
序列特征在推荐算法中的应用
简介:行为序列特征在推荐,广告等领域中有着广泛应用,最近几年涌现了很多有关行为序列的研究论文,讲解如何将行为序列应用到实际场景中。但是论文中的实际思想距离落地还有一段距离,因此本文先介绍一些论文中的序列特征的用法,然后介绍一下在大规模分布式推荐系统框架 EasyRec 中如何将序列特征快速落地,提升实际场景效果。
作者:刘国强 - 机器学习PAI团队
序列特征简介
序列特征推荐的目的是利用历史行为序列来预测下一次行为,在现实生活中,行为的前后都存在着极强的关联性,因此,不同于传统推荐任务以静态方式对行为偏好建模,序列特征推荐建模能够捕获动态偏好。例如,某段时间内对运动用品的兴趣较高,另一段时间内则更需要书籍,因此当前偏好可以通过时间顺序的“用户-物品”隐式反馈中推断出来。序列推荐系统不仅可以通过捕捉广义兴趣来提高用户体验,还可以准确预测当前时刻的兴趣,以增强下一时刻的交互效果。
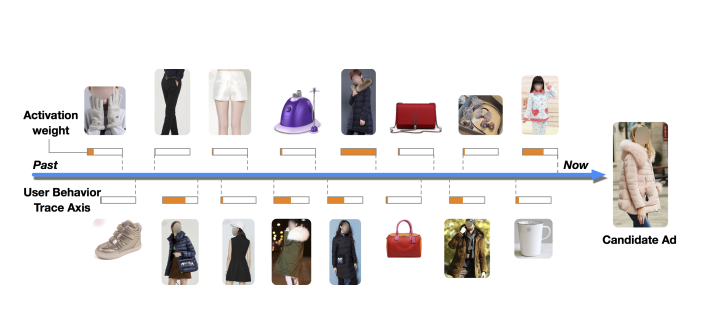
图1 序列特征示例图 (图片来源于论文DIN[9])
如图1所示,在电商推荐中,用户的序列特征包含了和用户发生过交互的各种商品。箭头下方包含了用户的行为序列,上方是 DIN[9] 方法中对发生交互关系的各种商品赋予的不同的权重。然后根据所有的这些特征共同得到最后用户的推荐序列。
序列特征应用方法
按序列发展来看,推荐场景下行为序列建模的模型经历了 pooling, Target Attention, RNN, Capsule, Transformer,图神经网络的发展路线。