

crawl spider
crawl spider继承Spider类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(Rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合,也可以重写一些方法来实现特定的功能。简单来说就是简单高效的爬取一些url比较固定的网址。
1.创建crawlspier
scrapy genspider -t crawl 爬虫名 允许的域
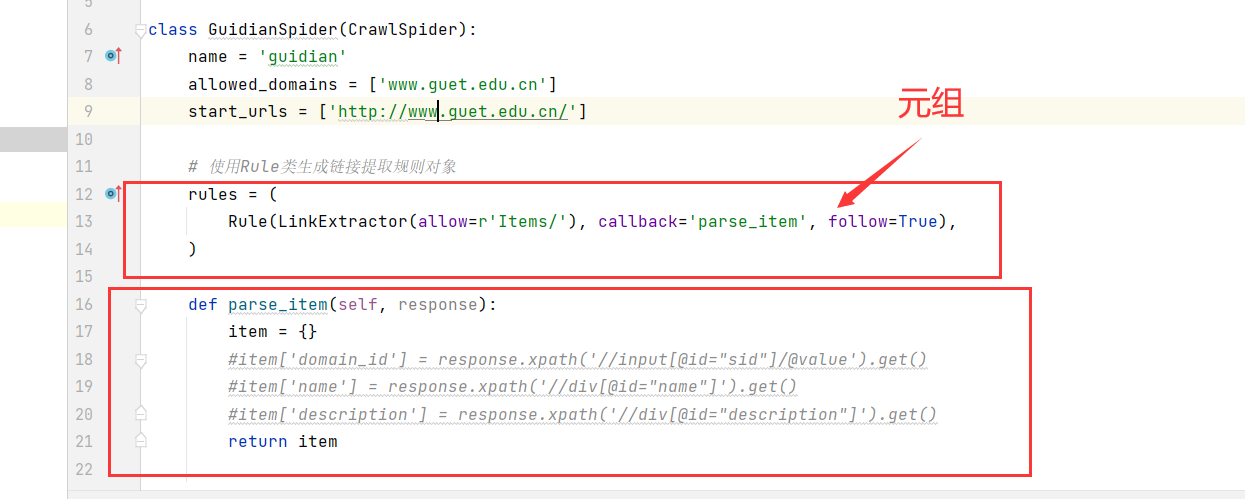
# 链接提取规则
rules = (
# 使用Rule类生成链接提取规则对象
# LinkExtractor用于设置链接提取规则,一般使用allow参数,接收正则表达式
# follow参数决定是否在链接提取器提取的链接对应的响应中继续应用链接提取器提取链接
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号