, range=(0, 500), color='blue', edgecolor='black')
# 添加标签和标题
plt.xlabel('房屋面积')
plt.ylabel('数量')
plt.title('房屋面积分布图(0-500范围,去掉最大和最小值)')
# 设置 x 轴刻度间隔
plt.xticks(range(0, 500,50))
# 显示图形
plt.show()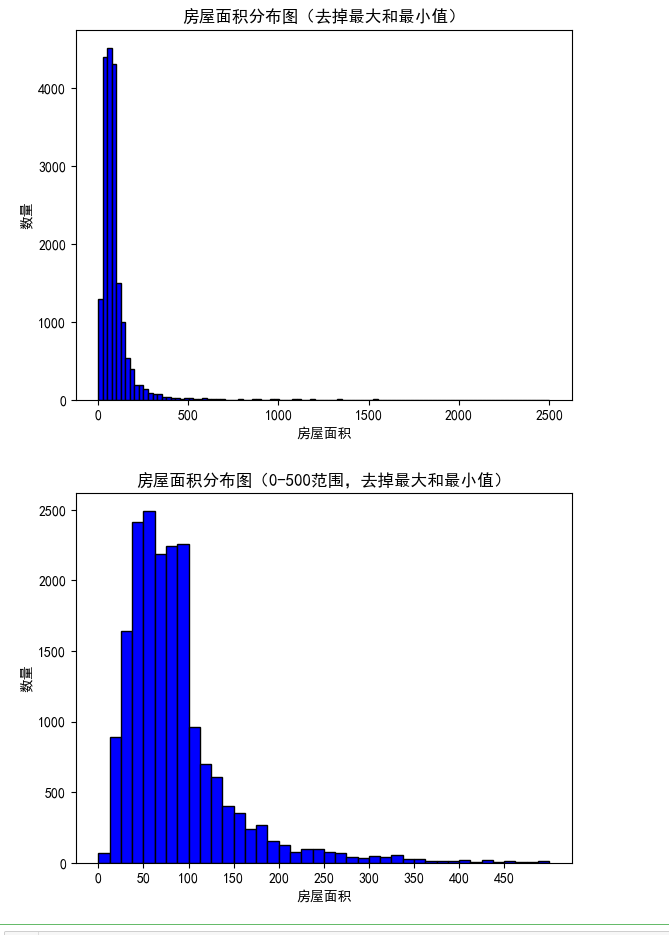
从上图可以很明显的看出房屋面积在0-150的租房最多
5.分析租房信息数据集中不同城市的平均租金
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 根据城市分组,计算平均租金
average_prices = df.groupby('城市')['价格'].mean().sort_values(ascending=False)
# 绘制条形图
average_prices.plot(kind='bar', color='skyblue')
# 添加标签和标题
plt.xlabel('城市')
plt.ylabel('平均租金')
plt.title('不同城市的平均租金比较')
# 旋转 x 轴标签,以防止重叠
plt.xticks(rotation=0, ha='center')
# 显示图形
plt.show()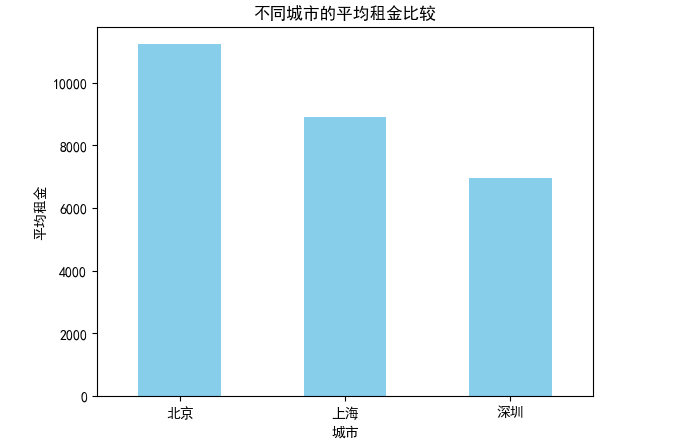
从上图看很直观的看出北京地区的平均租金是最高的。
6.分析租房信息数据集中房屋的房间数、洗手间数和厅的个数的分布情况
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 绘制房间数分布直方图
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.hist(df['室'], bins=range(1, 6), color='skyblue', edgecolor='black')
plt.xlabel('房间数')
plt.ylabel('数量')
plt.title('房间数分布图')
# 绘制洗手间数分布直方图
plt.subplot(1, 3, 2)
plt.hist(df['卫'], bins=range(1, 6), color='salmon', edgecolor='black')
plt.xlabel('洗手间数')
plt.ylabel('数量')
plt.title('洗手间数分布图')
# 绘制厅的个数分布直方图
plt.subplot(1, 3, 3)
plt.hist(df['厅'], bins=range(1, 6), color='lightgreen', edgecolor='black')
plt.xlabel('厅的个数')
plt.ylabel('数量')
plt.title('厅的个数分布图')
# 调整布局
plt.tight_layout()
# 显示图形
plt.show()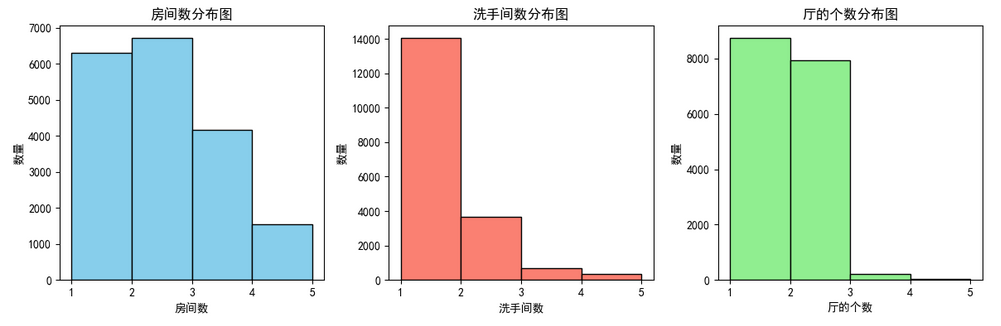
从上图可以很直观的看出房间数、洗手间数和厅的个数的分布情况,洗手间2间的比较少
7.分析租房信息数据集中不同城市的平均租房面积
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 根据城市分组,计算租房面积均值
average_area = df.groupby('城市')['面积'].mean().sort_values(ascending=False)
# 绘制柱状图
plt.figure(figsize=(10, 6))
plt.bar(average_area.index, average_area, color='skyblue')
# 添加标签和标题
plt.xlabel('城市')
plt.ylabel('平均租房面积')
plt.title('不同城市的租房面积均值比较')
# 旋转 x 轴标签,以防止重叠
plt.xticks(rotation=45, ha='right')
# 显示图形
plt.tight_layout()
plt.show()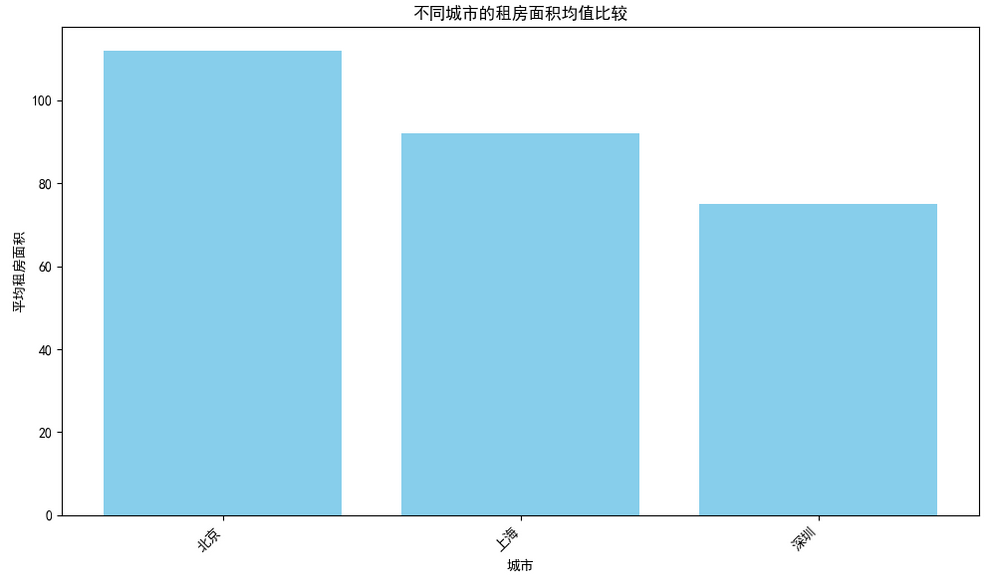
可以很直观的看出北京的平均租房面积最大。
8.分析租房信息数据集中各种设施的整体分布情况
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 获取设施列的数据