基于 pooling 模型方法的主要包含有 Youtube , 基于 Target Attention 模型方法主要包含有 DIN,DSTN, 基于 RNN 模型方法主要包含有 GRU4Rec, DIEN, DUPN, HUP, DHAN 等,基于 Capsule 模型方法主要包含有 MIND, ComiRec 等,基于 Transformer 模型方法主要包含有 ATRank, BST, DSIN, TISSA, SDM, KFAtt, DFN, SIM, DMT, AliSearch 等,基于图神经网络的方法主要有 SURGE 等。
1. Pooling 方法
1.1 Youtube
基于 Pooling 模型方法的主要工作是 Youtube[10], 这些方法通常采用 mean, sum 或者 max pooling 的方法聚合行为序列,他们将用户的行为序列看得同等重要。Youtube[10] 通过基于 pooling 的操作建模用户的搜索序列、观看视频序列,应用在 Google Youtube 的视频推荐系统的召回和排序模块中。
在召回阶段的模型如下,使用了观看视频序列、搜索序列:

在排序阶段的模型如下所示,使用了观看视频序列:

2. Target Attention 方法
基于pooling的方法中,将行为序列中的每个物品的重要性看作是相同的,无法区分历史行为中每个物品的重要性。对于不同的待排序物品,用户的兴趣向量也是相同的,无法建模多兴趣。
为了解决这些问题,研究者们提出了基于Target Attention的方法建模行为序列,主要包括 DIN [9], DSTN [11]等。它们通过attention机制建模行为序列中的物品和待排序物品的attention score (即关联程度),作为每个行为的权重,然后再将它们聚合起来。
2.1 DIN
