
xpath
Xpath简介
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
简单来说我们通过Xpath可以获取XML中的指定元素和指定节点的值。在网络爬虫中我们通过会把爬虫获取的HTML数据转换成XML结构,然后通过XPath解析,获取我们想要的结果。
一.选取节点
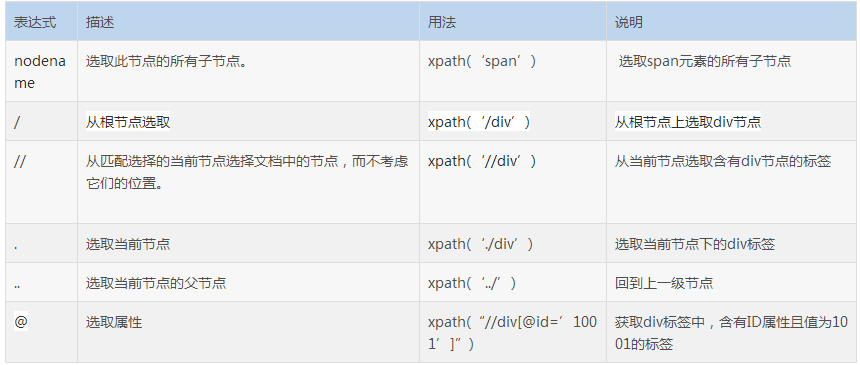
二.谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
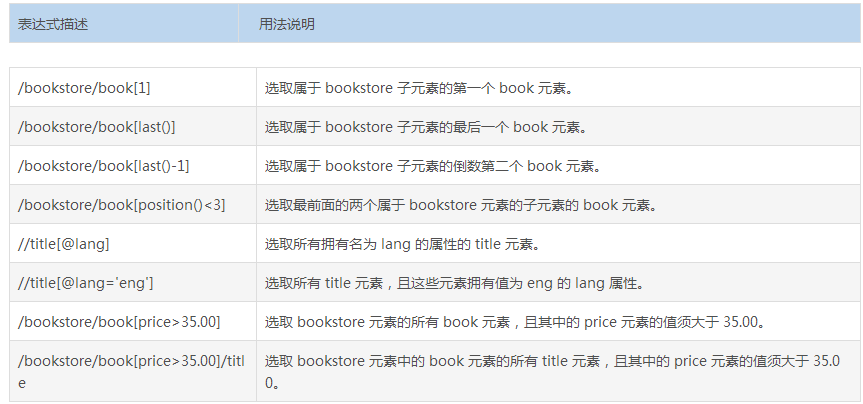
三. 通配符

四.多路径选择
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。

五.XPath 轴
轴可定义相对于当前节点的节点集。
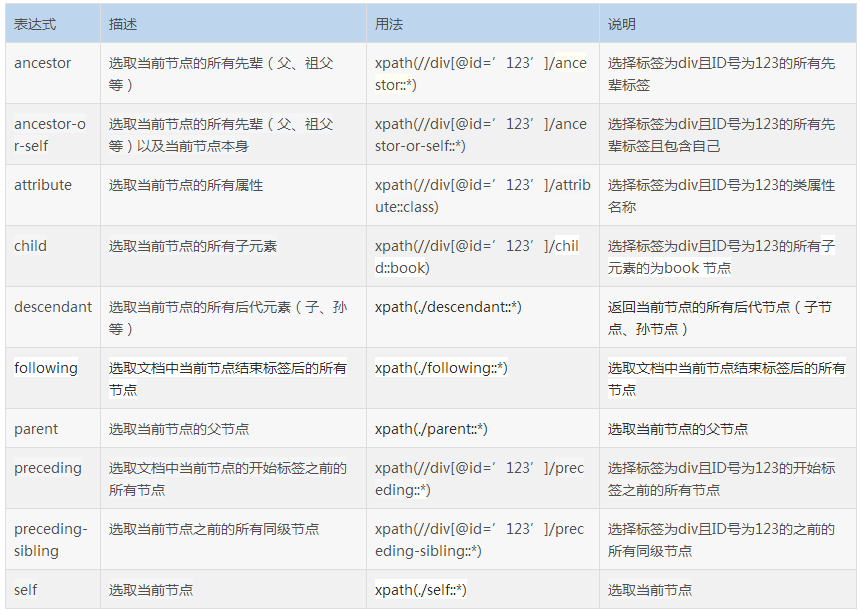
六.常用的功能函数
使用功能函数能够更好的进行模糊搜索

import requests
from lxml import etree
url = 'https://www.qiushibaike.com/'
rep = requests.get(url)
rep.encoding = rep.apparent_encoding
html = etree.HTML(rep.text)
res = html.xpath('//div[@class="content"]') # 获取所有class=content的div
res = html.xpath('//div[@class="content"]//span') # 获取所有class=content的div下的所有span标签
res = html.xpath('//div[@class="content"]/span') # 获取所有class=content的div下span标签(子级)
res = html.xpath('//div[@class="content"]')[0] # 获取第一个div对象
print(res.xpath('../@href')) # ../当前节点的父节点, 获取当前节点父节点的href属性
res = html.xpath('//div[@class="content"]//span')[0] # 获取第一个span对象
print(res.xpath('./parent::*')) # 获取当前节点的父节点
res = html.xpath('//div[@class="content"]')[0] # 获取第一个div对象
print(res.xpath('./span/text()')) # # ./当前节点,获取当前节点下的span节点
res = html.xpath('//div[@class="content"]/child::span') # 获取所有class=content的div的左右子元素且为span的节点
res = html.xpath('//div[@class="content"]/span/text()') # 获取文本
res = html.xpath('//div[@class="content"]/@class') # 获取属性
七.使用xpath采集糗事百科


from lxml import etree import requests import re import json li = [] for i in range(1, 10): if i == 1: URL = "https://www.qiushibaike.com/" else: URL = "https://www.qiushibaike.com/8hr/page/%s/" % str(i) response = requests.get(URL) response.encoding = 'UTF-8' html = etree.HTML(response.text) # 获取所有的段子 dz = html.xpath('//div[@id="content-left"]/div') for item in dz: dic = {} # 获取用户昵称 name = item.xpath('.//h2/text()') age = item.xpath('.//div[@class="articleGender womenIcon"]/text()') if not age: age = item.xpath('.//div[@class="articleGender manIcon"]/text()') else: age = None content = item.xpath('.//div[@class="content"]/span')[0] content = content.xpath('string(.)') img_src = item.xpath('.//div[@class="thumb"]//img/@src') # 格式化地址 if img_src: img_src = '%s' + img_src[0] src = img_src % 'https:' dic['src'] = src if age: dic['age'] = age[0].strip() dic['name'] = name[0].strip() dic['content'] = content li.append(dic) data = json.dumps(li, ensure_ascii=False, indent=4) with open('xpath_bk', 'wb') as f: f.write(bytes(data,encoding='utf-8'))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号