Python网络爬虫之requests模块
requests模块
-
什么是requests模块
-
requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
-
-
为什么要使用requests模块
-
因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 手动处理url编码
- 手动处理post请求参数
- 处理cookie和代理操作繁琐
- ......
-
使用requests模块:
- 自动处理url编码
- 自动处理post请求参数
- 简化cookie和代理操作
- ......
-
-
如何使用requests模块
-
安装:
- pip install requests
-
使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
-
-
通过5个基于requests模块的爬虫项目
-
基于requests模块的get请求
- 需求:爬取搜狗指定词条搜索后的页面数据
-
基于requests模块的post请求
- 需求:登录豆瓣电影,爬取登录成功后的页面数据
-
基于requests模块ajax的get请求
- 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
-
基于requests模块ajax的post请求
- 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
-
综合练习
- 需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据http://125.35.6.84:81/xk/
-
代码展示
爬取搜狗指定词条搜索后的页面数据
import requests import os #指定搜索关键字 word = input('enter a word you want to search:') #自定义请求头信息 headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #指定url url = 'https://www.sogou.com/web' #封装get请求参数 prams = { 'query':word, 'ie':'utf-8' } #发起请求 response = requests.get(url=url,params=param) #获取响应数据 page_text = response.text with open('./sougou.html','w',encoding='utf-8') as fp: fp.write(page_text)
请求载体身份标识的伪装:
-
User-Agent:请求载体身份标识,通过浏览器发起的请求,请求载体为浏览器,则该请求的User-Agent为浏览器的身份标识,使用爬虫程序发起的请求,则该请求的载体为爬虫程序,则该请求的User-Agent为爬虫程序的身份标识。可以通过判断该值来获知该请求的载体究竟是基于哪款浏览器还是基于爬虫程序。
-
反爬机制:某些门户网站会对访问该网站的请求中的User-Agent进行捕获和判断,如果该请求的UA为爬虫程序,则拒绝向该请求提供数据。
-
反反爬策略:将爬虫程序的UA伪装成某一款浏览器的身份标识。
登录豆瓣电影,爬取登录成功后的页面数据
import requests import os url = 'https://accounts.douban.com/login' #封装请求参数 data = { "source": "movie", "redir": "https://movie.douban.com/", "form_email": "15027900535", "form_password": "bobo@15027900535", "login": "登录", } #自定义请求头信息 headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } response = requests.post(url=url,data=data) page_text = response.text with open('./douban111.html','w',encoding='utf-8') as fp: fp.write(page_text)
爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
import requests import urllib.request if __name__ == "__main__": #指定ajax-get请求的url(通过抓包进行获取) url = 'https://movie.douban.com/j/chart/top_list?' #定制请求头信息,相关的头信息必须封装在字典结构中 headers = { #定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } #定制get请求携带的参数(从抓包工具中获取) param = { 'type':'5', 'interval_id':'100:90', 'action':'', 'start':'0', 'limit':'20' } #发起get请求,获取响应对象 response = requests.get(url=url,headers=headers,params=param) #获取响应内容:响应内容为json串 print(response.text)
爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