facilities_columns = ['是否有阳台', '是否有床', '是否有衣柜', '是否有沙发', '是否有电视', '是否有冰箱', '是否有洗衣机', '是否有空调', '是否有热水器', '是否有宽带', '是否有燃气', '是否有暖气']
# 计算每种设施的整体分布
facilities_counts = df[facilities_columns].apply(lambda col: col.value_counts(), axis=0).transpose()
# 创建画布和子图
fig, ax = plt.subplots(figsize=(12, 8))
# 绘制计数条形图
facilities_counts.plot(kind='bar', ax=ax, color=['#1f77b4', '#ff7f0e'], edgecolor='black')
# 设置图形属性
ax.set_title('房屋设施整体分布图', fontproperties=font)
ax.set_xlabel('房屋设施', fontproperties=font)
ax.set_ylabel('数量', fontproperties=font)
ax.legend(['有', '没有'], prop=font)
ax.set_xticklabels(facilities_counts.index, rotation=45, ha='right', fontproperties=font)
# 显示图形
plt.tight_layout()
plt.show()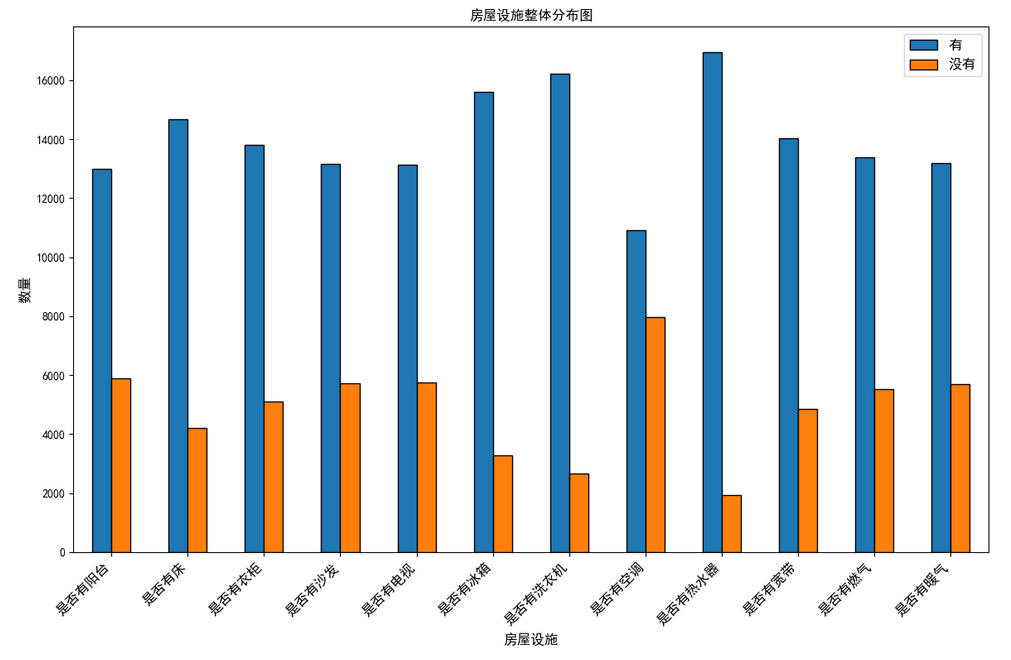
从上图可以很直观的看出各种设施有的数量比没有的多很多。
9.绘制深圳市房屋面积与价格之间的散点图
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 选择一个城市的数据(这里假设城市是深圳)
city_data = df[df['城市'] == '深圳']
# 抽样数据
sample_ratio = 0.5
sampled_data = city_data.sample(frac=sample_ratio, random_state=42)
# 创建散点图,调整透明度
plt.figure(figsize=(10, 6))
plt.scatter(sampled_data['面积'], sampled_data['价格'], alpha=0.5, color='blue', label='房屋数据')
plt.title('房屋面积与价格关系散点图', fontproperties=font)
plt.xlabel('面积(平方米)', fontproperties=font)
plt.ylabel('价格(元/月)', fontproperties=font)
# 设置 x 轴和 y 轴刻度范围和间隔
plt.xlim(0, 300)
plt.xticks(range(0, 301, 50))
plt.ylim(0, 8000)
plt.yticks(range(0, 9001, 1000))
# 显示图例
plt.legend(prop=font)
plt.show()
从上图可以很直观的看出在深圳面积 0-100平方米的租房最多。
10.分析深圳市不同地区的房屋面积与价格之间的关系
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 选择一个城市的数据(这里假设城市是深圳)
city_data = df[df['城市'] == '深圳']
# 创建不同地区的颜色映射
area_color_map = {'宝安': 'red', '南山': 'green', '福田': 'blue', '罗湖': 'purple', '龙岗': 'orange'}
# 创建散点图,每个地区使用不同颜色表示
plt.figure(figsize=(12, 8))
for area, color in area_color_map.items():
area_data = city_data[city_data['区'] == area]
plt.scatter(area_data['面积'], area_data['价格'], alpha=0.5, label=area, color=color)
plt.title('不同地区房屋面积与价格关系散点图', fontproperties=font)
plt.xlabel('面积(平方米)', fontproperties=font)
plt.ylabel('价格(元/月)', fontproperties=font)
plt.legend()
