浦语书生大模型实战训练营06笔记和作业
OpenCompass介绍
评测对象
本算法库的主要评测对象为语言大模型与多模态大模型。我们以语言大模型为例介绍评测的具体模型类型。
-
基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
-
对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
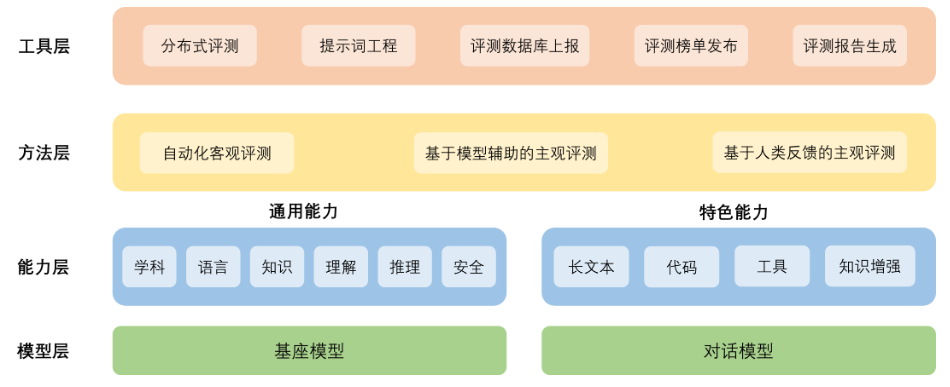
整体架构:
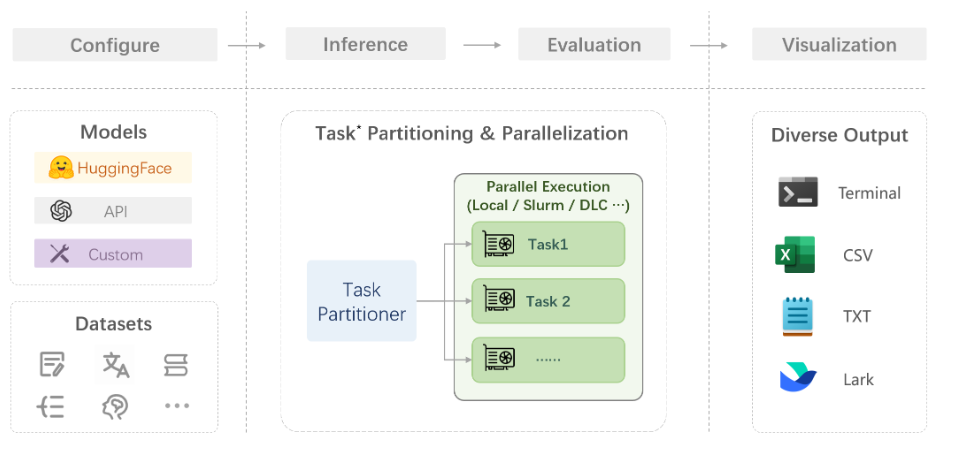
评测流程:
配置 -> 推理 -> 评估 -> 可视化。
实战:
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base source activate opencompass git clone https://github.com/open-compass/opencompass cd opencompass pip install -e .
数据准备:
# 解压评测数据集到 data/ 处 cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/ unzip OpenCompassData-core-20231110.zip # 将会在opencompass下看到data文件夹
查看支持的数据集和模型:
# 列出所有跟 internlm 及 ceval 相关的配置 python tools/list_configs.py internlm ceval
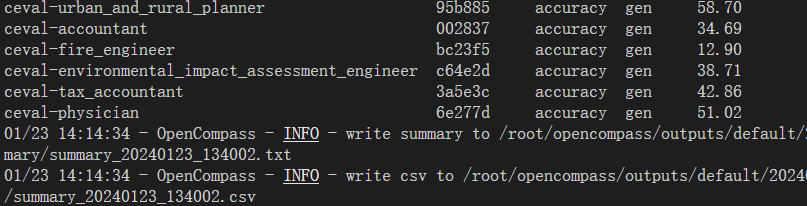
启动评测:
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
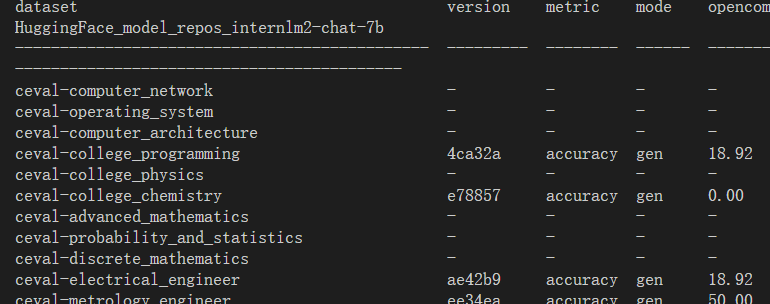
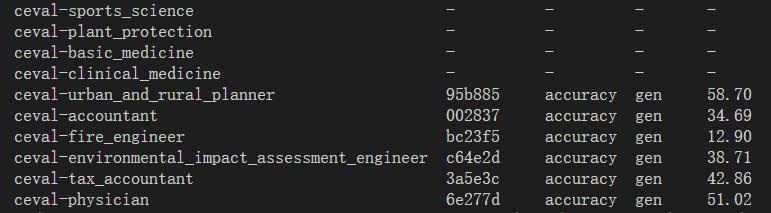
基础作业:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号