


背景
JSON是一种轻量级的数据格式,结构灵活,支持嵌套,非常易于人的阅读和编写,而且主流的编程语言都提供相应的框架或类库支持与JSON数据的交互,因此大量的系统使用JSON作为日志存储格式。
使用Hive分析数据(均指文本)之前,首先需要为待分析的数据建立一张数据表,然后才可以使用Hive SQL分析这张数据表的数据。这就涉及到我们如何把一行文本数据映射为数据表的列,常规的方式有两种:
(1)分隔符

(2)正则表达式

但是Hive本身并没有针对JSON数据的解析提供原生的支持方式,仅提供了两个内建函数:get_json_object和json_tuple,用于解析某一列的JSON数据。究其原因主要是JSON格式的数据太过灵活,尤其是存在普通数据与JSON数据结合使用、多层嵌套、JSON对象和JSON数组对象结合使用的场景下,常规的数据解析方式变得捉襟见肘。这也是本文探讨的重点所在。
方案
1. 普通数据与JSON数据结合使用,其中JSON数据不存在多层嵌套、JSON对象和JSON数组对象结合使用的情况;

可以认为上述数据以“&_”分隔,data部分数据格式为JSON,针对此情况,我们选用正则的方式为其建立数据表,如下:
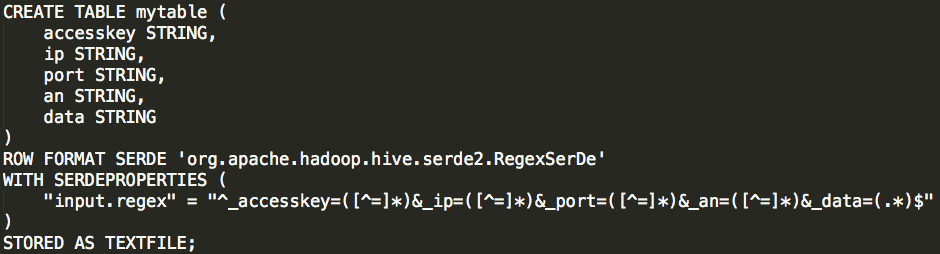
验证数据表解析数据是否正确,

可见三行数据都正确的被解析,但是我们没有办法直接将“data”的slice_id、status映射为列,我们只能通过get_json_object或json_tuple间接的分析数据。
因为get_json_object在解析多列数据的场景下存在性能问题,详情可参考https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-json_tuple,因此这里我们仅讨论json_tuple。
实际是我们想要的效果无非是将“data”部分的数据也映射为列,注意到“data”部分的数据全部为key/value的简单非嵌套形式,因此我们可以这么做:

通过Lateral View(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView)的方式我们借助json_tuple的方式得到了全部的数据列。很显然如果让我们的用户每次分析数据时都要面对如此复杂的SQL语句编写,这样的方式是很不友好的,可以通过创建视图的方式将这个过程隐藏。

视图mytable_view帮助我们隐藏了JSON数据与数据列的映射过程,用户分析数据时仅仅需要操纵一个标准列格式的数据视图即可。
2. JSON数组对象;
get_json_object和json_tuple仅仅能够处理JSON对象,而没有办法处理JSON数组对象,如果我们需要解析的是下述的数据:

Hive内建的功能是没有办法支持这样的数据解析的,因此我们需要自己扩展。
json_tuple能够处理普通的JSON对象,因此我们要做的只是扩展出一个json_array,可以将JSON数组对象转换为一个JSON对象数组即可。
注意:这里讨论的JSON对象、JSON数组对象、JSON对象数组元素均为JSON字符串。
2.1 创建json_array
扩展UDF需要继承GenericUDF,一般情况下需要重写两个方法:initialize、evaluate。
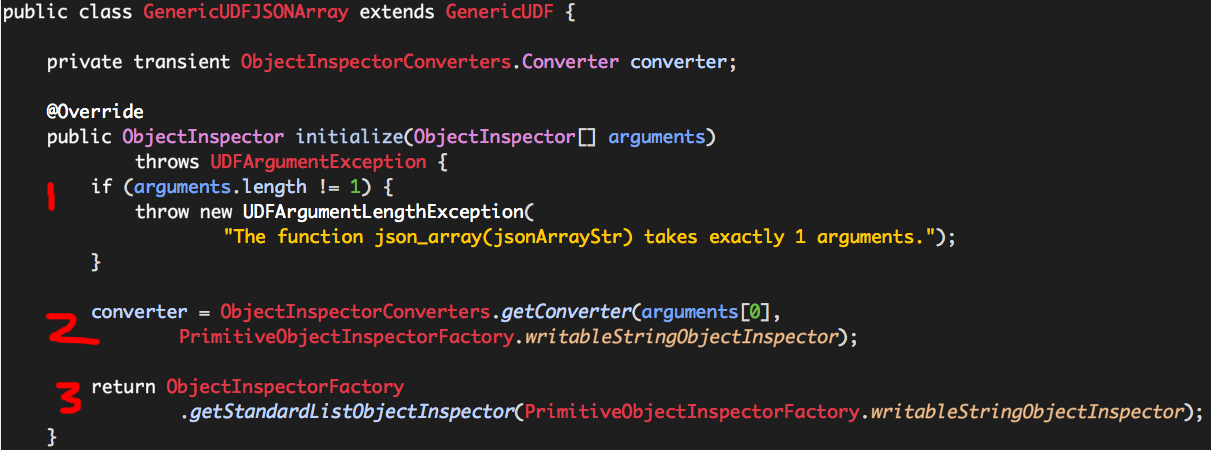
initialize核心逻辑如下:
(1)参数个数是否为1,这个参数即为JSON数组对象的字符串;
(2)定义参数的转换器,用于后期获取参数值;
(3)定义UDF返回结果类型:字符串数组;
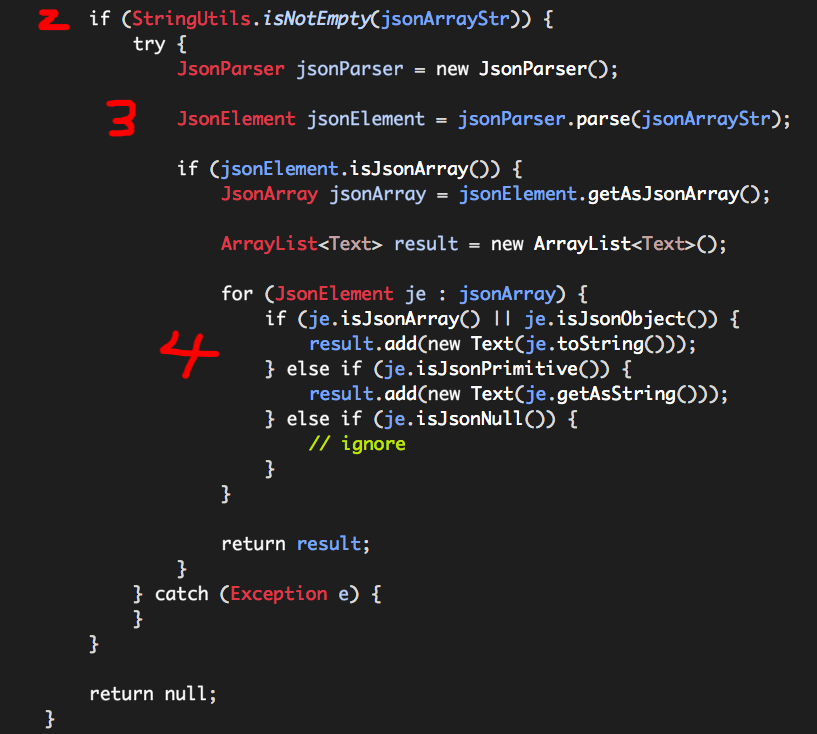
evaluate核心逻辑如下:
(1)判断参数个数是否为1,参数值是否为空,如果参数合法,则获取传入的JSON数组对象字符串jsonArrayStr;

(2)如果jsonArrayStr为空字符串,则返回null,否则继续下一步;
(3)使用Gson解析jsonArrayStr,如果解析失败,返回null;如果解析成功,需要作出如下判断:
a. 如果是JSON数组对象,则继续下一步;
b. 如果不是JSON数组对象,则返回null;
(4)将JSON数组对象的各个“元素”的字符串形式存入result并返回(需要注意不同的“元素”类型获取字符串的方式不同,此处我们忽略null)。
我们将该类的class文件以及Gson打包为一个独立的jar,存入HDFS,然后通过Hive创建Permanent Function,如下:

这样我们就可以开始在Hive SQL中使用函数json_array。
2.2 使用json_array
(1)建立数据表;
因为日志数据为JSON数组字符串,所以我们建立的数据表只能为一列,如下:


(2)使用json_array映射列;
每一个JSON数组对象包含两个JSON对象(可以数目不一样),每一个JSON对象包含如下属性:ts、id、log、ip,我们首先映射这些列,如下:

第一个Lateral View将JSON数组对象(字符串)转换为JSON对象数组(字符串),并通过explode将其转换为一个个JSON对象(字符串);
第二个Lateral View将JSON对象(字符串)“映射”为数据列。
我们还可以更进一步,利用同样的方法将“ip”列进行分解,如下:

我们还可以通过前面讲述过的创建视图的方法将上述映射过程隐藏,在此不再赘述。
总结
通过Hive内建函数json_tuple以及我们自己扩展的json_array,两者相互组合可以非常灵活的完成JSON数据的“映射”,并且可以通过创建视图的方式将“映射”过程隐藏。
同时我们也需要注意到,JSON本身是一种非常灵活的数据格式,但实际应用中也不能滥用,如:避免多层嵌套、数据结构不统一等,否则使用Hive分析JSON日志数据时会比较繁琐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号