DIN (Deep Interest Network for Click-Through Rate Prediction)[9] 基于 Target attention 建模用户的商品点击行为序列。注意力机制顾名思义,就是模型在预测的时候,对用户不同行为的注意力是不一样的,“相关”的行为历史看重一些,“不相关”的历史甚至可以忽略。那么这样的思想反应到模型中也是直观的。

![]()
上式中, 是用户的 embedding 向量, 是候选广告商品的embedding向量, 是用户 u 的第 i 次行为的embedding向量,因为这里用户的行为就是浏览商品或店铺,所以行为的embedding的向量就是那次浏览的商品或店铺的embedding向量。
因为加入了注意力机制, 从过去 的加和变成了 的加权和, 的权重 就由 与 的关系决定,也就是上式中的 。
基于 pooling 的 base 模型如下图所示:
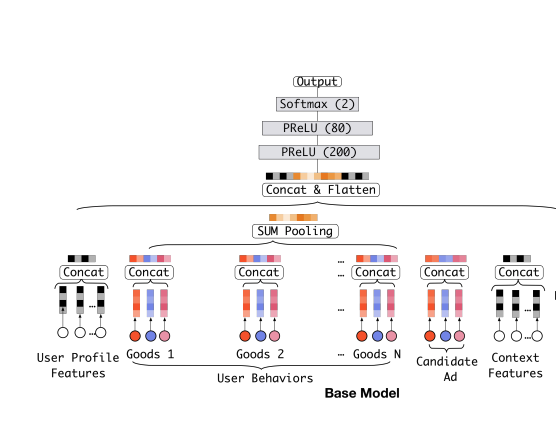

传统的Attention机制中,给定两个 item embedding,比如 u 和 v ,通常是直接做点积 uv 或者 uWv ,其中 W是一个 |u|x|v| 的权重矩阵,但 din 更进一步的改进,在上图右上角的activation unit 中,首先是把u和v以及u v的element wise差值向量合并起来作为输入,然后喂给全连接层,最后得出权重,这样的方法显然损失的信息更少。
2.2 DSTN
DSTN[11] 基于 Target attention 建模用户历史点击广告序列、未点击广告序列、附近的广告序列等信息,应用到神马搜索广告中。
