

scrapy框架学习
scrapy框架的概念和流程
scrapy是一个python编写的开源网络爬虫框架。它被设计用于爬取网络数据、提取结构性数据的框架。
少量的代码,就能够快速的抓取
工作流程
爬虫流程:
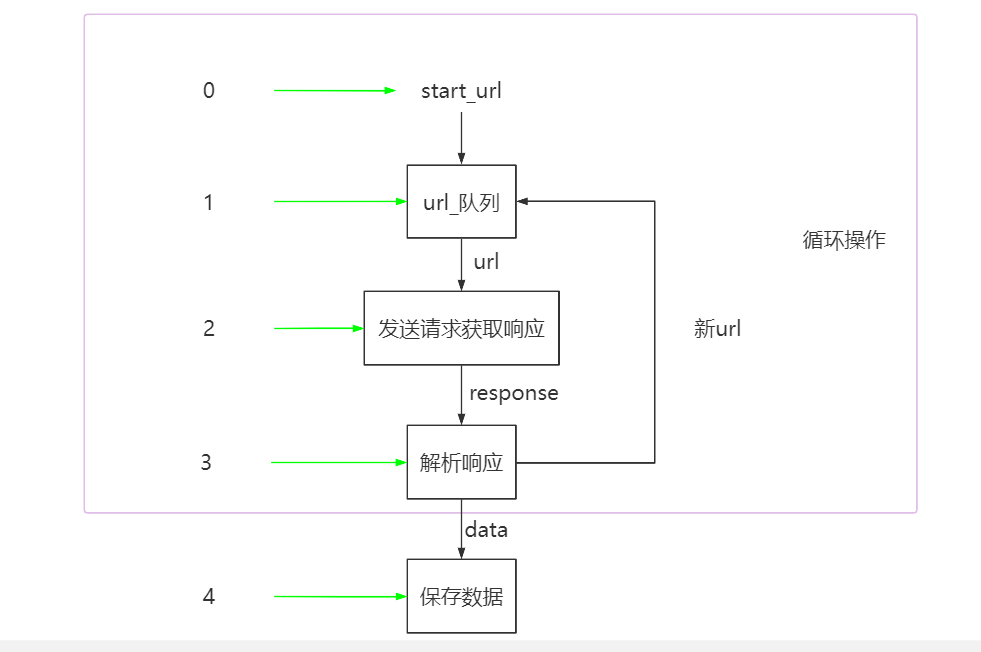
变形之后的scrapy流程:
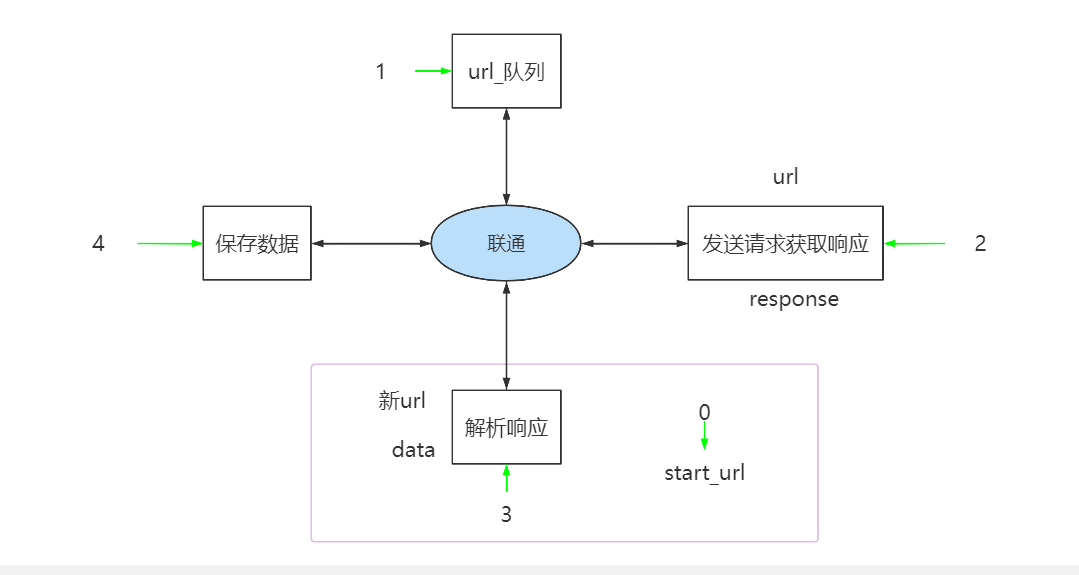
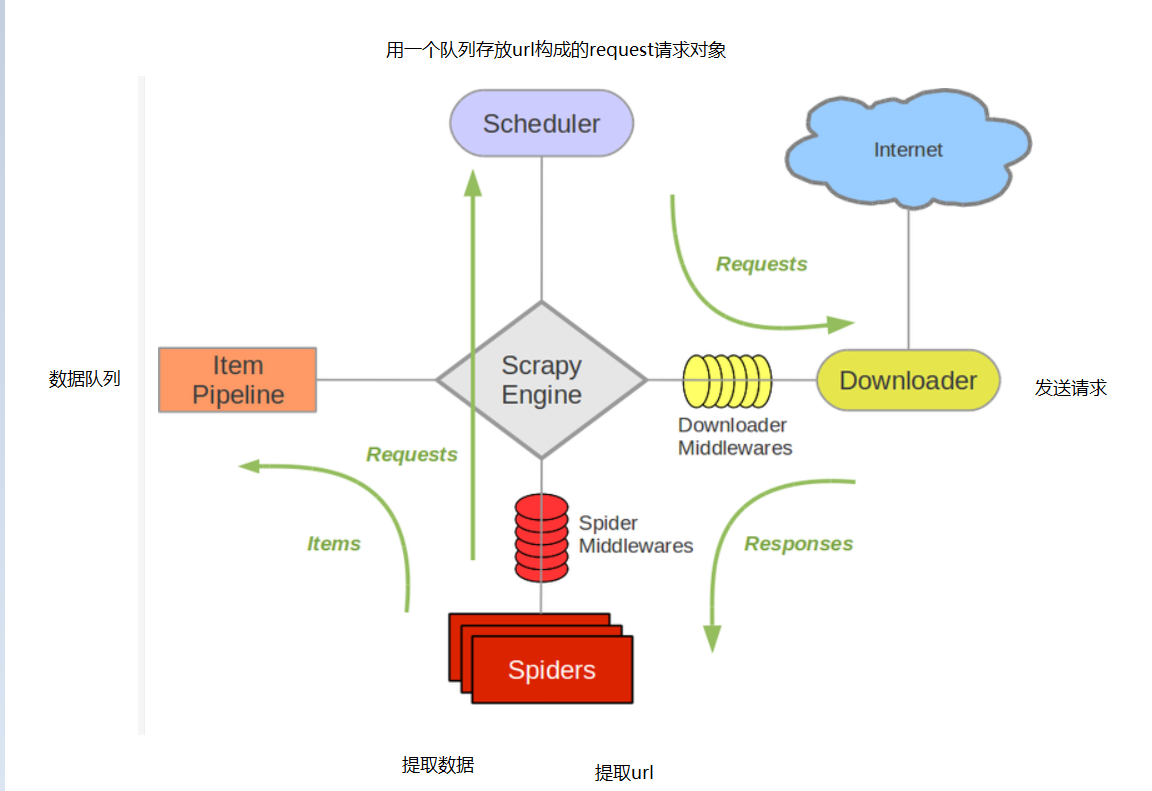
1.爬虫起始url构造成request对象-->爬虫中间件-->引擎-->调度器
2.调度器把request-->引擎-->下载中间件-->下载器
3.下载器发送请求,获取response响应-->下载中间件--->引擎---->爬虫中间件---爬虫
4.1爬虫提取url地址,组装成request对象--->爬虫中间件--->引擎-->调度器,重复步骤2
4.2爬虫提取数据-->引擎-->管道处理和保存数据
scrapy的三个内置对象
- request请求对象:由url method post_data headers等构造
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
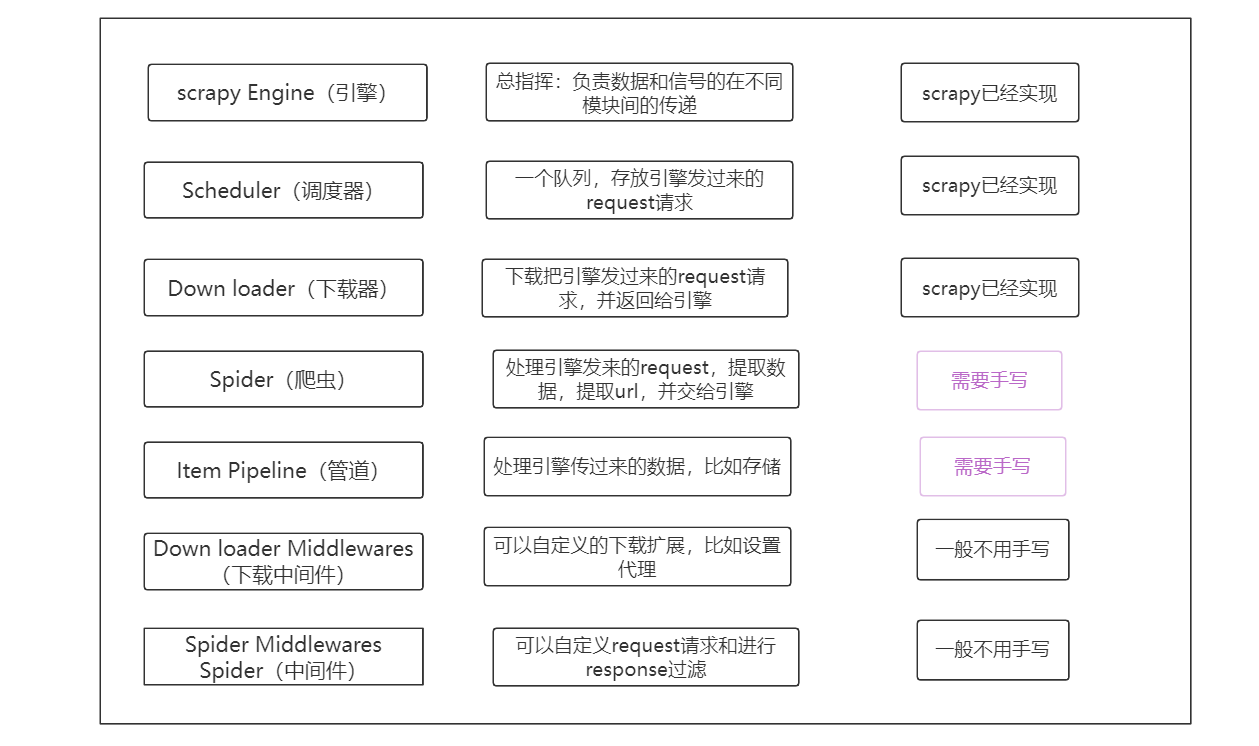
scrapy中每个模块的具体作用
scrapy入门使用
创建一个爬虫项目:输入命令scrapy startproject 模块名称
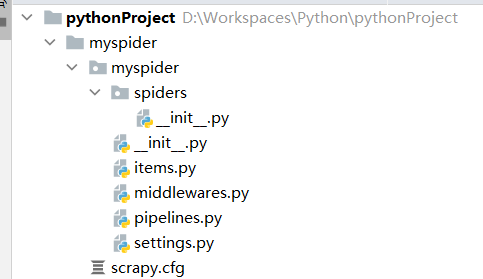
创建爬虫目标文件: 输入scrapy genspider 爬取名 网站域名