import requests import urllib.request if __name__ == "__main__": #指定ajax-post请求的url(通过抓包进行获取) url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' #定制请求头信息,相关的头信息必须封装在字典结构中 headers = { #定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } #定制post请求携带的参数(从抓包工具中获取) data = { 'cname':'', 'pid':'', 'keyword':'北京', 'pageIndex': '1', 'pageSize': '10' } #发起post请求,获取响应对象 response = requests.get(url=url,headers=headers,data=data) #获取响应内容:响应内容为json串 print(response.text)
爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
import requests from fake_useragent import UserAgent ua = UserAgent(use_cache_server=False,verify_ssl=False).random headers = { 'User-Agent':ua } url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' pageNum = 3 for page in range(3,5): data = { 'on': 'true', 'page': str(page), 'pageSize': '15', 'productName':'', 'conditionType': '1', 'applyname':'', 'applysn':'' } json_text = requests.post(url=url,data=data,headers=headers).json() all_id_list = [] for dict in json_text['list']: id = dict['ID']#用于二级页面数据获取 #下列详情信息可以在二级页面中获取 # name = dict['EPS_NAME'] # product = dict['PRODUCT_SN'] # man_name = dict['QF_MANAGER_NAME'] # d1 = dict['XC_DATE'] # d2 = dict['XK_DATE'] all_id_list.append(id) #该url是一个ajax的post请求 post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' for id in all_id_list: post_data = { 'id':id } response = requests.post(url=post_url,data=post_data,headers=headers) #该请求响应回来的数据有两个,一个是基于text,一个是基于json的,所以可以根据content-type,来获取指定的响应数据 if response.headers['Content-Type'] == 'application/json;charset=UTF-8': #print(response.json()) #进行json解析 json_text = response.json() print(json_text['businessPerson'])
了解cookie和session
无状态的http协议
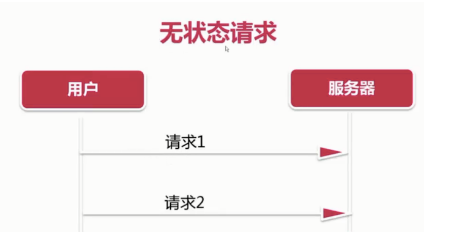
- 如上图所示,HTTP协议 是无状态的协议,用户浏览服务器上的内容,只需要发送页面请求,服务器返回内容。对于服务器来说,并不关心,也并不知道是哪个用户的请求。对于一般浏览性的网页来说,没有任何问题。
- 但是,现在很多的网站,是需要用户登录的。以淘宝为例:比如说某个用户想购买一个产品,当点击 “ 购买按钮 ” 时,由于HTTP协议 是无状态的,那对于淘宝来说,就不知道是哪个用户操作的。
- 为了实现这种用户标记,服务器就采用了cookie这种机制来识别具体是哪一个用户的访问。
了解Cookie

- 如图,为了实现用户标记,在Http无状态请求的基础之上,我们需要在请求中携带一些用户信息(比如用户名之类,这些信息是服务器发送到本地浏览器的,但是服务器并不存储这些信息),这就是cookie机制。
- 需要注意的是:cookie信息是保存在本地浏览器里面的,服务器上并不存储相关的信息。 在发送请求时,cookie的这些内容是放在 Http协议中的header 字段中进行传输的。
- 几乎现在所有的网站都会发送一些 cookie信息过来,当用户请求中携带了cookie信息,服务器就可以知道是哪个用户的访问了,从而不需要再使用账户和密码登录。
- 但是,刚才也提到了,cookie信息是直接放在Http协议的header中进行传输的,看得出来,这是个隐患!一旦别人获取到你的cookie信息(截获请求,或者使用你的电脑),那么他很容易从cookie中分析出你的用户名和密码。为了解决这个隐患,所以有了session机制。
了解session
- 刚才提到了cookie不安全,所以有了session机制。简单来说(每个框架都不一样,这只是举一个通用的实现策略),整过过程是这样:
- 服务器根据用户名和密码,生成一个session ID,存储到服务器的数据库中。用户登录访问时,服务器会将对应的session ID发送给用户(本地浏览器)。浏览器会将这个session ID存储到cookie中,作为一个键值项。以后,浏览器每次请求,就会将含有session ID的cookie信息,一起发送给服务器。
- 服务器收到请求之后,通过cookie中的session ID,到数据库中去查询,解析出对应的用户名,就知道是哪个用户的请求了。
总结
- cookie 在客户端(本地浏览器),session 在服务器端。cookie是一种浏览器本地存储机制。存储在本地浏览器中,和服务器没有关系。每次请求,用户会带上本地cookie的信息。这些cookie信息也是服务器之前发送给浏览器的,或者是用户之前填写的一些信息。