在传统方法当我们要预估对一个广告的点击概率时,只考虑该广告的信息,而忽略了其他广告可能带来的影响。如用户历史点击或者曝光未点击的广告、当前上下文已经推荐过的广告等。因此,将这些广告作为辅助信息,加入到模型中,也许可以提升CTR预估的准确性。
多种行为序列的定义如下图所示:在用户发起搜索后,展示多个广告后用户会有点击、未点击的行为,以及附近的广告信息。
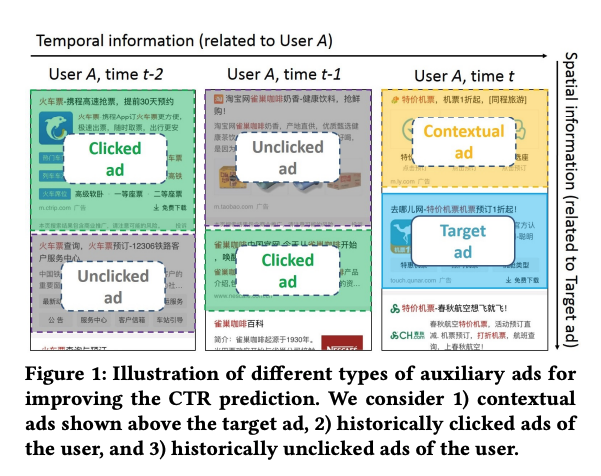
为了将这些信息加入到模型中,必须要注意以下几点:
1)每种类型的辅助广告数量可能相差很多,模型必须适应这些所有可能的情况。
2)辅助的广告信息可能与目标广告是不相关的,因此,模型需要具备提取有效信息,而过滤无用信息的能力。举例来说,用户点击过的广告可能有咖啡广告、服装广告和汽车广告,当目标广告是咖啡相关的广告时,过往点击中咖啡相关的广告可能是起比较大作用的信息。
3)不同类型的辅助广告信息,有时候起到的作用可能是不同的,模型需要能够有能力对此进行判别。
总的来说,就是模型需要有能力有效处理和融合各方面的信息。
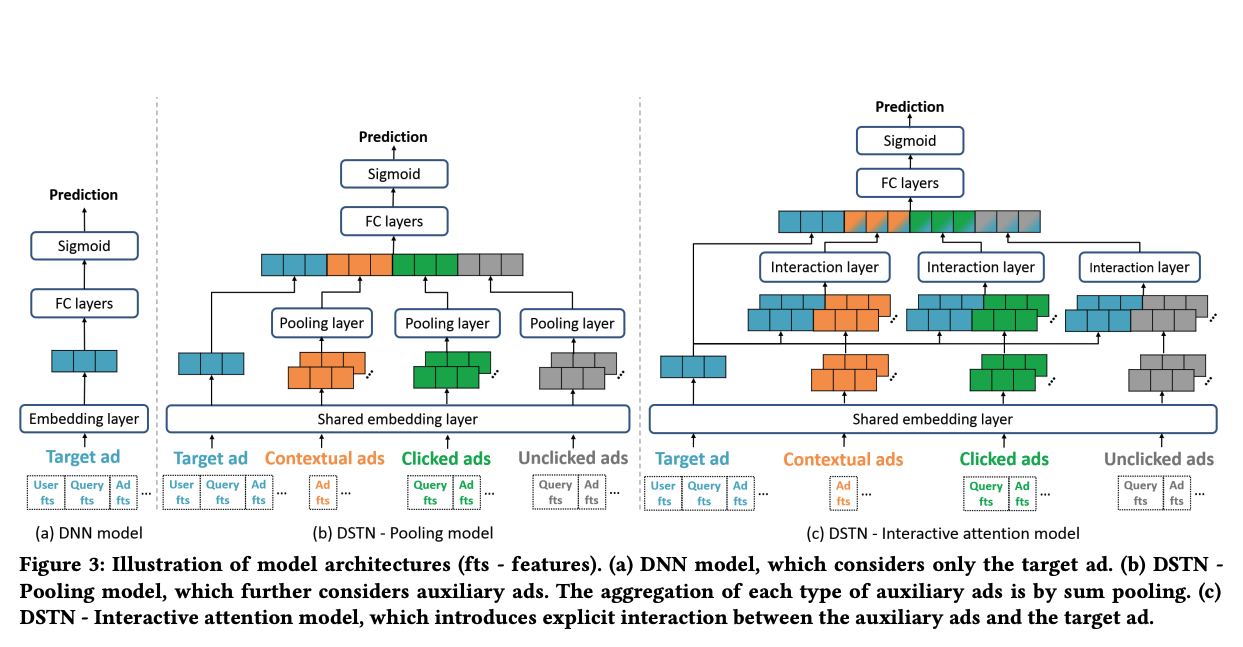
本文提出了DSTN(Deep Spatio-Temporal neural Networks)模型来处理和融合各种辅助广告信息。
DSTN 的模型如下图所示:
3.RNN 方法
基于pooling和attention的方法,不能建模行为序列的时间顺序特性,无法有效建模用户兴趣的不断演化。
为了解决这些问题,研究者们提出了基于RNN建模行为序列,主要包括 DIEN[12], DUPN [13], HUP [14], DHAN [15]等。它们通过RNN建模行为序列的时间顺序特性,能更好地建模用户实时兴趣的变化。
3.1 DIEN
