

Q-Learning
Q-Learning是RL算法:
-
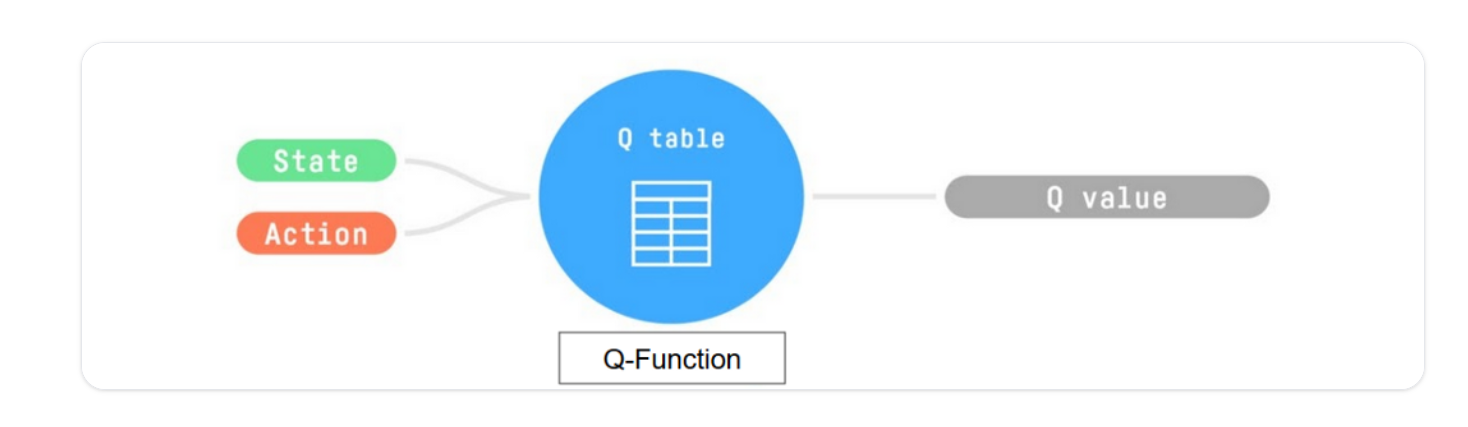
训练 Q 函数,这是一个操作-值函数,它包含作为内部存储器的 Q 表,其中包含所有状态-操作对值。
-
给定一个状态和动作,我们的 Q 函数将在其 Q 表中搜索相应的值。
Q-Learning伪代码:

step1:初始化Q-Table

step2:使用epsilon贪婪策略选择行动
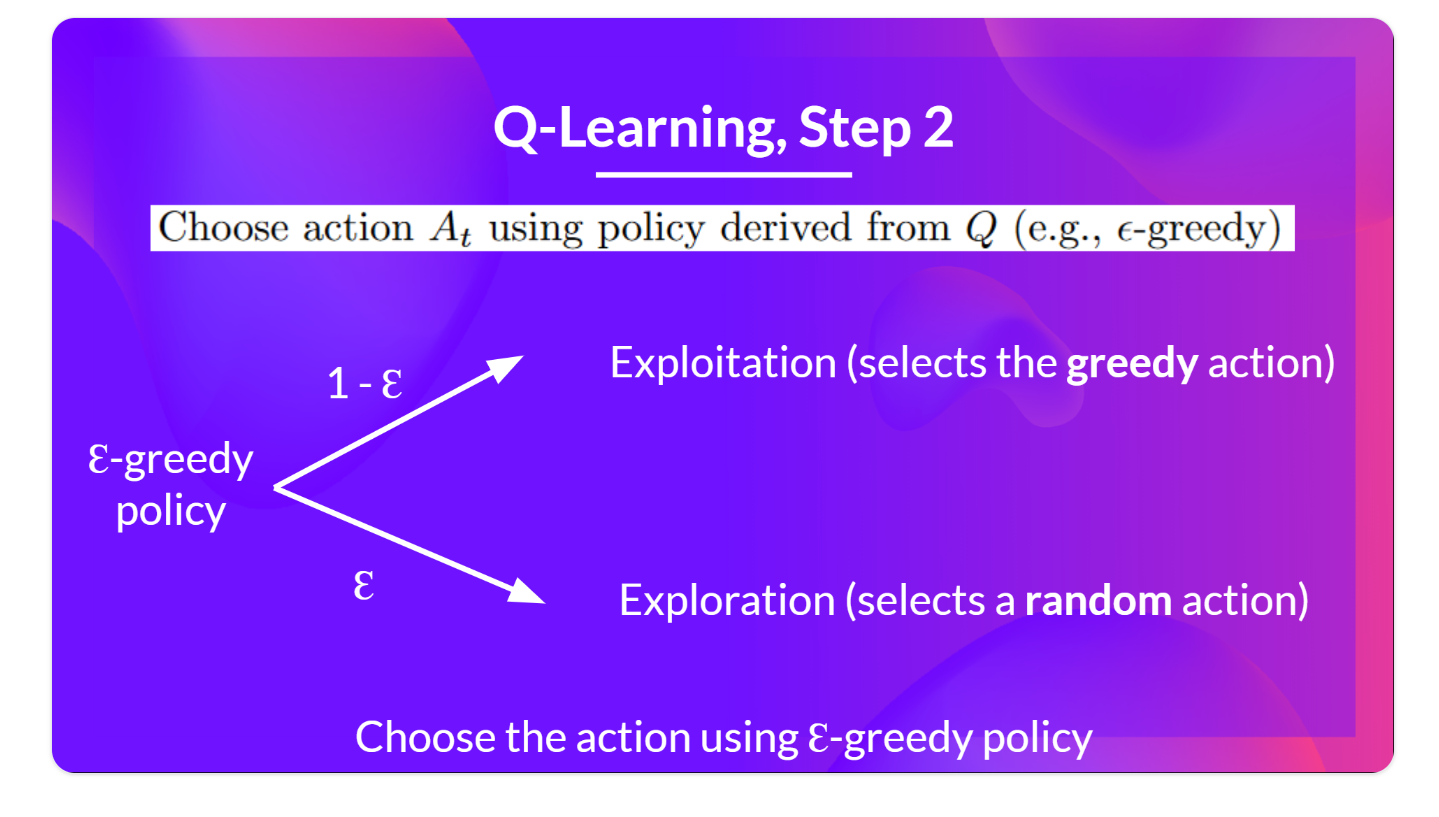
我们定义初始 epsilon ɛ = 1.0:
- 概率为 1 — ɛ :我们进行开发(exploitation )(也就是我们的代理选择具有最高状态-操作值的操作)。
- 概率 ɛ:我们进行探索(exploration )(尝试随机动作)。
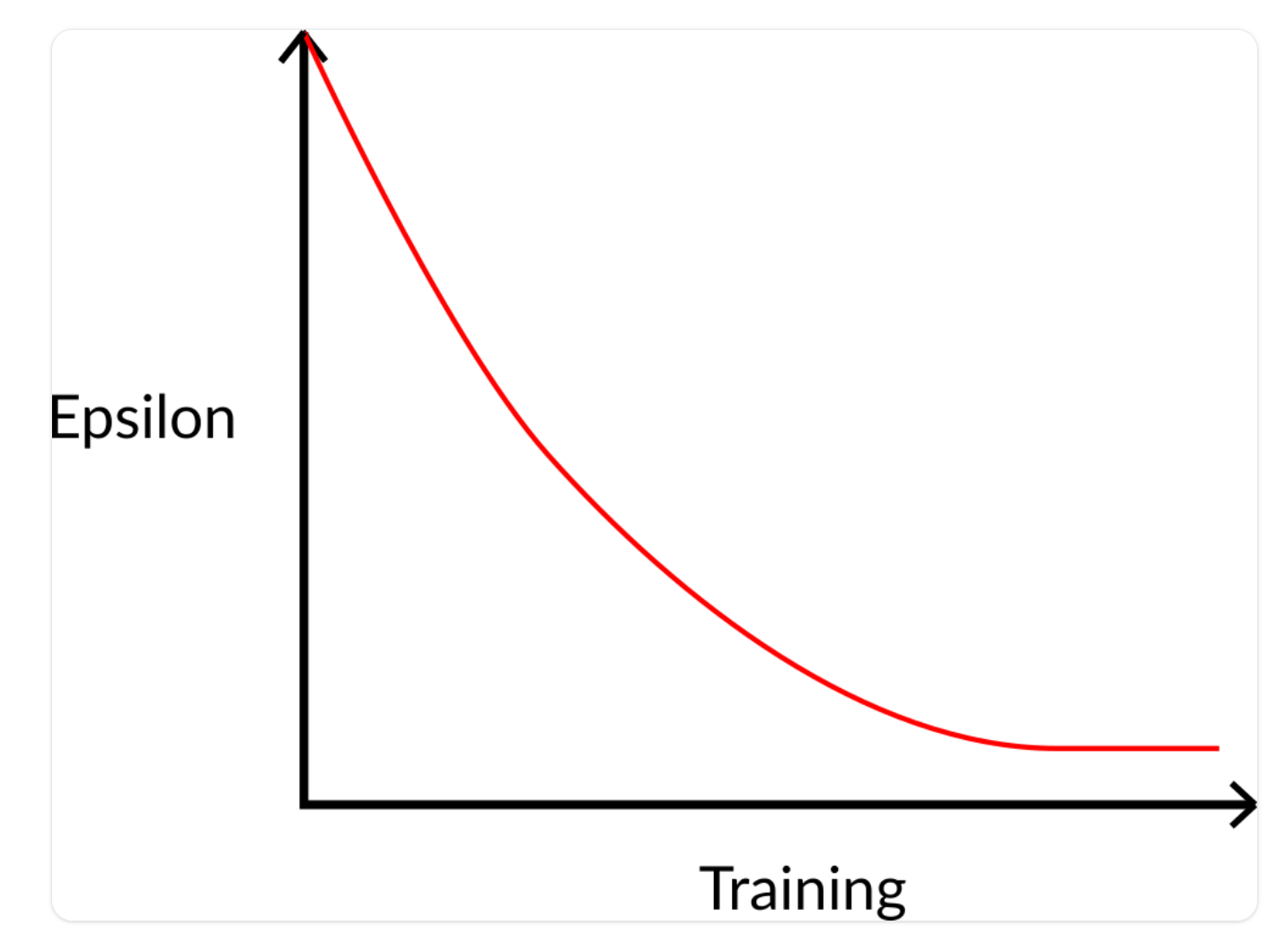
在训练开始时,由于 ɛ 非常高,所以进行探索(exploration )的概率会很大,所以大多数时候,我们会探索。但随着训练的进行,因此我们的Q表在估计中变得越来越好,我们逐渐降低ε值,因为我们需要的探索越来越少,更多的开发。
Step3: 执行操作At,获得奖励 Rt+1 和下一个状态 St+1

