


Hive On Spark保姆级教程
声明:
此博客参考了官网的配置方式,并结合笔者在实践网上部分帖子时的踩坑经历整理而成
这里贴上官方配置说明:
[官方]: https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started
大前提:
从Hive1.1开始支持使用Spark作为执行引擎,我们配置使用Spark On Yarn时,一定要注意
-
Hive版本与Spark版本的适配,不适配的需要自己重新编译使其适配
这里贴上官方推荐的对应版本Hive Version Spark Version master 2.3.0 3.0.x 2.3.0 2.3.x 2.0.0 2.2.x 1.6.0 2.1.x 1.6.0 2.0.x 1.5.0 1.2.x 1.3.1 1.1.x 1.2.0 笔者这里使用的是hive-3.1.2,按理说应该使用spark-2.3.0作为对应,但出于业务要求需使用spark-3.1.2,故重新编译hive-3.1.2源码使其适配spark-3.1.2
- Spark使用的jar包必须是没有集成Hive的
因spark包自带hive,其支持的版本与我们使用的版本冲突(如spark-3.1.2默认支持的hive版本为2.3.7),故我们只需spark自身即可,不需其自带的hive模块
两种方式去获得去hive的jar包- 从官网下载完整版的jar包,解压后将其jars目录下的hive相关jar包全部删掉(本文即使用此种方法)
- 重新编译spark,但不指定-Phive
注:网上部分帖子中所说使用“纯净版”,其实指的就是去hive版,而不是官方提供的without-hadoop版
下面进入正题
部署环境:CentOS 7.4 x86_64
Hive版本:3.1.2(重新编译过,修改了Spark版本和Scala版本,替换修改了部分源码,如有需要后续会出编译指导)
Spark版本:3.1.2(spark-3.1.2-bin-hadoop3.2.tgz,官网直接下载)
Hadoop版本:3.1.3(与Spark3.1.2自带hadoop版本3.2只差一个小版本,可直接使用,不用重新编译)
JDK版本:1.8.0_172
myql版本:5.7.32
步骤:
- 在机器上部署spark
解压
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
设置环境变量
echo '#SPARK_HOME' >> /etc/profile
echo 'export SPARK_HOME=/data/apps/spark-3.1.2-bin-hadoop3.2' >> /etc/profile
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> /etc/profile
source /etc/profile
准备去hive版本的spark-jars(!!!除了hive-storage-api-2.7.2.jar这个包!!!,如果用的spark是重新编译的且没有指定-Phive,这步可以省略)
cd $SPARK_HOME //进目录
mv jars/hive-storage-api-2.7.2.jar . //把这包先移出去
rm -rf jars/*hive* //删
mv hive-storage-api-2.7.2.jar jars/ //再移回去
将刚做好的spark-jars上传到hdfs
hdfs dfs -mkdir -p /spark-jars
hdfs dfs -put jars/* /spark-jars/
hdfs上创建spark-history存日志
hdfs dfs -mkdir -p /spark-history
- 在机器上部署hive
解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz
注:解压后的hive还需要一些额外的包放在lib下,比如因元数据库换为mysql需要一个mysql-connector-java-5.1.48.jar,比如为了处理hive-3.1.2和hadoop-3.1.3中guava包版本冲突的问题需要把原lib下的guava19删了放一个guava27,再比如为了处理slf4j包冲突问题将lib下面log4j-slf4j-impl-2.10.0.jar删喽,这里都不做详细说明(已经够详细了吧/doge);且这些问题都可以通过重新编译hive解决,不过要费一番功夫
改名(非必要)
mv apache-hive-3.1.2-bin hive-3.1.2
设置环境变量
echo '#HIVE_HOME' >> /etc/profile
echo 'export HIVE_HOME=/data/apps/hive-3.1.2' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
source /etc/profile