DIEN [12] 基于双层RNN来建模用户的商品点击序列,应用在电商APP推荐广告排序中。同时,在模型提出了基于RNN中的隐藏向量和下一个商品计算辅助loss。第一层RNN,直接用来建模用户的商品点击序列;第二层RNN,基于第一层RNN的结果、待排序广告计算attention,用于RNN的更新。
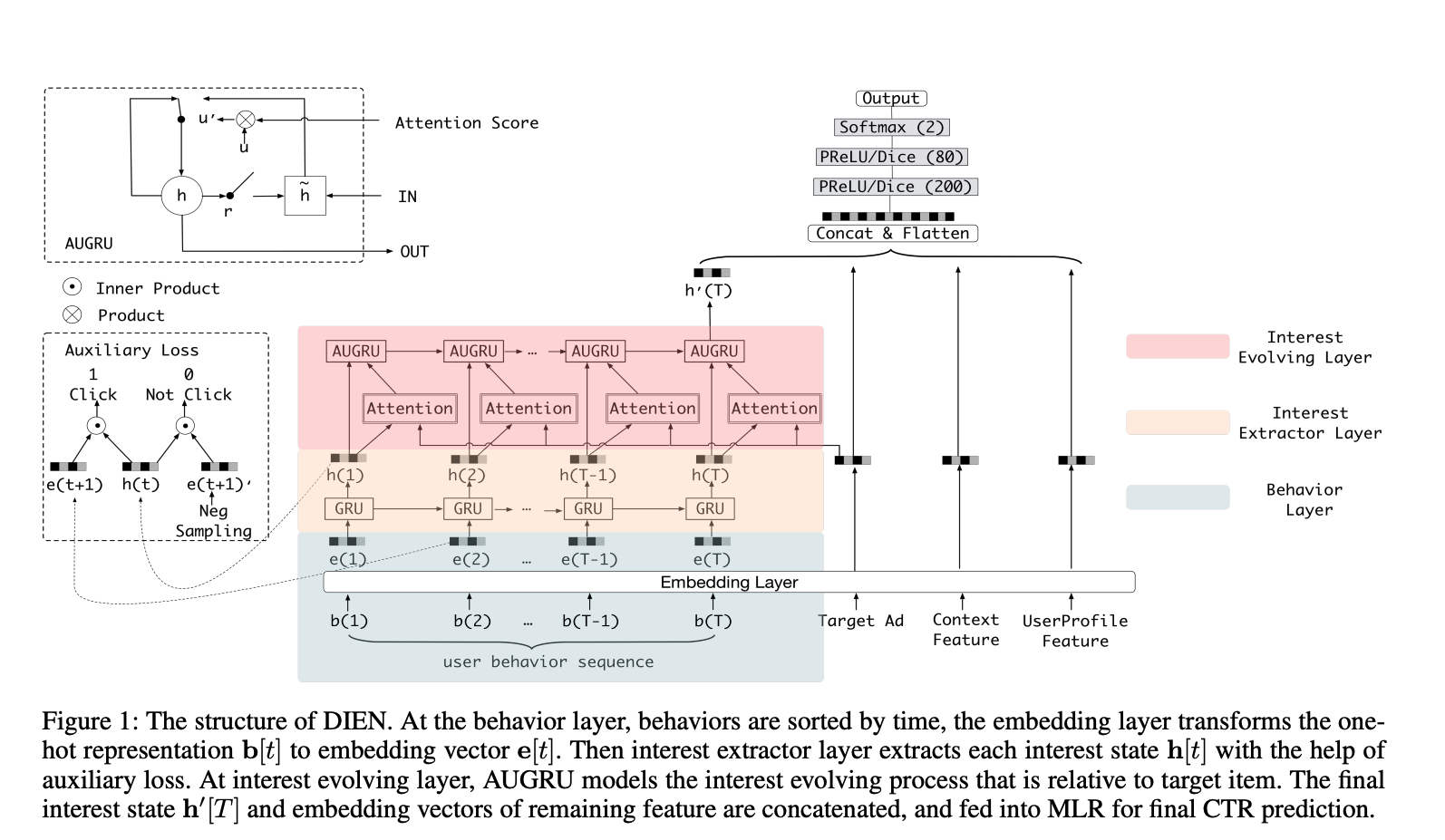
3.2 DUPN
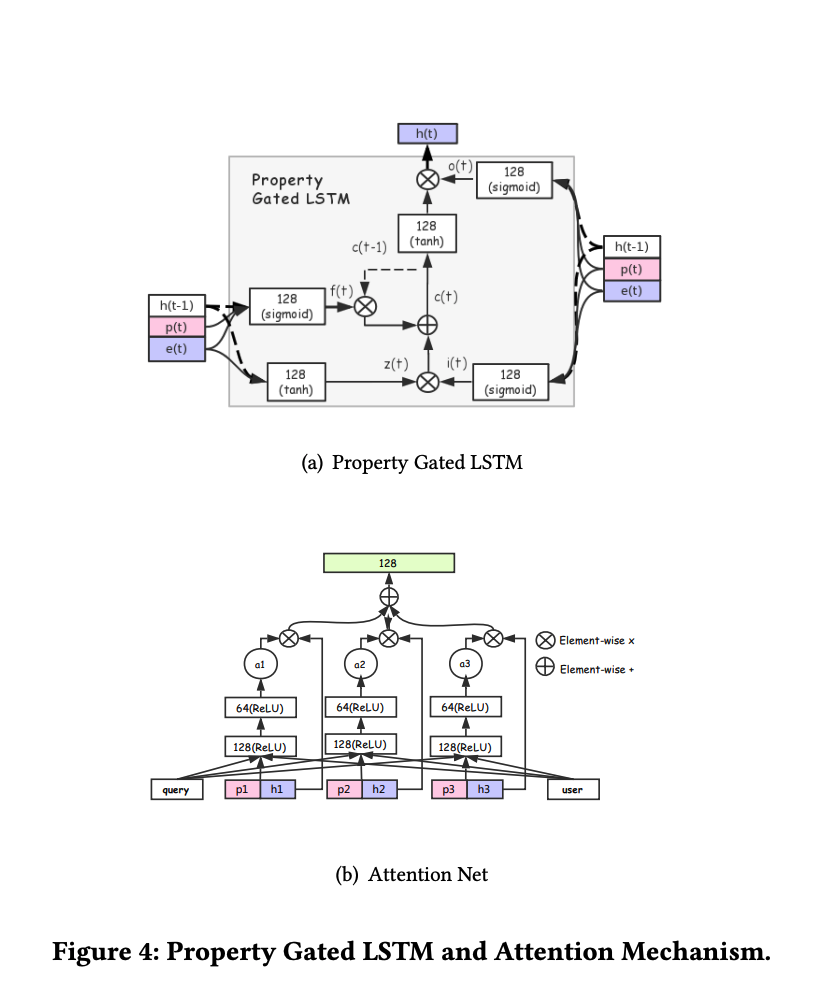
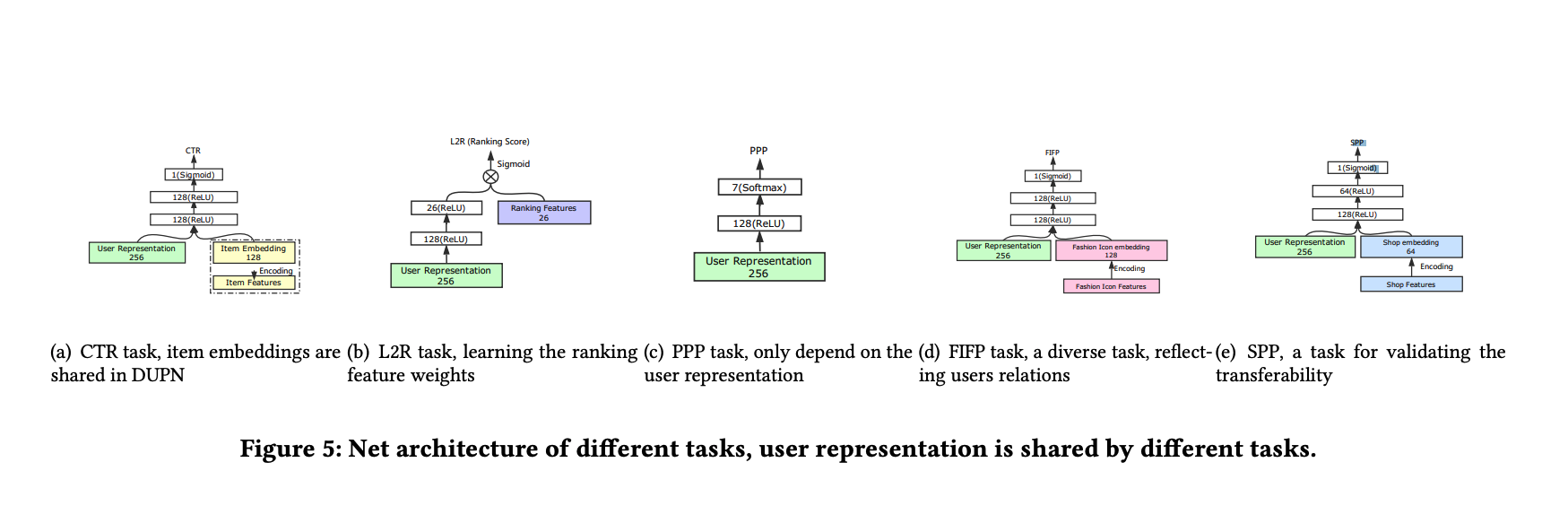
DUPN[13] 基于RNN建模用户的行为序列,再基于attention计算每个行为的权重,得到用户的兴趣向量表示,应用到电商APP搜索中。其整体框架如下图所示:

4. Capsule方法
在召回阶段,基于pooling, attention, RNN等序列模型建模行为序列得到一个用户兴趣向量,然后通过Faiss查找最近的邻居商品,通常召回的商品都很相似,无法满足搜索推荐多样性的需求。
为了解决这些问题,研究者们提出了基于 Capsule 建模行为序列,主要包括 MIND [14], ComiRec [15] 等。它们通过Capsule建模行为序列,通过隐式聚类行为序列,得到多个用户兴趣向量,从而实现召回多个类目的物品的目的。
4.1 MIND
MIND [14] 基于Capsule建模用户的行为序列向量,应用在天猫推荐的召回模块中, 其整体框架如下图所示:
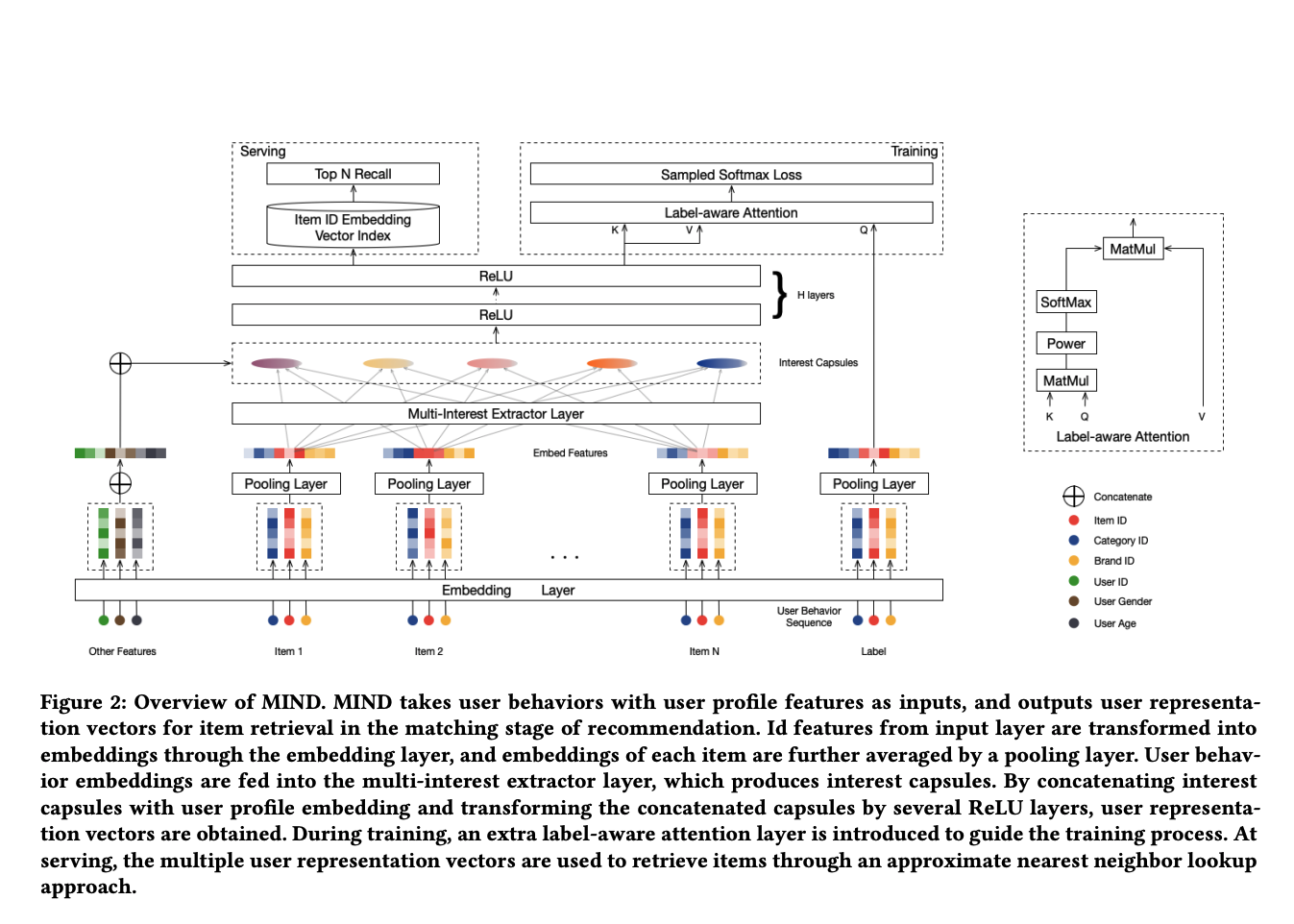