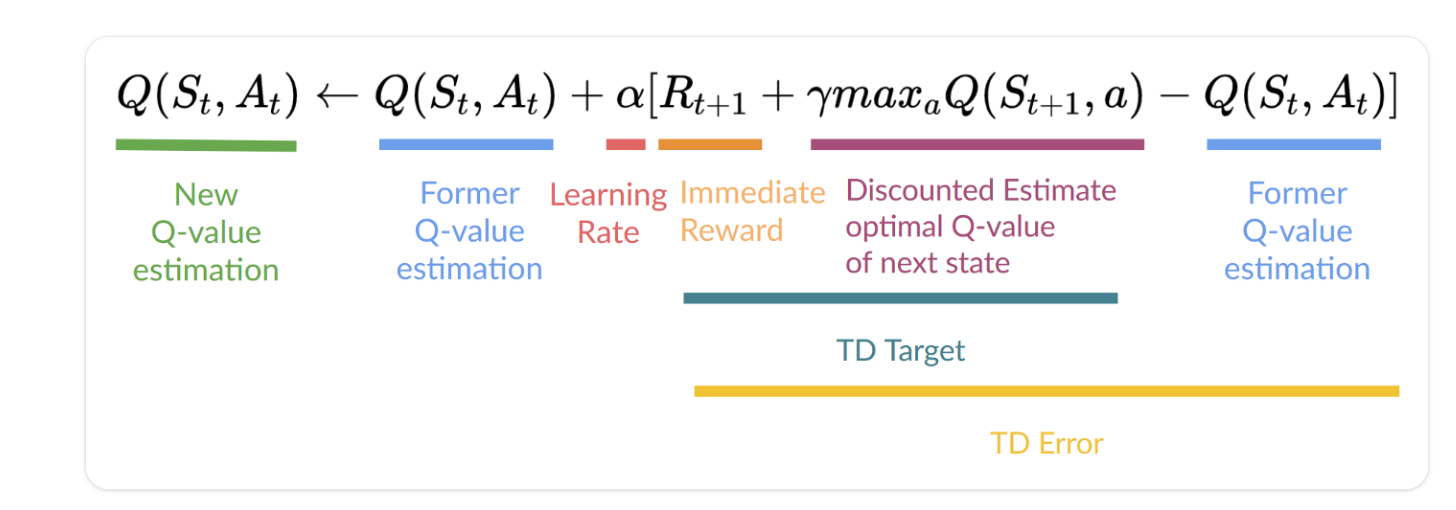
Step4:更新 Q(St, At)
Q Learning is an off-policy algorithm
更新:
- 我们需要St,At, Rt+1,St+1
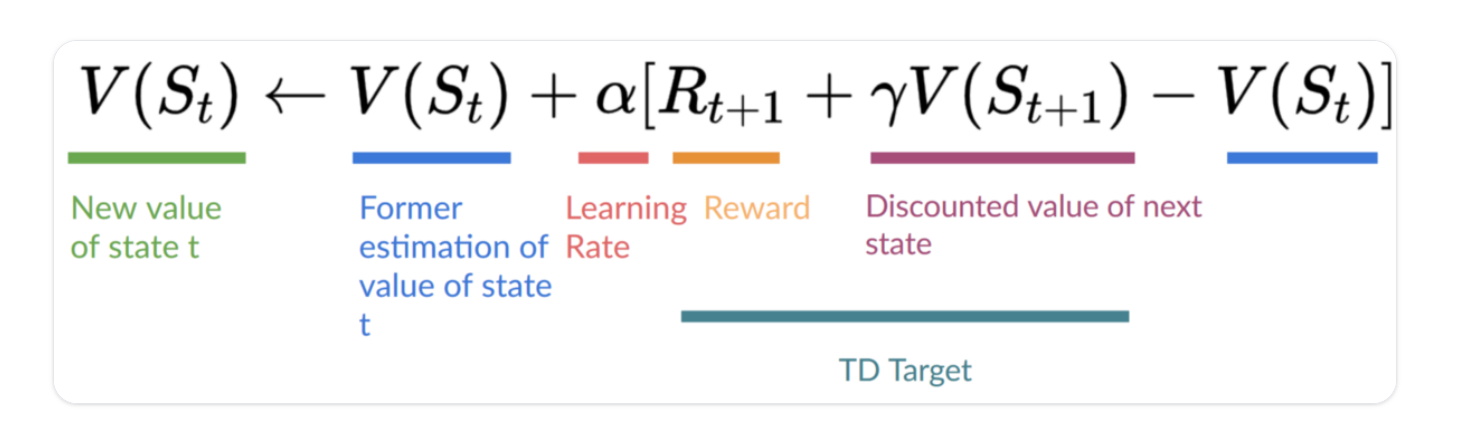
- 为了更新给定状态-操作的Q值,我们使用TD目标
TD目标:
- 我们在采取行动后获得奖励
- 为了获得最佳的下一个状态操作对值,我们使用贪婪策略来选择下一个最佳操作。(请注意,这不是一个 epsilon 贪婪策略,它将始终采取具有最高状态操作值的操作。)
Q Learning is an off-policy algorithm.(Q-Learning是一种非政策算法)
-
Off-policy:
using a different policy for acting (inference) and updating (training).(使用不同的策略进行操作(推理)和更新(训练))
-
On-policy:
using the same policy for acting and updating.(使用相同的策略操作和更新。)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号