
3.Spark设计与运行原理,基本操作
1.
Spark Core 是整个BDAS 生态系统的核心组件,是一个分布式大数据处理框架。
Spark Streaming 是一个对实时数据流进行高吞吐、高容错的流式处理系统,可以处理流数据。
Spark SQL 的前身是Shark,Shark 即Hive on Spark即数据查询及调用语言。
MLlib:是Spark 实现一些常见的机器学习算法和实用程序。
GraphX 是一个分布式图计算框架项目,用于图数据处理。

2.
|
Application |
Spark的应用程序,包含一个Driver program和若干Executor |
|
SparkContext |
Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor |
|
Driver Program |
运行Application的main()函数并且创建SparkContext |
|
Executor |
是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。 每个Application都会申请各自的Executor来处理任务 |
|
Cluster Manager |
在集群上获取资源的外部服务 (例如:Standalone、Mesos、Yarn) |
|
Worker Node |
集群中任何可以运行Application代码的节点,运行一个或多个Executor进程 |
|
Task |
运行在Executor上的工作单元 |
|
Job |
SparkContext提交的具体Action操作,常和Action对应 |
|
Stage |
每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet |
|
RDD |
是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类 |
|
DAGScheduler |
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
|
TaskScheduler |
将Taskset提交给Worker node集群运行并返回结果 |
|
Transformations |
是Spark API的一种类型,Transformation返回值还是一个RDD, 所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的 |
|
Action |
是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。 |
3.
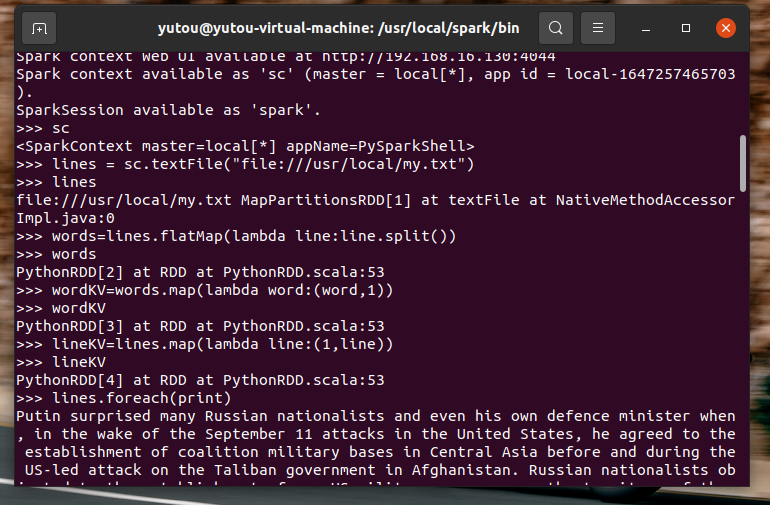
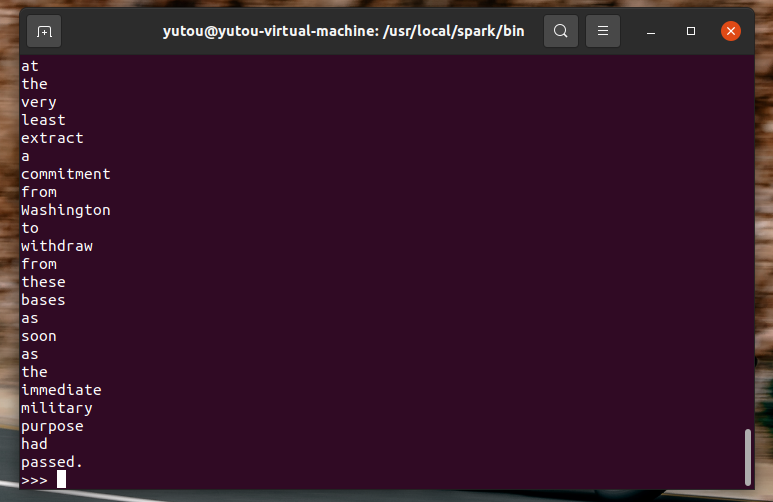
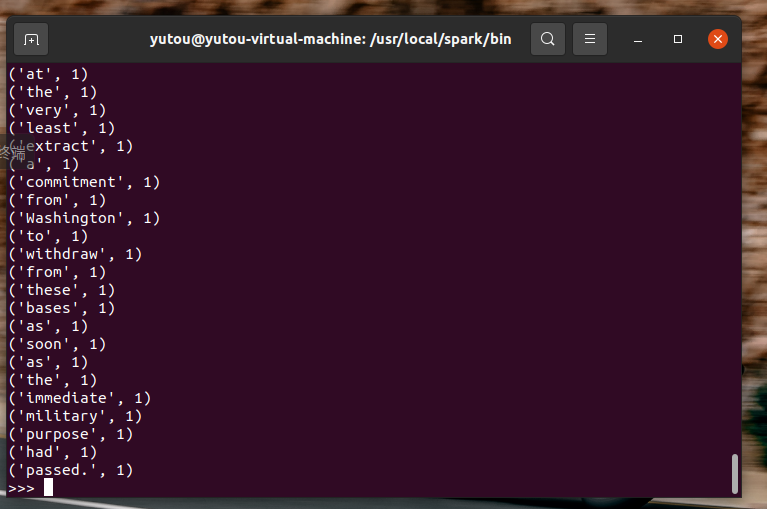
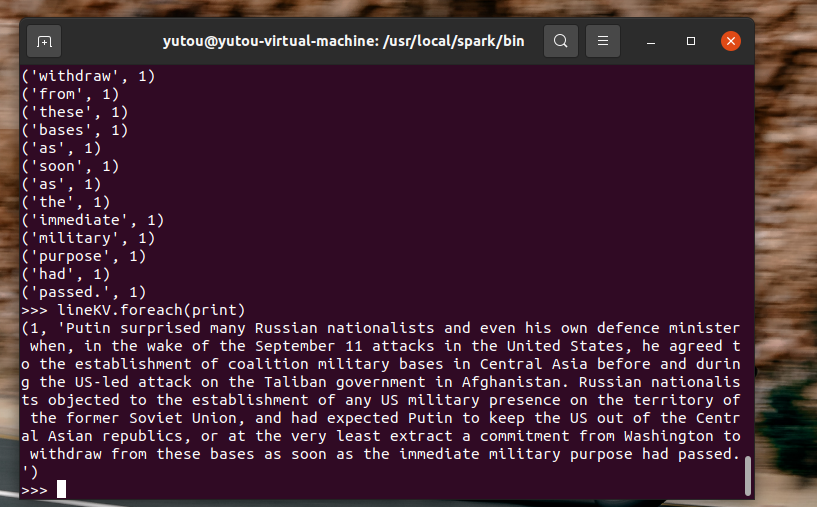

 浙公网安备 33010602011771号
浙公网安备 33010602011771号