# 设置 x 轴和 y 轴刻度范围和间隔
plt.xlim(0, 300)
plt.xticks(range(0, 301, 50))
plt.ylim(0, 8000)
plt.yticks(range(0, 25000, 1000))
plt.legend(prop=font)
plt.show()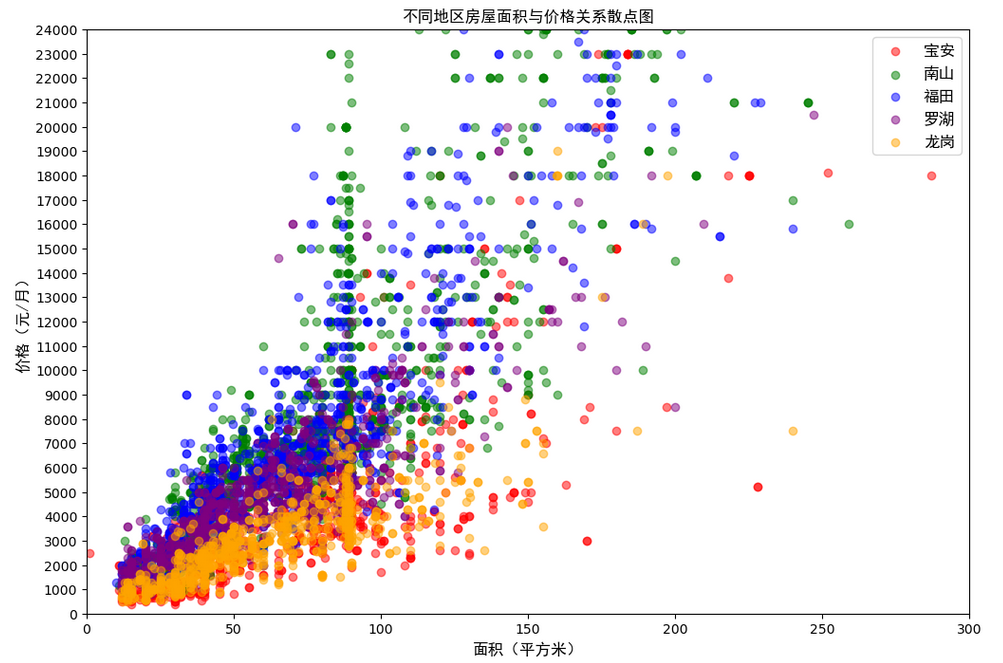
从上图可以很直观的看出在深圳各个地区面积 0-100平方米的租房最多。
11.分析房屋朝向和楼层的分布情况
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 创建画布和子图
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# 房屋朝向分布图(饼图)
orientation_counts = df['朝向'].value_counts()
ax1.axis('equal')
ax1.pie(orientation_counts, labels=orientation_counts.index, autopct='%1.1f%%', startangle=90, colors=['#ff9999', '#66b3ff', '#99ff99', '#ffcc99'])
ax1.set_title('房屋朝向分布', fontproperties=font)
# 房屋楼层分布图(直方图)
floor_counts = df['所属楼层'].value_counts().sort_index()
ax2.bar(floor_counts.index, floor_counts, color='skyblue')
ax2.set_title('房屋楼层分布', fontproperties=font)
ax2.set_xlabel('楼层', fontproperties=font)
ax2.set_ylabel('数量', fontproperties=font)
# 设置 x 轴刻度为整数
plt.xticks(range(int(floor_counts.index.min()), int(floor_counts.index.max()) + 1))
# 设置全局标题
fig.suptitle('房屋朝向和楼层分布图', fontproperties=font, fontsize=16)
# 自动调整布局,以防止标签重叠
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()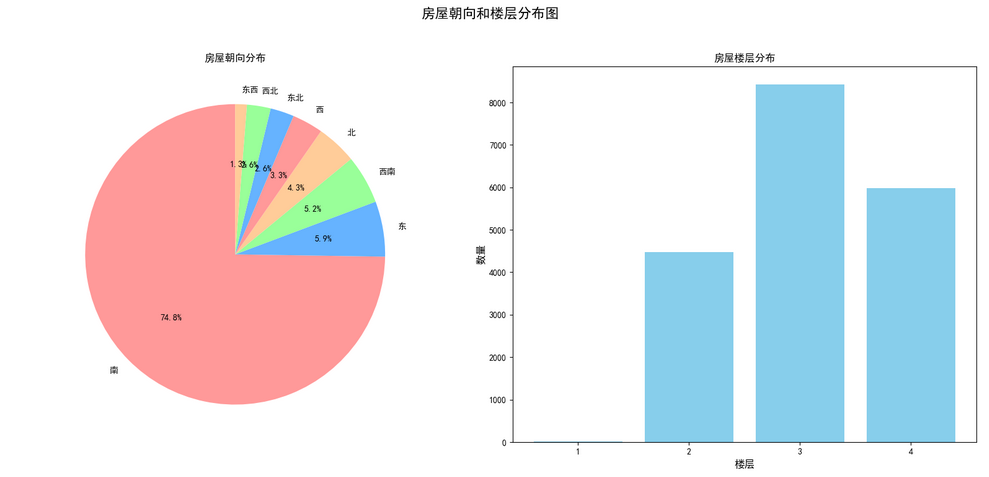
从上图可以很直观的看出朝向大部分租房都是向南的,楼层分布大部分都是在3层
12.分析周边学校数量和周边医院数量的分布情况
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 创建画布和子图
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))
# 周边学校数量分布图(柱状图)
school_counts = df['周边学校个数'].value_counts().sort_index()
ax1.bar(school_counts.index, school_counts, color='lightblue')
ax1.set_title('周边学校数量分布', fontproperties=font)
ax1.set_xlabel('学校个数', fontproperties=font)
ax1.set_ylabel('数量', fontproperties=font)
# 周边医院数量分布图(柱状图)
hospital_counts = df['周边医院个数'].value_counts().sort_index()
ax2.bar(hospital_counts.index, hospital_counts, color='lightgreen')
ax2.set_title('周边医院数量分布', fontproperties=font)
ax2.set_xlabel('医院个数', fontproperties=font)
ax2.set_ylabel('数量', fontproperties=font)
# 设置全局标题
fig.suptitle('周边学校和医院数量分布图', fontproperties=font, fontsize=16)
