
Java JDBC
一、什么是JDBC?
JDBC就是Java链接数据库的一种方式,一种规则。
二、为什么要学JDBC?
因为你的Java项目需要链接数据库保存数据。目前来说,JDBC是最底层的东西,当前市面上流行的最火的JDBC封装有hibernate和mybatis,这俩都可以简化一些操作。其实他俩底层还是JDBC,就是做了个封装,让人使用更简单而已。为了深入了解hibernate和mybatis,JDBC还是要学的。
三、执行增删改语句
先来尝试一条语句:
package com.StadyJava.day2; import org.junit.*; import java.sql.Connection; import java.sql.DriverManager; import java.sql.Statement; public class JDBCDemo { @Test public void Con() throws Exception { String sql="insert SysUser values('201408090009',123,'李信','男','王者荣耀','shuyunquan@qq.com','老师')"; //1.加载注册Mysql驱动 Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver"); //2.链接数据库,获取链接对象 Connection con = DriverManager.getConnection("jdbc:sqlserver://localhost:1433;databaseName=Design;user=sa;password=123"); //3.创建语句对象 Statement st=con.createStatement(); //4.执行SQL语句 int row=st.executeUpdate(sql); //5.释放资源 st.close(); con.close(); System.out.println(row); } }
是可以成功的,这里我使用的Jnuit测试单元来做的,不是Main方法,这个以前的博客介绍过。还有JDBC的SQL Server链接包,在Maven里面下载就好了。Maven不会的自己学。
executeUpdate方法可以执行增删改和创建表的语句。
四、执行查询语句
增删改完成了,现在来看看查询语句是怎么写的,首先要知道,JDBC查询会返回一个结果集 ResultSet 这个结果集就像一个游标一样,我们可以逐层访问他里面的内容。
首先我写一个SQL语句
select Name,Sex from SysUser
我查询两个字段,内容是这样的
Name Sex
许嵩 男
林俊杰 男
陈亮 男
缪斯 女
魁拔 女
范锁 男
李信 男
看看代码,换成 executeQuery 了
package com.StadyJava.day2; import org.junit.*; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class JDBCDemo { @Test public void Con() throws Exception { String sql="select Name,Sex from SysUser"; //1.加载注册Mysql驱动 Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver"); //2.链接数据库,获取链接对象 Connection con = DriverManager.getConnection("jdbc:sqlserver://localhost:1433;databaseName=Design;user=sa;password=123"); //3.创建语句对象 Statement st=con.createStatement(); //4.执行SQL语句 ResultSet rs=st.executeQuery(sql); //处理结果集 while (rs.next()){ String name=rs.getString("Name"); String sex=rs.getString("Sex"); System.out.println(name+','+sex); } //5.释放资源 rs.close(); st.close(); con.close(); } }
上面的都是最简单最简单的JDBC操作,工作中我们完全不会这样去操作,去写。就比如这个增删改,写在一个方法里面,那我们多处使用这个,岂不是每个方法都要写?
这样代码就重复了,违背了ORP单一原则。.Net里面是有类库这一概念的,就是封装成一个类库,使用的时候调用就可以了。
Java这里我们也来对JDBC进行一个封装。
一、创建操作接口
写接口比较规范,我规定你对我的这个类进行的操作就是增删改查,下面写实现类
package com.StadyJava.DAODemo.dao; import com.StadyJava.DAODemo.domain.User; import java.util.List; public interface IUserDAO { /** * 保存操作 * @param user */ void save(User user); /** * 删除操作 * @param id */ void delete(Long id); void update(Long id,User newuser); User get(Long id); List<User> listAll(); }
可以看到,我的接口写了注释,/** 然后敲回车就是对方法的注释,这样有一个好处,就是我的实现类,你在写的时候,鼠标放上去,会有提示。
二、创建Model类
我创建了一个User的Model类:
package com.StadyJava.DAODemo.domain; import lombok.Getter; import lombok.Setter; @Setter@Getter public class User { private long id; private String name; private String sex; @Override public String toString() { return "User{" + "id=" + id + ", name='" + name + '\'' + ", sex=" + sex + '}'; } }