- Cookie有不安全机制。 你不能把所有的用户信息都存在本地,一旦被别人窃取,就知道你的用户名和密码,就会很危险。所以引入了session机制。
- 服务器在发送id时引入了一种session的机制,很简单,就是根据用户名和密码,生成了一段随机的字符串,这段字符串是有过期时间的。
- 一定要注意:session是服务器生成的,存储在服务器的数据库或者文件中,然后把sessionID发送给用户,用户存储在本地cookie中。每次请求时,把这个session ID带给服务器,服务器根据session ID到数据库中去查询,找到是哪个用户,就可以对用户进行标记了。
- session 的运行依赖 session ID,而 session ID 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,那么同时 session 也会失效(但是可以通过其它方式实现,比如在url中传递 session ID)
- 用户验证这种场合一般会用 session。 因此,维持一个会话的核心就是客户端的唯一标识,即session
引入
有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如:
import requests if __name__ == "__main__": #张三人人网个人信息页面的url url = 'http://www.renren.com/289676607/profile' #伪装UA headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #发送请求,获取响应对象 response = requests.get(url=url,headers=headers) #将响应内容写入文件 with open('./renren.html','w',encoding='utf-8') as fp: fp.write(response.text)
一.基于requests模块的cookie操作
- 结果发现,写入到文件中的数据,不是张三个人页面的数据,而是人人网登陆的首页面,why?首先我们来回顾下cookie的相关概念及作用:
- cookie概念:当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie。
- cookie作用:我们在浏览器中,经常涉及到数据的交换,比如你登录邮箱,登录一个页面。我们经常会在此时设置30天内记住我,或者自动登录选项。那么它们是怎么记录信息的呢,答案就是今天的主角cookie了,Cookie是由HTTP服务器设置的,保存在浏览器中,但HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。就像我们去超市买东西,没有积分卡的情况下,我们买完东西之后,超市没有我们的任何消费信息,但我们办了积分卡之后,超市就有了我们的消费信息。cookie就像是积分卡,可以保存积分,商品就是我们的信息,超市的系统就像服务器后台,http协议就是交易的过程。
- 经过cookie的相关介绍,其实你已经知道了为什么上述案例中爬取到的不是张三个人信息页,而是登录页面。那应该如何抓取到张三的个人信息页呢?
思路:
1.我们需要使用爬虫程序对人人网的登录时的请求进行一次抓取,获取请求中的cookie数据
2.在使用个人信息页的url进行请求时,该请求需要携带 1 中的cookie,只有携带了cookie后,服务器才可识别这次请求的用户信息,方可响应回指定的用户信息页数据
import requests if __name__ == "__main__": #登录请求的url(通过抓包工具获取) post_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201873958471' #创建一个session对象,该对象会自动将请求中的cookie进行存储和携带 session = requests.session() #伪装UA headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } formdata = { 'email': '17701256561', 'icode': '', 'origURL': 'http://www.renren.com/home', 'domain': 'renren.com', 'key_id': '1', 'captcha_type': 'web_login', 'password': '7b456e6c3eb6615b2e122a2942ef3845da1f91e3de075179079a3b84952508e4', 'rkey': '44fd96c219c593f3c9612360c80310a3', 'f': 'https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dm7m_NSUp5Ri_ZrK5eNIpn_dMs48UAcvT-N_kmysWgYW%26wd%3D%26eqid%3Dba95daf5000065ce000000035b120219', } #使用session发送请求,目的是为了将session保存该次请求中的cookie session.post(url=post_url,data=formdata,headers=headers) get_url = 'http://www.renren.com/960481378/profile' #再次使用session进行请求的发送,该次请求中已经携带了cookie response = session.get(url=get_url,headers=headers) #设置响应内容的编码格式 response.encoding = 'utf-8' #将响应内容写入文件 with open('./renren.html','w') as fp: fp.write(response.text)
二.基于requests模块的代理操作
- 什么是代理
-
代理就是第三方代替本体处理相关事务。例如:生活中的代理:代购,中介,微商......