# 自动调整布局,以防止标签重叠
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()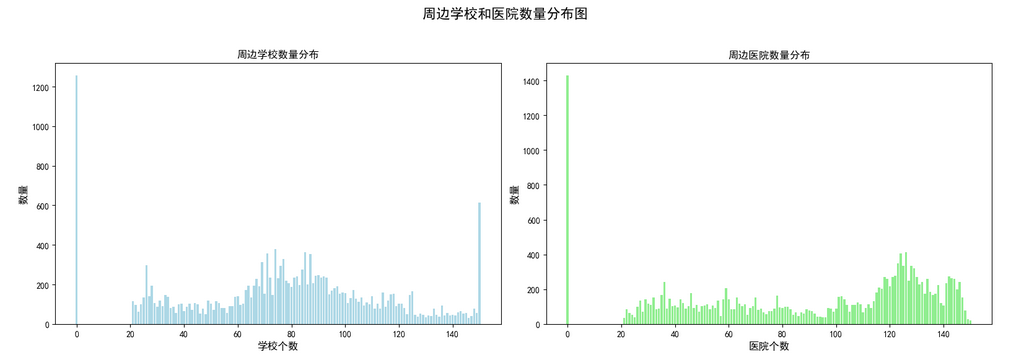
从上图可以很直观的看出学校和医院的分布情况。
13.分析使用线性回归模型分析了租房数据集中的两个特征('周边学校个数'和'周边医院个数')与目标变量('价格')之间的关系。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 读取数据集
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 选择特征和目标变量
features = df[['周边学校个数', '周边医院个数']]
target = df['价格']
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'Mean Absolute Error: {mae}')
print(f'R-squared: {r2}')
# 数据可视化
plt.figure(figsize=(12, 6))
sns.scatterplot(x='周边学校个数', y='价格', data=df, color='blue', label='实际值')
sns.scatterplot(x='周边学校个数', y=y_pred, data=pd.DataFrame({'周边学校个数': X_test['周边学校个数'], '价格': y_pred}), color='red', label='预测值')
plt.title('实际值 vs 预测值')
plt.xlabel('周边学校个数')
plt.ylabel('价格')
plt.legend()
plt.show()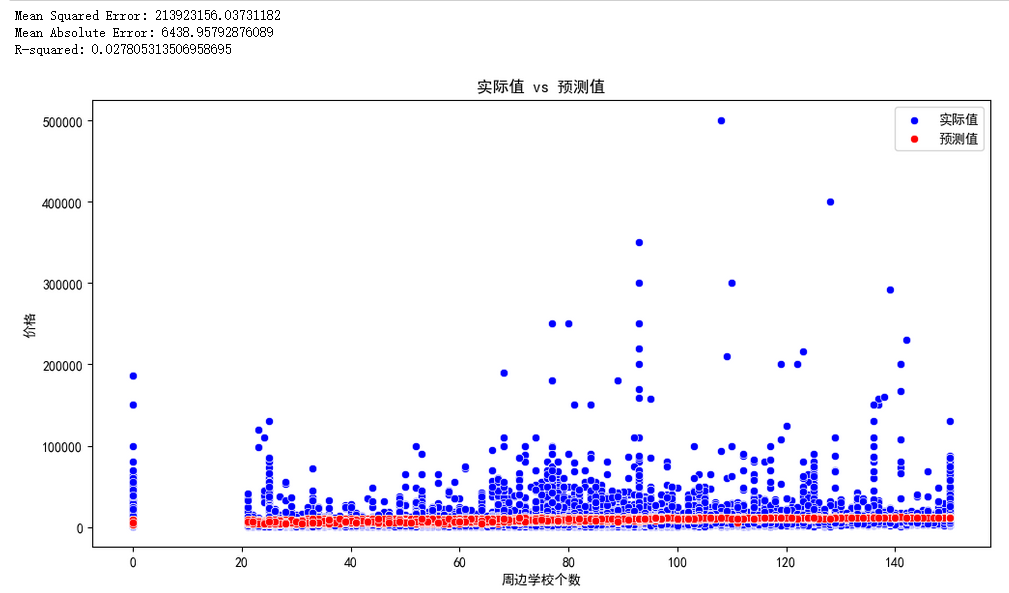
从上图可以很直观的看出预测和实际还是差距有点多的。
4附完整程序源代码(以及输出结果)
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
from pylab import mpl
import pandas as pd
mpl.rcParams['font.sans-serif'] = ['simHei']
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 查看数据的基本信息
print(df.info())
# 打印 DataFrame 的头部
print(df.head())
# 处理缺失值
print("处理缺失值前:")
print(df.isnull().sum())
# 填充朝向字段的缺失值
df['朝向'].fillna(df['朝向'].mode()[0], inplace=True)
print("\n处理缺失值后:")
print(df.isnull().sum())
# 处理异常值
z_scores = stats.zscore(df['价格'])
df = df[(z_scores < 3) & (z_scores > -3)]
# 处理重复值
print("\n处理重复值前:")
print(df.duplicated().sum())
df.drop_duplicates(inplace=True)
print("\n处理重复值后:")
print(df.duplicated().sum())
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 统计各个城市的出租房屋数量
city_counts = df['城市'].value_counts()
# 绘制城市分布图
plt.figure(figsize=(20, 16)) # 调整图表大小
city_counts.plot(kind='bar', color='skyblue', rot=0)
plt.title('出租房屋城市分布')
plt.xlabel('城市')
plt.ylabel('出租房屋数量')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 处理缺失值
df.fillna(0, inplace=True) # 将缺失值填充为0
# 统计各个区的出租房屋数量
area_counts = df.groupby(['城市', '区']).size().unstack()
# 绘制带有标题的饼图
fig, ax = plt.subplots(len(area_counts), figsize=(15, 15))
for i, (idx, row) in enumerate(area_counts.iterrows()):