我使用的Lombok自动创建的属性构造器
三、连接池
什么是连接池?可以看到,我们上面是直接写了一个Connection,使用完毕之后直接释放的。这样不好,因为Connection连接创建非常耗费资源,你用一下就释放了,再用再连接,这样不行的。所以连接池的概念就出来了,连接池里有默认的几个Connection,谁用谁来获取,使用完成之后释放,这个释放的意思是把Connection资源归还给连接池,并没有真正的释放。这样保证了效率。
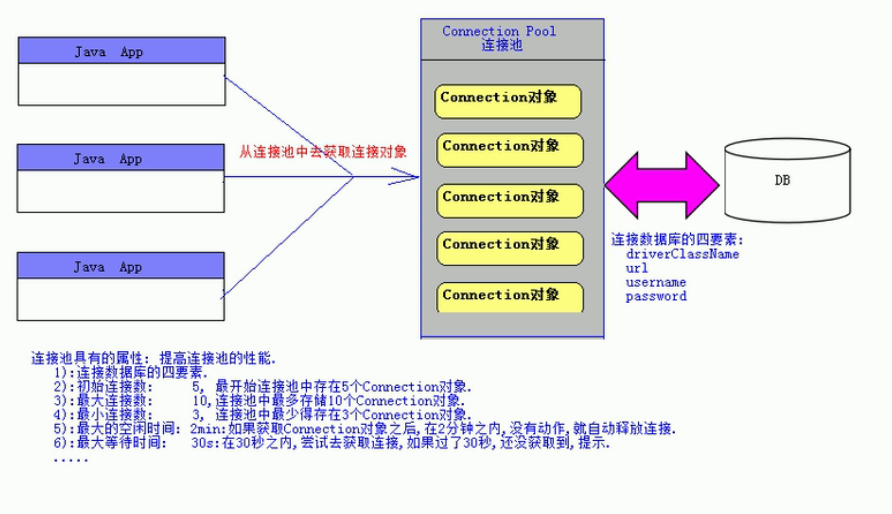

连接池有两种是需要介绍一下的
1.Apache做的DBCP
2.阿里做的号称世界上最快的druid
先来介绍DBCP连接池
package com.StadyJava.DAODemo.util;
import com.StadyJava.DAODemo.JunitDAO;
import org.apache.commons.dbcp2.BasicDataSourceFactory;
import javax.sql.*;
import java.sql.*;
import java.util.Properties;
public class DBCPUtil {
//创建一个连接池对象,因为我的连接池对象只需要创建一次即可,所以我写在静态代码块里
private static DataSource ds=null;
static{
Properties properties=new Properties();
try {
properties.load(DBCPUtil.class.getClass().getResourceAsStream("/test"));
ds=BasicDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConn(){
try {
return ds.getConnection();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
//释放资源
public static void close(Connection conn, Statement st, ResultSet rs) {
try{
if (rs != null) {
rs.close();
}
}catch (Exception e){
e.printStackTrace();
}finally {
try{
if (st != null) {
st.close();
}
}catch (Exception e){
e.printStackTrace();
}finally {
try{
if (conn != null) {
conn.close();
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
}
然后在Junit测试写了一个调用的方法:
@Test
public void DBCPTest() throws Exception {
//测试链接池
Connection conn=DBCPUtil.getConn();
//这里的SQL暂时先写死
PreparedStatement ps=conn.prepareStatement("select AccountNumber from SysUser ");
ResultSet rs=ps.executeQuery();
while (rs.next()) {
System.out.println(rs.getLong("AccountNumber"));
}
DBCPUtil.close(conn,ps,rs);
}
运行结果:
下面是DruId连接池,其实都差不多
package com.StadyJava.DAODemo.util;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import org.apache.commons.dbcp2.BasicDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
public class DruidUtil {
//创建一个连接池对象,因为我的连接池对象只需要创建一次即可,所以我写在静态代码块里
private static DataSource ds=null;
static{
Properties properties=new Properties();
try {
properties.load(DBCPUtil.class.getClass().getResourceAsStream("/test"));
ds=DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConn(){
try {
return ds.getConnection();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
//释放资源
public static void close(Connection conn, Statement st, ResultSet rs) {
try{
if (rs != null) {
rs.close();
}
}catch (Exception e){
e.printStackTrace();
}finally {
try{
if (st != null) {
st.close();
}
}catch (Exception e){
e.printStackTrace();
}finally {
try{
if (conn != null) {
conn.close();
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
}
这里面我们的Statement换成了PreparedStatement,因为PreparedStatement可以去拼接SQL,是动态的SQL,statement仅仅是静态的。
PreparedStatement和statement都可以表示语句对象:
Preparedstatement相对于statement的优势:
1):拼接SQL上,操作更简单.