修改配置文件
- hive-site.xml
注:该文件首先需要从hive-default.xml.template复制一份出来,里面参数根据自己需要调整,这里只讲hive-on-spark需要修改或新增的参数
<!--Spark依赖位置,上面上传jar包的hdfs路径-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://bdp3install:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎,使用spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive连接spark-client超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>30000ms</value>
</property>
- hive-env.sh
注:该文件首先需要从hive-env.sh.template复制一份出来,里面参数根据自己需要调整,这里只讲hive-on-spark需要修改或新增的参数
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=${HADOOP_HOME:-/data/apps/hadoop-3.1.3}
export HIVE_HOME=${HIVE_HOME:-/data/apps/hive-3.1.2}
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=${HIVE_CONF_DIR:-/data/apps/hive-3.1.2/conf}
export METASTORE_PORT=9083
export HIVESERVER2_PORT=10000
- spark-default.conf
注:直接vim生成吧,不用从spark目录再拷过来,更多的参数可以参考最上面的官方地址
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bdp3install:8020/spark-history
spark.executor.memory 4g
spark.driver.memory 4g
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.cores 2
spark.yarn.driver.memoryOverhead 400m
- 启动hive
cd $HIVE_HOME
nohup bin/hive --service metastore &
等metastore启完(9083端口被监听了)
nohup bin/hive --service hiveserver2 &
等hiveserver2启完(10000端口被监听了)
4. 客户端连接测试
beeline
!connect jdbc:hive2://localhost:10000 hive ""
执行一些insert,同时观察下yarn,如果任务成功了,yarn上也有相应的application成功了,那就妥了


注:hive on spark任务是以每个spark session为单位提交到yarn的,每个yarn任务都有一次从hdfs加载spark-jars到容器中的过程,所以每次通过客户端执行命令时,第一次执行的速度会比较慢(因为加载jars,大约有200M),后续就很快了。
常见问题:
- java.lang.NoClassDefFoundError: org/apache/hadoop/hive/ql/exec/vector/ColumnVector
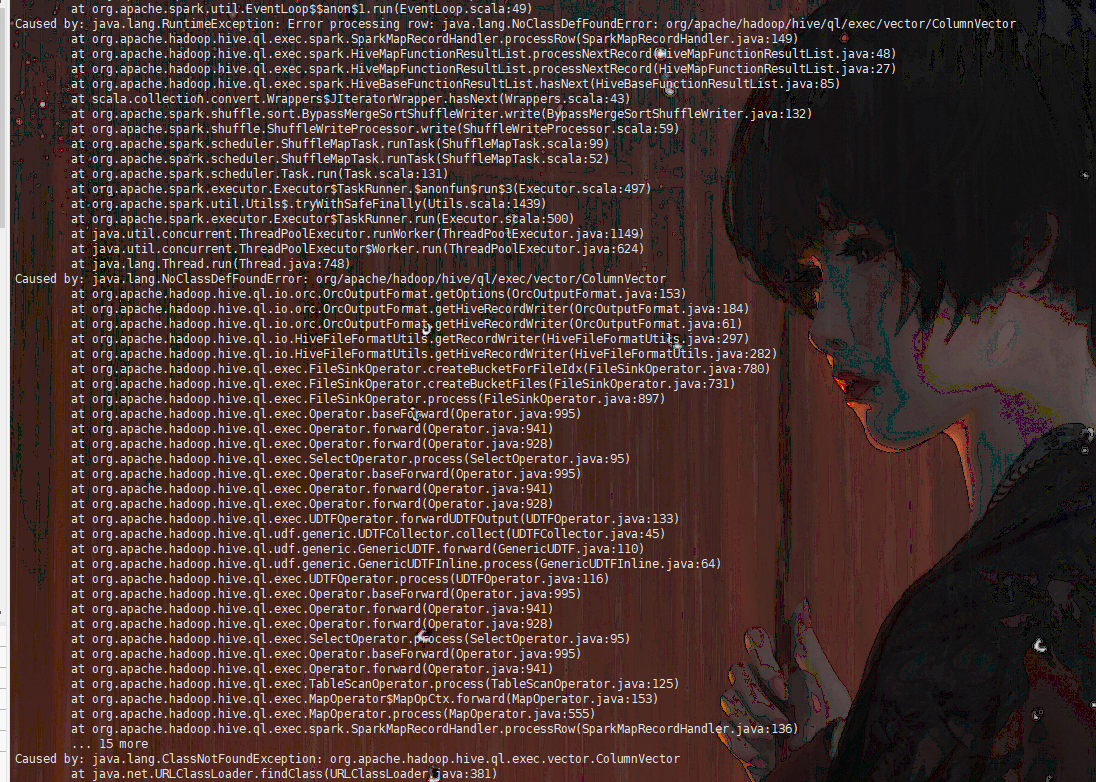
原因:spark-jars里少hive-storage-api-2.7.2.jar这个包
2. Could not load YARN classes. This copy of Spark may not have been compiled with YARN support.
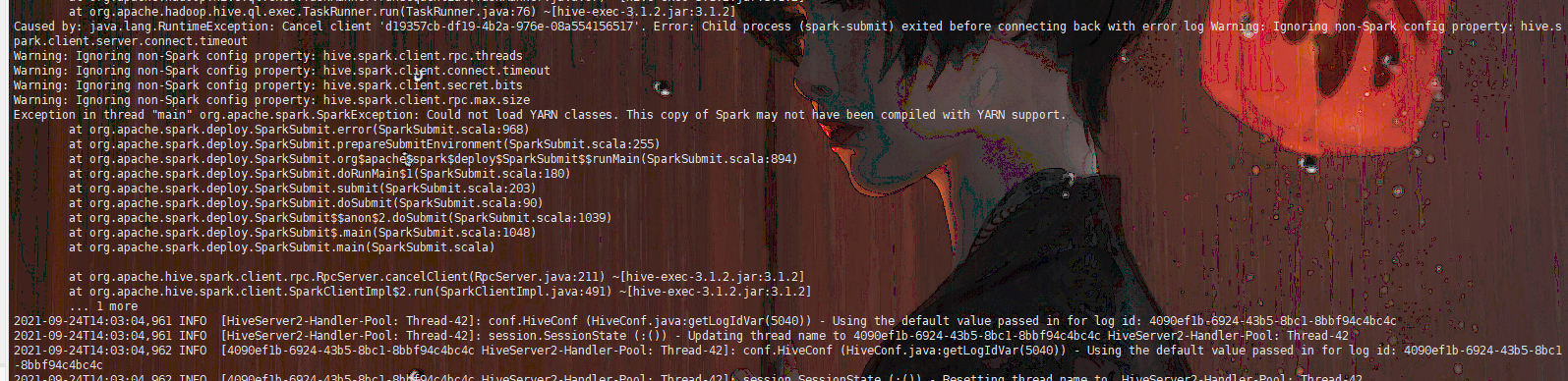
原因:hiveserver2所在机器没有部署spark或spark非完整版,或spark版本与hive版本不对应
3. 各种各样的ClassNotFound,NoClassDefFoundError
原因:spark-jars不完整,一定要是去hive的完整版jar包(一般都是少hadoop的包)
此文章首发于博客园,作者榆天紫夏,希望能对大家有所帮助,如有遗漏或问题欢迎补充指正。
本文来自博客园,作者:榆天紫夏,转载请注明原文链接:https://www.cnblogs.com/yutianzixia/p/15342773.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号