

什么是强化学习
强化学习流程:
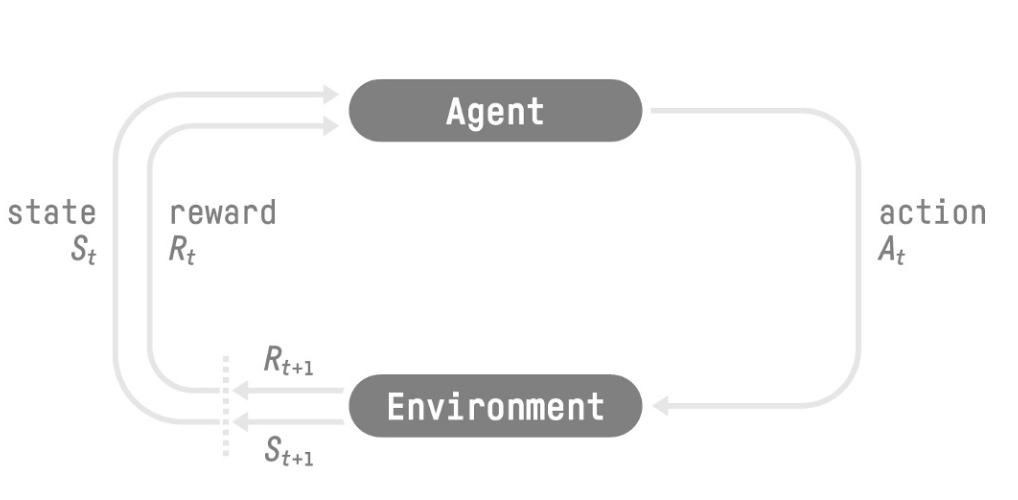
- 我们的代理从环境接收 — 我们接收游戏的第一帧(环境) State S0
- 基于代理采取的情况 — 我们的代理将向右移动 S0 action A0
- 环境走向新的——新的框架 State S0
- 环境给了代理一些——我们没有死(正面奖励+1)Reward R0
RL 循环输出一系列状态、操作、奖励和下一个状态

解决强化学习问题的两种主要方法:
这个政策是我们想要学习的功能,我们的目标是找到最优的政策π*,当代理人按照它行事时,期望回报最大化的策略。我们通过培训发现这一点π*。有两种方法可以训练我们的代理找到此最佳策略π*:
- 直接地,通过教代理了解在给定当前状态的情况下采取哪些操作:基于策略的方法。 Policy-Based Methods
- 间接地,教代理了解哪种状态更有价值,然后采取导致更有价值的状态的操作:基于值的方法。 Policy-Based Methods
基于策略的方法:
在基于策略的方法中,我们直接学习策略函数。
此函数将定义每个状态与最佳相应操作之间的映射。我们也可以说,它将定义该状态下可能操作集的概率分布。
我们有两种类型的策略:
- 确定性:处于给定状态的策略将始终返回相同的操作。

操作=策略(状态)
- 随机指标:输出操作的概率分布。

基于价值的方法:
在基于值的方法中,我们学习的不是策略函数,而是将状态映射到处于该状态的期望值的值函数。
状态的值是代理在从该状态开始时可以获得的预期折扣回报,然后根据我们的策略进行操作。
“按照我们的策略行事”只是意味着我们的政策是“走向价值最高的状态”
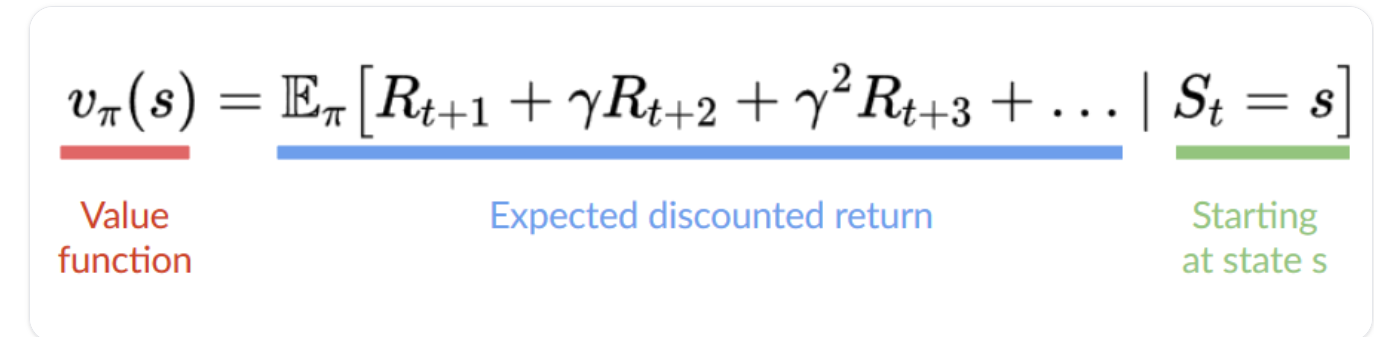

 浙公网安备 33010602011771号
浙公网安备 33010602011771号