在训练阶段,要进行预测的 label 只有一个 embedding,而用户有一组,没法直接求内积计算匹配度,这里MIND提出了Label-aware Attention,思路跟DIN是一致的,就是根据label的embedding对用户的一组embedding分别求出权重(所谓label-aware),然后对用户的一组embedding求加权和,得到最终的一个embedding。图中右上角是Label-aware Attention的图示,K,V都是用户embedding(矩阵),Q是label embedding(向量),K、Q相乘可以得到不同的用户embedding对label的响应程度,Power对求得的响应做指数运算(可以控制指数的大小),从而控制attention的程度,指数越大,响应高的用户embedding最终权重占比越大。Softmax 对结果进行归一化,最后一步的 MatMul 求得加权和。
MIND 借鉴了Hiton的胶囊网络(Capsule Network),提出了Multi-Interest Extractor Layer来对用户历史行为embedding进行软聚类,算法如下:

4.2 ComiRec
ComiRec [15] 提出基于Capsule或Self-attention来建模行为序列,得到用户的多个兴趣向量,并使用一个可控的多兴趣召回结果聚合模块来平衡召回结果的准确性、多样性,应用到电商APP推荐召回模块中。
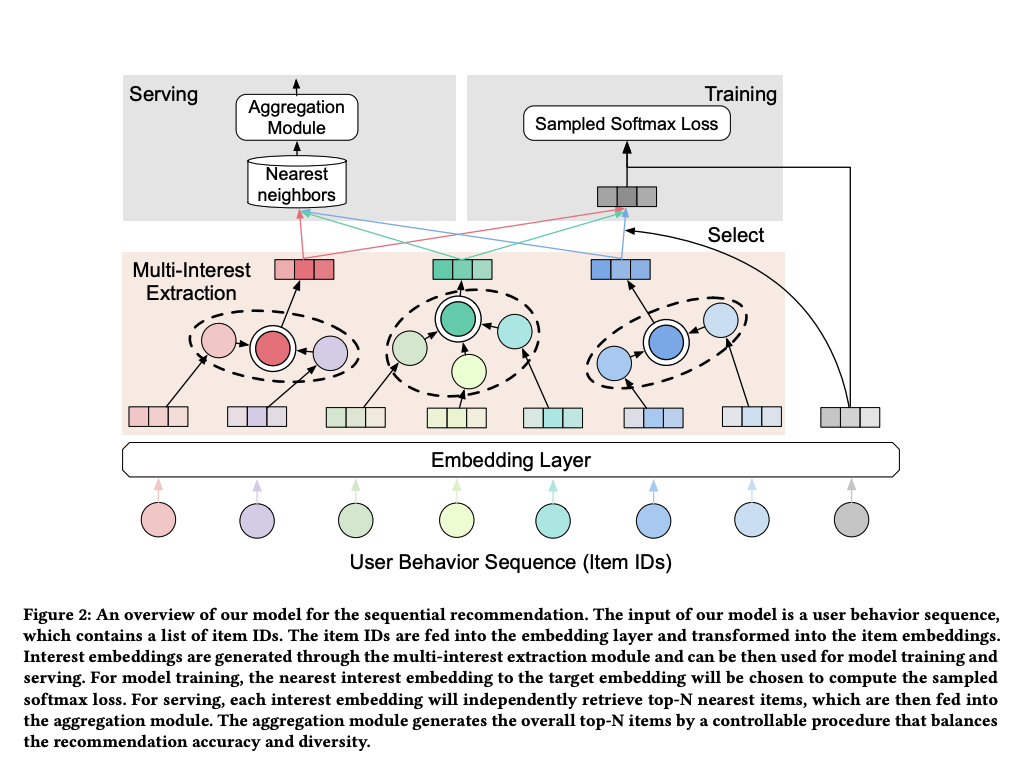
5. Transformer 方法
基于RNN的序列建模模型,无法有效建模长序列、长依赖,以及行为序列内多个行为彼此间的关联关系。