2):性能会更加高效,但是需要取决于数据库服务器是否支持.
MySQL:不支持 Oracle:支持
四、创建JDBC的模板
因为增删改的操作大部分都是一样的,所以建立一个模板比较好,这个模板里面就两个方法,一个是update,主要是增删改。一个是queue,主要是查询。
这里我写了T ,自定义泛型,主要是传入的类型是什么,我获取的返回类型就是什么。
package com.StadyJava.DAODemo.util; import com.StadyJava.DAODemo.dao.IResultSetHandler; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; public class JDBCTemplate { /** * 操作增删改的模板 * @param sql * @param params * @return */ public static int update(String sql,Object... params){ Connection conn=null; PreparedStatement ps=null; try { conn=DruidUtil.getConn(); ps=conn.prepareStatement(sql); for (int i = 0; i < params.length; i++) { ps.setObject(i+1,params[i]); } return ps.executeUpdate(); } catch (Exception e) { e.printStackTrace(); }finally { DruidUtil.close(conn,ps,null); } return 0; } /** * 操作查询的模板 * @param sql * @param params * @return */ public static <T>T queue(String sql, IResultSetHandler<T> rsh, Object... params) { Connection conn=null; PreparedStatement ps=null; ResultSet rs=null; try { conn=DruidUtil.getConn(); ps=conn.prepareStatement(sql); for (int i = 0; i < params.length; i++) { ps.setObject(i+1,params[i]); } rs=ps.executeQuery(); return rsh.handle(rs); } catch (Exception e) { e.printStackTrace(); }finally { DruidUtil.close(conn,ps,rs); } throw new RuntimeException("查询结果有错误"); } }
五、创建接口的实现类
我们第一步写了一个操作的规范接口,现在来实现一下
package com.StadyJava.DAODemo.dao.impl; import com.StadyJava.DAODemo.dao.IResultSetHandler; import com.StadyJava.DAODemo.dao.IUserDAO; import com.StadyJava.DAODemo.domain.User; import com.StadyJava.DAODemo.util.JDBCTemplate; import com.StadyJava.DAODemo.util.JDBCUtil; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; import java.util.ArrayList; import java.util.List; public class UserDAOImpl implements IUserDAO { @Override public void save(User user) { JDBCTemplate.update("insert SysUser (AccountNumber,Name,Sex) values(?,?,?)",user.getId(),user.getName(),user.getSex()); } @Override public void delete(Long id) { JDBCTemplate.update("delete SysUser where AccountNumber=?,Name=?,Sex=?",id); } @Override public void update(Long id, User newuser) { JDBCTemplate.update("update SysUser set AccountNumber=?, Name=? ,Sex=? where AccountNumber=?",id,newuser.getId(),newuser.getName(),newuser.getSex()); } @Override public User get(Long id) { return JDBCTemplate.queue("select * from SysUser where AccountNumber=?",new UserResultSetHandler(),id); } @Override public List<User> listAll() { return JDBCTemplate.queue("select AccountNumber,Name,Sex from SysUser",new UserResultSetHandler()); } } //结果集接口的实现类 class UserResultSetHandler implements IResultSetHandler<List<User>> { @Override public List<User> handle(ResultSet rs) throws Exception { List<User> list=new ArrayList(); while (rs.next()) { User user=new User(); user.setId(rs.getLong("AccountNumber")); user.setName(rs.getString("Name")); user.setSex(rs.getString("Sex")); list.add(user); } return list; } }
下面写了一个查询的结果集的实现类,可以发现,我的 get() 方法其实是报错的,因为我的返回类型不一致了,这里就牵涉出了另一个问题,还要对查询的结果集的实现类再次进行重构,但是这个重构使用了Java的内省机制,还要求你的User Model类的字段必须和数据库里面的字段一致,这里我懒得改了,直接贴出代码