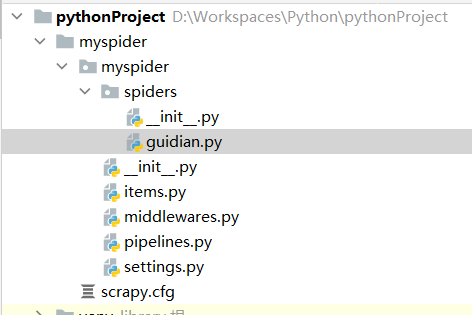
运行scrapy:scrapy crawl <爬虫名字>
完善爬虫
修改起始url
检查修改允许的域名
在parse方法中实现爬取逻辑
注意:
- scrapy.Spider爬虫类中必须有名为parse的解析
- 如果网站结果层次比较复杂,也可以自定义其他解析函数
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_url中的url地址不受这个限制
- 启动爬虫的时候注意启动的位置,是在项目路径下启动
- parse()函数中使用yield返回数据,注意:解析函数中的yield能够传递的对象只能是:Baseitem(请求对象),Request(数据对象),dict,None
定位元素以及提取数据、属性值的方法
1.response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
2.额外方法extract():返回一个包含有字符串的列表
3.额外方法extract_first():返回列表中的第一个字符串,列表为空返回None
xpath方法返回的是选择器对象,extract()用于从选择器中提取数据
xpath结果为只含有一个值的列表,可以使用extract_first(),
如果为多个值则使用extract()response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对象的请求的url地址
- response.headers:响应头