为了解决这些问题,研究者们提出了基于Transformer建模行为序列,主要包括 ATRank [17], BST [4], DSIN [18], TISSA [19], SDM [20], KFAtt [21], DFN [22], SIM [23], DMT [24], AliSearch [17] 等。通过Transformer建模行为序列,逐步成为工业界搜索推荐行为序列建模的主流。
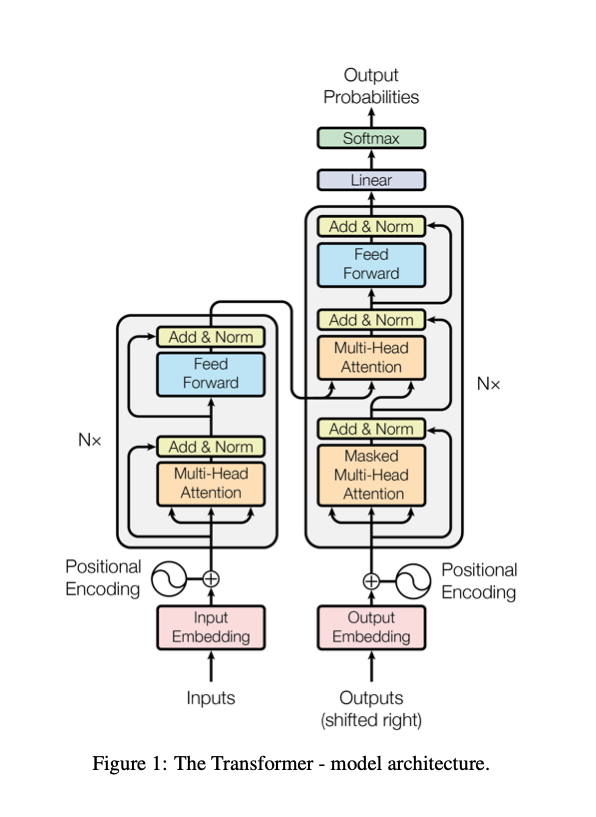
首先介绍一下 Transformer 方法,Transformer 模型的整体架构如下图所示:
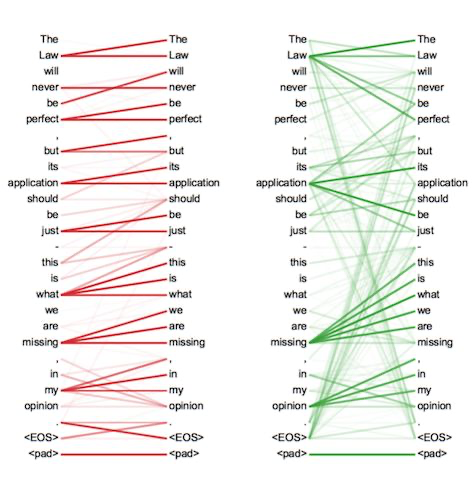
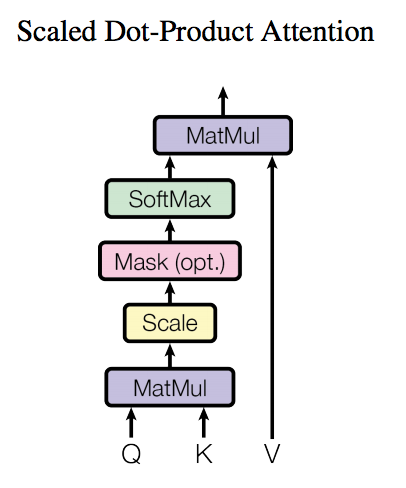

看一个将 Transformer 应用到翻译中的例子。“I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。如下图所示,encoder读入输入数据,利用层层叠加的Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。Decoder也利用类似的Self-Attention机制,但它不仅仅看之前产生的输出的文字,而且还要attend encoder的输出。
5.1 BST
BST[4] 基于Transformer建模行为序列,用于电商APP推荐。 BST 的模型结构主要是由 Embedding 层,Transformer 层与 MLP 层组成,如下图所示:

自注意力机制层使用 self-attention[5] 论文中的多头自注意力机制。
MLP 层使用全连接神经网络。
BST 比较直接的将 Transformer 模型应用到推荐系统中,通过引入 Transformer Layer 来很好的利用了用户历史行为序列信息,最终在 Taobao 的数据集上取得了很好的效果。