# 避免出现除以零的情况
row_percentage = row / row.sum() * 100 if row.sum() != 0 else row
# 去除占比为0%的数据
row_percentage = row_percentage[row_percentage > 0]
ax[i].pie(row_percentage, labels=row_percentage.index, autopct='%1.1f%%', startangle=90)
ax[i].set_title(f"{idx}租房占比")
plt.tight_layout()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 处理缺失值
df.fillna(0, inplace=True) # 将缺失值填充为0
max_price = df['价格'].max()
print("最大价格:", max_price)
# 对价格进行分桶处理
price_bins = [0, 500, 1000, 1500, 2000, 2500, 3000, 5000, 10000, 20000, 50000, 100000,500000]
df['价格区间'] = pd.cut(df['价格'], bins=price_bins)
# 画出价格的直方图
plt.figure(figsize=(15, 8))
df['价格区间'].value_counts().sort_index().plot(kind='bar', color='skyblue', edgecolor='black',rot=0)
plt.title('租房价格分布')
plt.xlabel('价格区间')
plt.ylabel('数量')
plt.show()
# 画出价格的箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(x=df['价格区间'], y=df['价格'])
plt.title('租房价格分布箱线图')
plt.xlabel('价格区间')
plt.ylabel('价格')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 获取 '面积' 列的最大值和最小值
max_area = df['面积'].max()
min_area = df['面积'].min()
# 去掉最大和最小值,获取 '面积' 列的数据
filtered_areas = df['面积'][(df['面积'] > min_area) & (df['面积'] < max_area)]
# 绘制直方图
plt.hist(filtered_areas, bins=100, color='blue', edgecolor='black')
# 添加标签和标题
plt.xlabel('房屋面积')
plt.ylabel('数量')
plt.title('房屋面积分布图(去掉最大和最小值)')
# 显示图形
plt.show()
# 绘制直方图
plt.hist(filtered_areas, bins=40, range=(0, 500), color='blue', edgecolor='black')
# 添加标签和标题
plt.xlabel('房屋面积')
plt.ylabel('数量')
plt.title('房屋面积分布图(0-500范围,去掉最大和最小值)')
# 设置 x 轴刻度间隔
plt.xticks(range(0, 500,50))
# 显示图形
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 根据城市分组,计算平均租金
average_prices = df.groupby('城市')['价格'].mean().sort_values(ascending=False)
# 绘制条形图
average_prices.plot(kind='bar', color='skyblue')
# 添加标签和标题
plt.xlabel('城市')
plt.ylabel('平均租金')
plt.title('不同城市的平均租金比较')
# 旋转 x 轴标签,以防止重叠
plt.xticks(rotation=0, ha='center')
# 显示图形
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 绘制房间数分布直方图
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.hist(df['室'], bins=range(1, 6), color='skyblue', edgecolor='black')