- response.request.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
保存数据
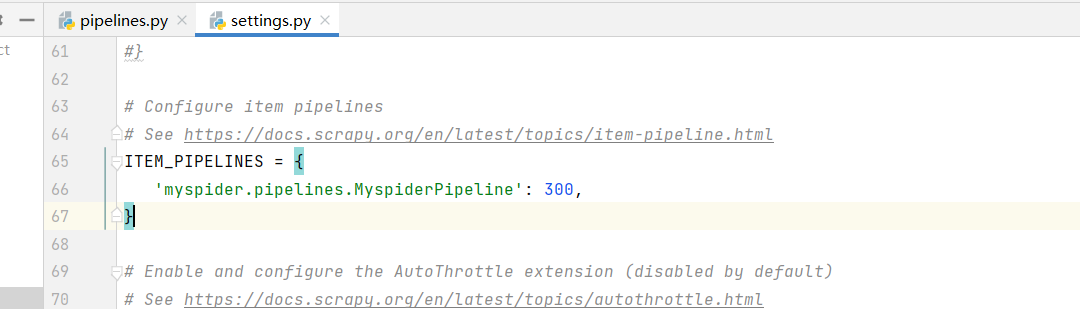
在pipelines.py文件中定义对文件的操作
定义一个管道类
重写管道类的process_item方法
process_item方法处理完item之后必须返回给引擎在settings中启用管道:
scrapy数据建模和请求
数据建模
为什么
定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字段代替
使用scrapy的一些特定组件需要item做支持,如scrapy的ImagePipeline管道类怎么做?
在item.py文件中定义要提取的字段:
class MyspiderItem(scrapy.Item):
name = scrapy.Field()怎么用?
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
请求
翻页请求的思路
requests模块实现翻页请求:
1.找到下一页的URL地址
2.调用requests.get(url)
scrapy实现翻页请求:
1.找到下一页的url地址
2.调用url地址的请求对象,传递给引擎
构造(request)请求对象,并发送请求
1.确定url地址
2.构造请求,scrapy.Request(url,callback)
- callback:指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
3.把请求交给引擎:yield scrapy.Request(url,callback)
