

K-means整理
K-means
1、K-means是非监督学习,解决的是聚类问题,k表示聚成k类;
KNN 是一种监督学习算法,解决的是分类问题,K表示K个邻居。
2、K-means的工作原理
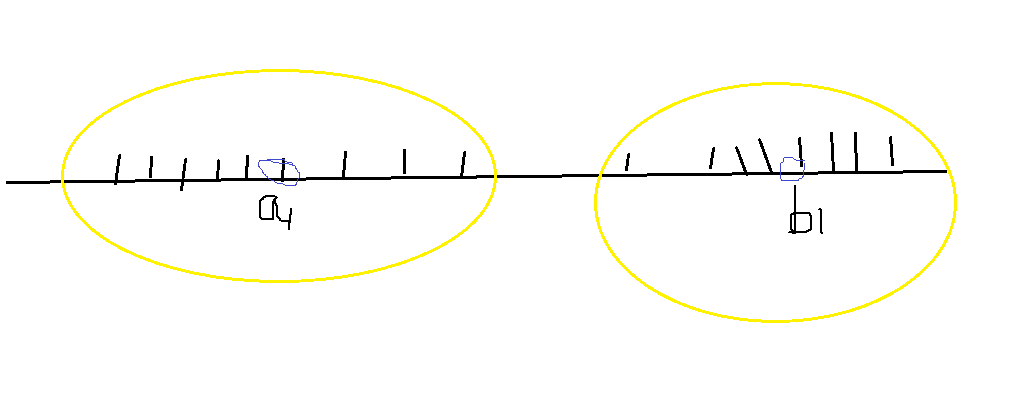
1)选取K个点作为初始类中心点,这些点一般是随机抽取的
2)将每个点分配到最近的类中心点,这样就形成了K个类,然后重新计算每个类的中心点(每个类新的中心点就是计算平均值)
假设a1,b1为初始质心,然后分别计算a1类和b1类中这些点的平均值为a2和b2作为新的质心
3)重复第二步,直到质心不变。
# coding: utf-8
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
import numpy as np
# 输入数据
data = pd.read_csv('data.csv', encoding='gbk')
train_x = data[["2019年国际排名","2018世界杯","2015亚洲杯"]]
df = pd.DataFrame(train_x)
kmeans = KMeans(n_clusters=3)
# 规范化到[0,1]空间
min_max_scaler=preprocessing.MinMaxScaler()
train_x=min_max_scaler.fit_transform(train_x)
# kmeans算法
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x)
# 合并聚类结果,插入到原数据中
result = pd.concat((data,pd.DataFrame(predict_y)),axis=1)
result.rename({0:u'聚类'},axis=1,inplace=True)
print(result)
代码------下面连接学习下
https://blog.csdn.net/qq_30377909/article/details/94596305
其他相关讲解如下
https://www.aboutyun.com//forum.php/?mod=viewthread&tid=18178&extra=page%3D1&page=1&
https://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号