package com.StadyJava.DAODemo.util; import com.StadyJava.DAODemo.dao.IResultSetHandler; import java.beans.BeanInfo; import java.beans.Introspector; import java.beans.PropertyDescriptor; import java.sql.ResultSet; public class BeanHandler<T> implements IResultSetHandler<T> { private Class<T> classType; public BeanHandler(Class<T> classType){ this.classType=classType; } @Override public T handle(ResultSet rs) throws Exception { //1.创建对应类的一个对象 T obj=classType.newInstance(); //2.使用内省机制取出数据 BeanInfo beanInfo=Introspector.getBeanInfo(classType,Object.class); PropertyDescriptor [] pds=beanInfo.getPropertyDescriptors(); if (rs.next()) { for (PropertyDescriptor pd : pds) { //获取对象的属性名 String columnName=pd.getName(); Object val=rs.getObject(columnName); //3.调用对象的setter方法 pd.getWriteMethod().invoke(obj,val); } } return obj; } }
package com.StadyJava.DAODemo.util; import com.StadyJava.DAODemo.dao.IResultSetHandler; import java.beans.BeanInfo; import java.beans.Introspector; import java.beans.PropertyDescriptor; import java.sql.ResultSet; import java.util.ArrayList; import java.util.List; public class BeanListHandler<T> implements IResultSetHandler<List<T>> { private Class<T> classType; public BeanListHandler(Class<T> classType){ this.classType=classType; } @Override public List<T> handle(ResultSet rs) throws Exception { List<T> list = new ArrayList<>(); while (rs.next()) { //1.创建对应类的一个对象 T obj = classType.newInstance(); list.add(obj); //2.使用内省机制取出数据 BeanInfo beanInfo = Introspector.getBeanInfo(classType, Object.class); PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors(); for (PropertyDescriptor pd : pds) { //获取对象的属性名 String columnName = pd.getName(); Object val = rs.getObject(columnName); //3.调用对象的setter方法 pd.getWriteMethod().invoke(obj, val); } } return list; } }
然后调用的时候,这样写就好了,这是终极的写法
@Override public User get(Long id) { return JDBCTemplate.queue("select * from SysUser where AccountNumber=?",new BeanHandler<>(User.class),id); }
传一个你的类进去,就可以了,那个查询结果集的实现类就可以删了
我的实现很简单,就是使用Junit写的实现类
@Test public void testGetList() { System.out.println(userDAO.listAll()); } @Test public void testGet() { System.out.println(userDAO.get(201408090001L)); }
Junit很好用,大家一定要用起来。
还有一些其他的知识需要了解一下:
事务
所谓的事务,理解之前先讲一个例子。银行转账的问题,比如我买许嵩的专辑,给许嵩转账。那么我转账分为几个步骤:
1.我的账户钱减少
2.许嵩账户钱增加
3.完成
这三步必须是顺序进行的,假如现在在第二步的时候断电了,我的钱没了,许嵩的钱却没有增加。这种情况显然是不合理的。所以事务的概念就出来了。所谓的事务,就是把几个步骤当做一个。
只要有一个失败,那么全部失败。必须全部成功,那才算成功。
事务这个研究之后再另外写一篇文章。现在这里就简单的介绍一下。
下面是一些简单的java代码:
//事务,手动写一个 Connection conn=null; //关闭事务的自动提交 conn.setAutoCommit(false); //提交事务 conn.commit(); //回滚事务 conn.rollback();
批处理
讲一下什么是批处理,在执行SQL语句的时候,目前都是一条一条的执行的,这样是很麻烦的,效率也很低。可以举个例子了解一下。例如公交车,明明有200个座位,但是一次却只拉一个人到目的地。
这样假如我有3000人,那就要3000次。效率可谓是低下了。所以批处理就是一次执行多条语句。
公交车每次拉满200人,这样3000人只需要15次就完事了。这就是批处理的意义所在了。可以看一下代码是怎么写的,这里只简单的介绍一下语句。
//批处理 PreparedStatement ps=null; for (int i = 0; i < 1000; i++) { String sql="insert 表 values(?,?)"; ps.addBatch(); if (i%200 == 0) { ps.executeBatch();//执行批量操作 ps.clearBatch(); //清空缓存 ps.clearParameters();//清除参数 } }
效率方面
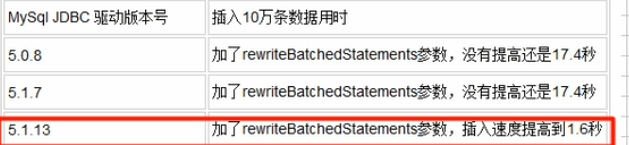
Mysql JDBC 版本 5.1.13开始,效率提高了很多。版本旧的效率不咋滴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号