注意:
1.可以在settings中设置ROBOT协议
ROBOTSTXT_OBEY = False2.可以在settings中设置User-Agent:
# sceapy发送的每一个请求的默认UA都是设置的这个User-Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
ROBOTSTXT_OBEY = False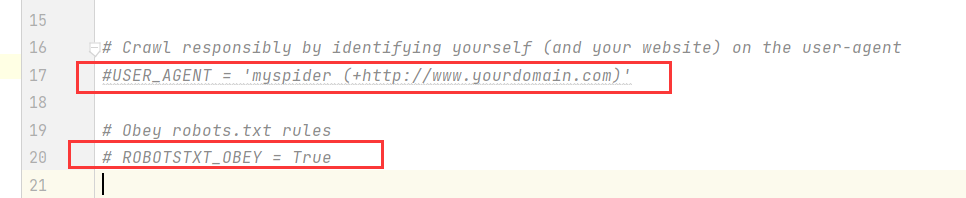
其他参数
scrapy.Request
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=Fallse])参数解释
中括号中的参数为可选参数,可写可不写
callback:表示当前的url响应交给哪个函数去处理(默认为parse函数)
meta:实现数据在不同解析函数中传递,meta默认带有部分数据,比如下载延迟、请求深度等(用于解析方法之间的数据传递,常用在一条数据分散在多个不同结构的页面中的情况)
dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为True,start_urls中的地址会被反复请求,否则程序不会启动
headers:接收一个字典,其中不包括cookies
cookies:接收一个字典,专门放置cookies
method:指定POST或GET请求
body:接收json字符串,为post的数据发送payload_post请求
meta参数的使用
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self, response):
...