-
-
爬虫中为什么需要使用代理
-
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问。所以我们需要设置一些代理IP,每隔一段时间换一个代理IP,就算IP被禁止,依然可以换个IP继续爬取。
-
-
代理的分类:
-
正向代理:代理客户端获取数据。正向代理是为了保护客户端防止被追究责任。
-
反向代理:代理服务器提供数据。反向代理是为了保护服务器或负责负载均衡。
-
-
免费代理ip提供网站
-
http://www.goubanjia.com/
-
西祠代理
-
快代理
-
import requests import random if __name__ == "__main__": #不同浏览器的UA header_list = [ # 遨游 {"user-agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)"}, # 火狐 {"user-agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"}, # 谷歌 { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"} ] #不同的代理IP proxy_list = [ {"http": "112.115.57.20:3128"}, {'http': '121.41.171.223:3128'} ] #随机获取UA和代理IP header = random.choice(header_list) proxy = random.choice(proxy_list) url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip' #参数3:设置代理 response = requests.get(url=url,headers=header,proxies=proxy) response.encoding = 'utf-8' with open('daili.html', 'wb') as fp: fp.write(response.content) #切换成原来的IP requests.get(url, proxies={"http": ""})
三.基于multiprocessing.dummy线程池的数据爬取
爬取梨视频的视频信息,并计算其爬取数据的耗时
普通爬取:
import requests import random from lxml import etree import re from fake_useragent import UserAgent #安装fake-useragent库:pip install fake-useragent url = 'http://www.pearvideo.com/category_1' #随机产生UA,如果报错则可以添加如下参数: #ua = UserAgent(verify_ssl=False,use_cache_server=False).random #禁用服务器缓存: #ua = UserAgent(use_cache_server=False) #不缓存数据: #ua = UserAgent(cache=False) #忽略ssl验证: #ua = UserAgent(verify_ssl=False) ua = UserAgent().random headers = { 'User-Agent':ua } #获取首页页面数据 page_text = requests.get(url=url,headers=headers).text #对获取的首页页面数据中的相关视频详情链接进行解析 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') detail_urls = [] for li in li_list: detail_url = 'http://www.pearvideo.com/'+li.xpath('./div/a/@href')[0] title = li.xpath('.//div[@class="vervideo-title"]/text()')[0] detail_urls.append(detail_url) for url in detail_urls: page_text = requests.get(url=url,headers=headers).text vedio_url = re.findall('srcUrl="(.*?)"',page_text,re.S)[0] data = requests.get(url=vedio_url,headers=headers).content fileName = str(random.randint(1,10000))+'.mp4' #随机生成视频文件名称 with open(fileName,'wb') as fp: fp.write(data) print(fileName+' is over')
基于线程池爬取:
import requests import random from lxml import etree import re from fake_useragent import UserAgent #安装fake-useragent库:pip install fake-useragent #导入线程池模块 from multiprocessing.dummy import Pool #实例化线程池对象 pool = Pool() url = 'http://www.pearvideo.com/category_1' #随机产生UA ua = UserAgent().random headers = { 'User-Agent':ua } #获取首页页面数据 page_text = requests.get(url=url,headers=headers).text #对获取的首页页面数据中的相关视频详情链接进行解析 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') detail_urls = []#存储二级页面的url for li in li_list: detail_url = 'http://www.pearvideo.com/'+li.xpath('./div/a/@href')[0] title = li.xpath('.//div[@class="vervideo-title"]/text()')[0] detail_urls.append(detail_url) vedio_urls = []#存储视频的url for url in detail_urls: page_text = requests.get(url=url,headers=headers).text vedio_url = re.findall('srcUrl="(.*?)"',page_text,re.S)[0] vedio_urls.append(vedio_url) #使用线程池进行视频数据下载 func_request = lambda link:requests.get(url=link,headers=headers).content video_data_list = pool.map(func_request,vedio_urls) #使用线程池进行视频数据保存 func_saveData = lambda data:save(data) pool.map(func_saveData,video_data_list) def save(data): fileName = str(random.randint(1,10000))+'.mp4' with open(fileName,'wb') as fp: fp.write(data) print(fileName+'已存储') pool.close() pool.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号