plt.xlabel('房间数')
plt.ylabel('数量')
plt.title('房间数分布图')
# 绘制洗手间数分布直方图
plt.subplot(1, 3, 2)
plt.hist(df['卫'], bins=range(1, 6), color='salmon', edgecolor='black')
plt.xlabel('洗手间数')
plt.ylabel('数量')
plt.title('洗手间数分布图')
# 绘制厅的个数分布直方图
plt.subplot(1, 3, 3)
plt.hist(df['厅'], bins=range(1, 6), color='lightgreen', edgecolor='black')
plt.xlabel('厅的个数')
plt.ylabel('数量')
plt.title('厅的个数分布图')
# 调整布局
plt.tight_layout()
# 显示图形
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取租房信息的CSV文件
df = pd.read_csv("D:/pythonzuoye/China_Zufang_Message.csv")
# 根据城市分组,计算租房面积均值
average_area = df.groupby('城市')['面积'].mean().sort_values(ascending=False)
# 绘制柱状图
plt.figure(figsize=(10, 6))
plt.bar(average_area.index, average_area, color='skyblue')
# 添加标签和标题
plt.xlabel('城市')
plt.ylabel('平均租房面积')
plt.title('不同城市的租房面积均值比较')
# 旋转 x 轴标签,以防止重叠
plt.xticks(rotation=45, ha='right')
# 显示图形
plt.tight_layout()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 获取设施列的数据
facilities_columns = ['是否有阳台', '是否有床', '是否有衣柜', '是否有沙发', '是否有电视', '是否有冰箱', '是否有洗衣机', '是否有空调', '是否有热水器', '是否有宽带', '是否有燃气', '是否有暖气']
# 计算每种设施的整体分布
facilities_counts = df[facilities_columns].apply(lambda col: col.value_counts(), axis=0).transpose()
# 创建画布和子图
fig, ax = plt.subplots(figsize=(12, 8))
# 绘制计数条形图
facilities_counts.plot(kind='bar', ax=ax, color=['#1f77b4', '#ff7f0e'], edgecolor='black')
# 设置图形属性
ax.set_title('房屋设施整体分布图', fontproperties=font)
ax.set_xlabel('房屋设施', fontproperties=font)
ax.set_ylabel('数量', fontproperties=font)
ax.legend(['没有', '有'], prop=font)
ax.set_xticklabels(facilities_counts.index, rotation=45, ha='right', fontproperties=font)
# 显示图形
plt.tight_layout()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 指定中文字体
font = FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf', size=12)
# 选择一个城市的数据(这里假设城市是深圳)
city_data = df[df['城市'] == '深圳']
# 抽样数据(例如,只显示50%的数据点)
sample_ratio = 0.5
sampled_data = city_data.sample(frac=sample_ratio, random_state=42)
# 创建散点图,调整透明度
plt.figure(figsize=(10, 6))