yield scrapy.Request(detail_url, callback=self.parse_detail,mate={"item":item})
...
def parse_detail(self, response):
# 获取之前传入的item
item=response.meta["item"]注意:
1.meta参数是一个字典
2.meta字典中有一个固定的键proxy,表示代理ip
开发流程总结
1.创建项目
scrapy startproject 项目名
2.明确目标
在item.py文件中进行建模
3.创建爬虫
3.1创建爬虫
scrapy genspider 爬虫名 允许的域
3.2完成爬虫
修改起始url
检查修改允许的域名allowed_aomains
编写解析方法4.保存数据
在pipelines.py文件中定义对数据的处理的管道
在settings.py文件中注册启用管道scrapy管道的使用
1.pipeline中常用的方法:
- process_item(self,item,spider):
- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
- open_spider(self,spider):在爬虫开启的时候仅执行一次
- close_spider(self,spider):在爬虫关闭的时候仅执行一次
2.管道文件的修改
def open_spider(self, spider):
if spider.name == 'guidian':
self.file = open('guet.json', 'w')
def close_spider(self, spider):
if spider.name == 'guidian':
self.file.close()class MongoPipeline(object):
def open_spider(self, spider):
if spider.name == 'guidian':
self.client = MongoClient('127.0.0.1', 27017)
self.db = self.client['guet']
self.col = self.db['guidian']
def process_item(self, item, spider):
if spider.name == 'guidian':
data = dict(item)
self.col.insert(data)
return item
def close_spider(self, spider):
if spider.name == 'guidian':
self.client.close()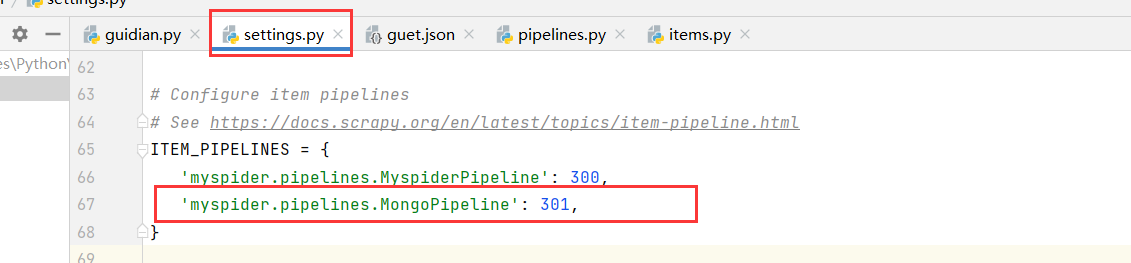
scrapy中间件的使用
scrapy中间件的分类和作用
分类
根据scrapy运行流程中所在位置不同分为:
1.下载中间件
2.爬虫中间件
作用
1.对header以及cookie进行更换和处理
2.使用代理ip等
3.对请求进行定制化caoz
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
下载中间件的使用方法
Downloader Middlewares默认方法:
- process_request(self,request,spider):
1.当每个request通过下载中间件时,该方法被调用
2.返回None值:没有return也就是返回None,如果所有的下载器中间件都返回为None,则请求最终被交给下载器
3.返回Response对象:将响应对象交给spider进行解析,(不经过下载器Downloader)
4.返回Request对象:如果返回请求,把request对象通过引擎交给调度器(Scheduler)
- process_response(self,request,response,spider):
1.当下载器完成http请求,传递响应给引擎的时候调用
2.返回Response对象:将响应对象交给spider进行解析
3.返回Request对象:如果返回请求,把request对象通过引擎交给调度器
- 在setting.py中配置开启中间件,权重值越小越先执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号