plt.scatter(sampled_data['面积'], sampled_data['价格'], alpha=0.5, color='blue', label='房屋数据')
plt.title('房屋面积与价格关系散点图', fontproperties=font)
plt.xlabel('面积(平方米)', fontproperties=font)
plt.ylabel('价格(元/月)', fontproperties=font)
# 设置 x 轴和 y 轴刻度范围和间隔
plt.xlim(0, 300)
plt.xticks(range(0, 301, 50))
plt.ylim(0, 8000)
plt.yticks(range(0, 9001, 1000))
# 显示图例
plt.legend(prop=font)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 选择一个城市的数据(这里假设城市是深圳)
city_data = df[df['城市'] == '深圳']
# 创建不同地区的颜色映射
area_color_map = {'宝安': 'red', '南山': 'green', '福田': 'blue', '罗湖': 'purple', '龙岗': 'orange'}
# 创建散点图,每个地区使用不同颜色表示
plt.figure(figsize=(12, 8))
for area, color in area_color_map.items():
area_data = city_data[city_data['区'] == area]
plt.scatter(area_data['面积'], area_data['价格'], alpha=0.5, label=area, color=color)
plt.title('不同地区房屋面积与价格关系散点图', fontproperties=font)
plt.xlabel('面积(平方米)', fontproperties=font)
plt.ylabel('价格(元/月)', fontproperties=font)
plt.legend()
# 设置 x 轴和 y 轴刻度范围和间隔
plt.xlim(0, 300)
plt.xticks(range(0, 301, 50))
plt.ylim(0, 8000)
plt.yticks(range(0, 25000, 1000))
plt.legend(prop=font)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 创建画布和子图
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# 房屋朝向分布图(饼图)
orientation_counts = df['朝向'].value_counts()
ax1.axis('equal') # 使饼图的长宽比相等,达到放大的效果
ax1.pie(orientation_counts, labels=orientation_counts.index, autopct='%1.1f%%', startangle=90, colors=['#ff9999', '#66b3ff', '#99ff99', '#ffcc99'])
ax1.set_title('房屋朝向分布', fontproperties=font)
# 房屋楼层分布图(直方图)
floor_counts = df['所属楼层'].value_counts().sort_index()
ax2.bar(floor_counts.index, floor_counts, color='skyblue')
ax2.set_title('房屋楼层分布', fontproperties=font)
ax2.set_xlabel('楼层', fontproperties=font)
ax2.set_ylabel('数量', fontproperties=font)
# 设置 x 轴刻度为整数
plt.xticks(range(int(floor_counts.index.min()), int(floor_counts.index.max()) + 1))
# 设置全局标题
fig.suptitle('房屋朝向和楼层分布图', fontproperties=font, fontsize=16)
# 自动调整布局,以防止标签重叠
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据集文件
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 创建画布和子图
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))
# 周边学校数量分布图(柱状图)
school_counts = df['周边学校个数'].value_counts().sort_index()
ax1.bar(school_counts.index, school_counts, color='lightblue')
ax1.set_title('周边学校数量分布', fontproperties=font)
ax1.set_xlabel('学校个数', fontproperties=font)
ax1.set_ylabel('数量', fontproperties=font)
# 周边医院数量分布图(柱状图)
hospital_counts = df['周边医院个数'].value_counts().sort_index()
ax2.bar(hospital_counts.index, hospital_counts, color='lightgreen')
ax2.set_title('周边医院数量分布', fontproperties=font)
ax2.set_xlabel('医院个数', fontproperties=font)
ax2.set_ylabel('数量', fontproperties=font)
# 设置全局标题
fig.suptitle('周边学校和医院数量分布图', fontproperties=font, fontsize=16)
# 自动调整布局,以防止标签重叠
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 读取数据集
df = pd.read_csv('D:/pythonzuoye/China_Zufang_Message.csv')
# 选择特征和目标变量
features = df[['周边学校个数', '周边医院个数']]
target = df['价格']
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'Mean Absolute Error: {mae}')
print(f'R-squared: {r2}')
# 数据可视化
plt.figure(figsize=(12, 6))
sns.scatterplot(x='周边学校个数', y='价格', data=df, color='blue', label='实际值')
sns.scatterplot(x='周边学校个数', y=y_pred, data=pd.DataFrame({'周边学校个数': X_test['周边学校个数'], '价格': y_pred}), color='red', label='预测值')
plt.title('实际值 vs 预测值')
plt.xlabel('周边学校个数')
plt.ylabel('价格')
plt.legend()
plt.show()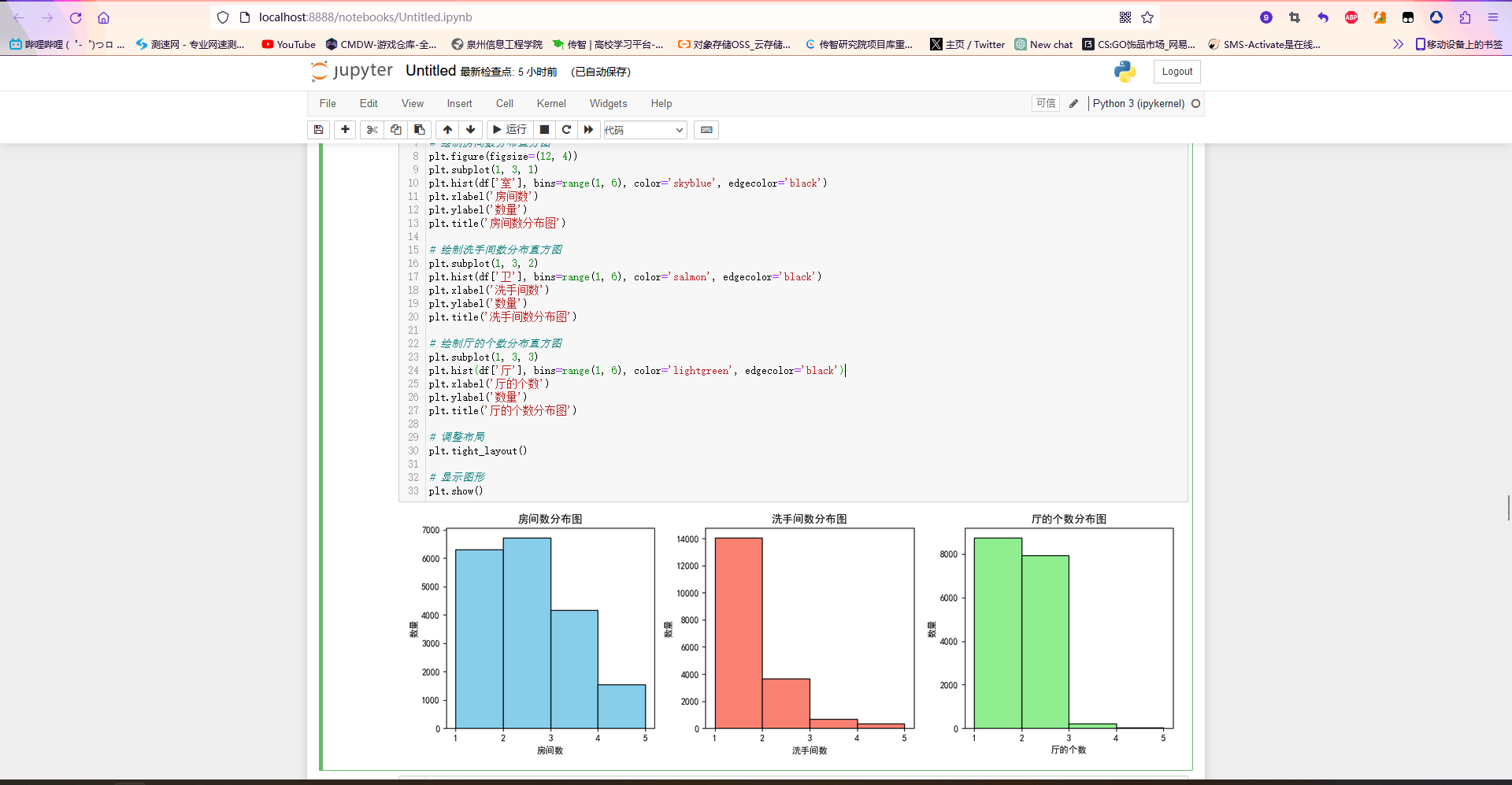
5.总结
在整个课程设计过程中,通过对中国租房信息数据集的分析和挖掘,可以得出以下结论:
1.有益的结论:
不同城市的租房价格存在显著差异,平均租金在城市之间有较大差距。房屋的朝向、楼层、周边学校和医院的数量等因素与租金之间存在一定的关系,
可以通过这些因素进行房价预测。通过聚类分析,可以将租房数据划分为不同的簇群,每个簇群具有一定的相似性,有助于了解租房市场的不同特点。
2.是否达到预期的目标:
预期目标包括对租房市场的整体了解、房价预测模型的建立和对周边设施的分析。这些目标在设计中都得到了初步实现。
3.个人收获:
通过本课程设计,学到了如何处理和清洗现实世界中的数据,进行特征工程和数据可视化。
深入理解了数据分析的流程,包括数据加载、清理、可视化、建模和评估等步骤。了解了房屋租赁市场的一些特征和规律。
4.改进建议:
在进一步分析中,可以考虑引入更多的特征,如房屋装修程度、小区环境等,以提高模型的预测性能。
在可视化方面,可以尝试更多类型的图表和图形,以更全面、直观地展示数据。
可以尝试不同的机器学习算法,比较它们的性能,并进一步优化模型。
总体而言,通过本课程设计,我对数据分析和机器学习在房地产领域的应用有了更深入的理解,同时也意识到在实际应用中,数据清洗和特征选择等环节对最终结果的影响非常重要。在未来的学习中,我将继续深入研究和实践,不断提高数据分析的水平

 浙公网安备 33010602011771号
浙公网安备 33010602011771号