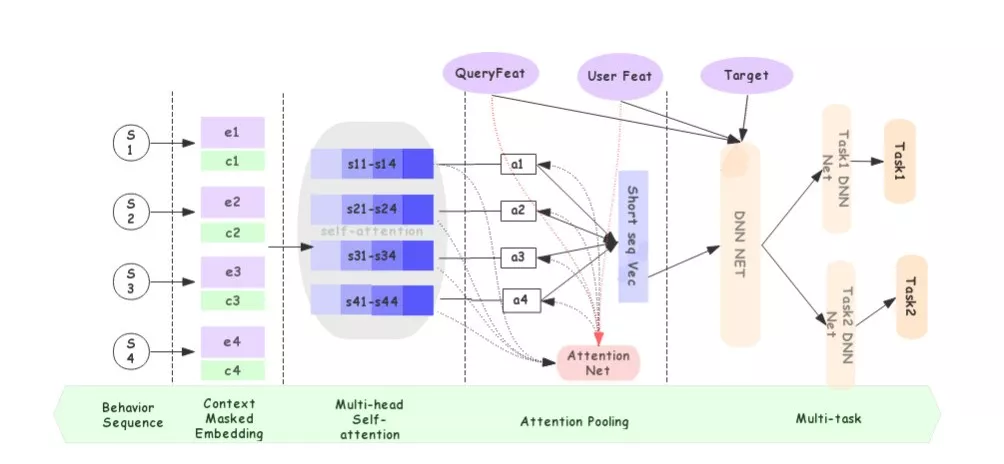
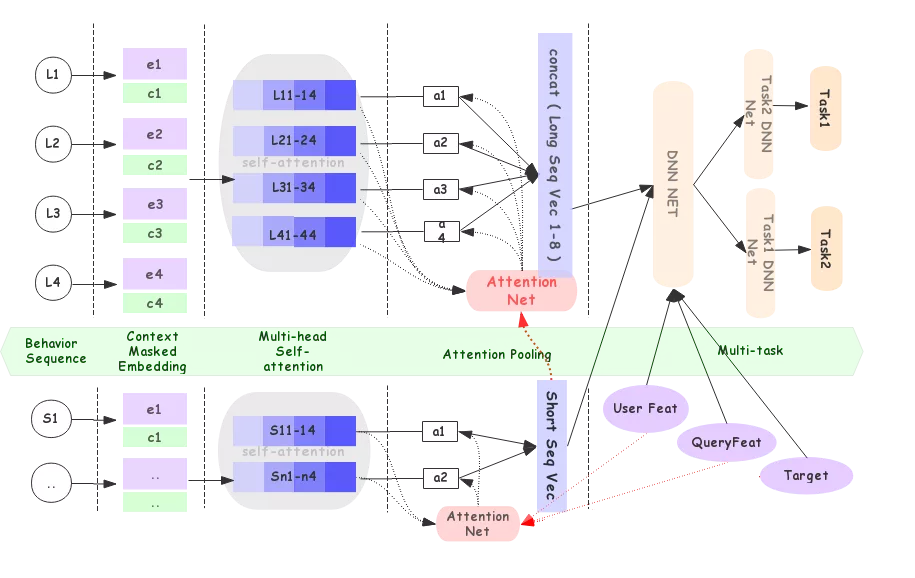
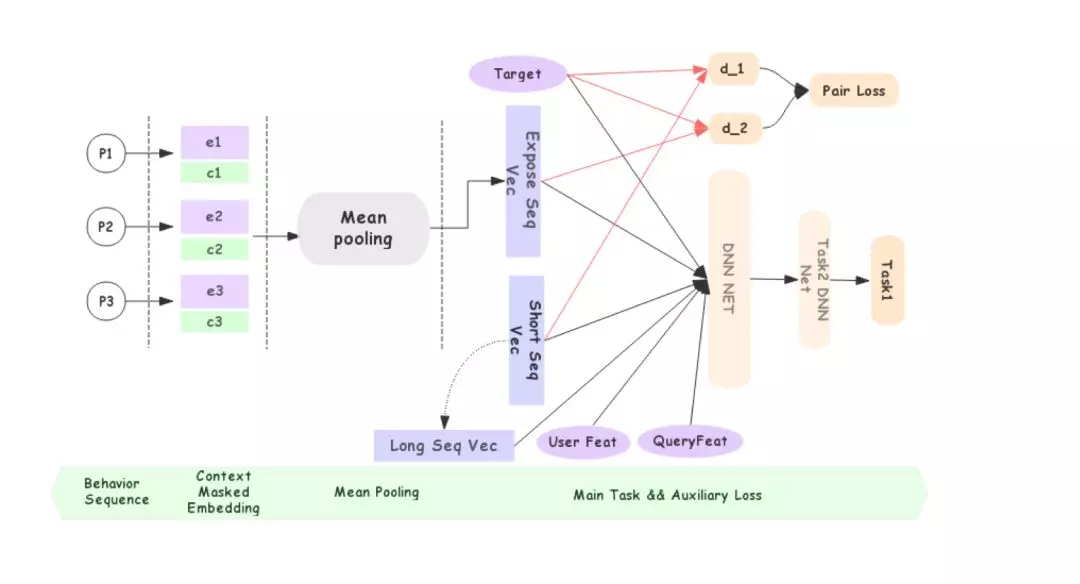
5.2 AliSearch
AliSearch [16]使用Transformer分别建模用户的近期序列(点击,加购,购买的混合序列)、长期点击序列、长期购买序列、近期端上点击序列、近期端上曝光序列,用于电商APP搜索的CTR,CVR预测任务。其模型结构如下图所示:

对于近期序列和端上点击序列,使用self-attention建模,然后使用user和query来解码得到用户近期兴趣向量。 DMT中是推荐系统所以使用target item来解码,AliSearch是搜索任务,所以使用user和query来解码(搜索对相关性要求高、不需要使用每个待排序商品解码效率更高)。
6. 图神经网络方法
6.1 SURGE
在 SIGIR2021 中,Chang 等人将图卷积应用在序列特征建模中,提出 SURGE (SeqUential Recomendation with Graph neural nEtworks) 模型[3]。该模型主要分为四大部分,包括兴趣图构建,兴趣融合图卷积,兴趣图池化,和预测层。模型的框架如下图所示:
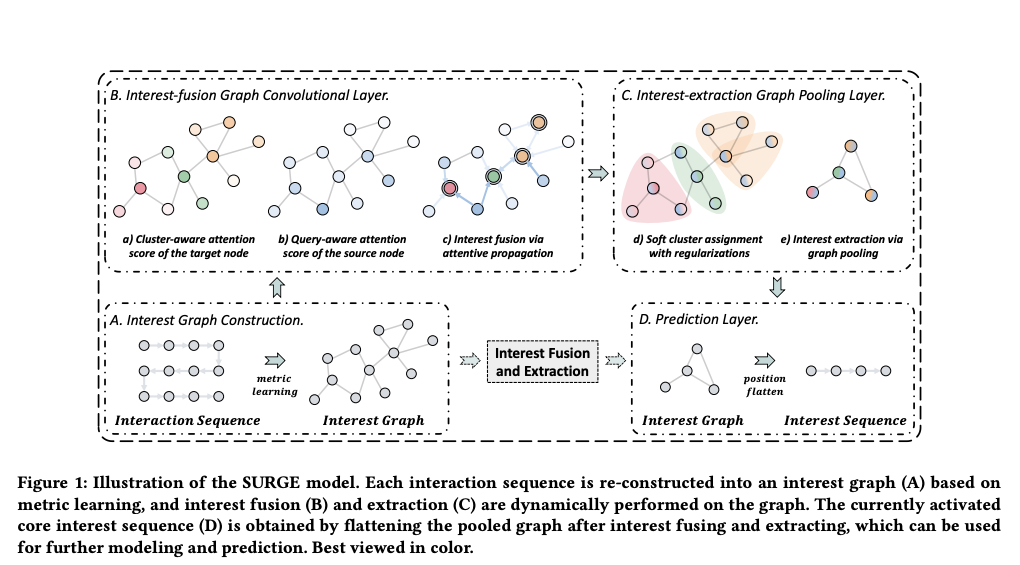
兴趣融合卷积的目的是通过GNN的思想,利用上个阶段A得到的兴趣图 ,通过图卷积操作实现相关项目节点间的信息流通(即局部范围内有差别的邻居聚合)来形成多个代表用户不同兴趣的簇集群,这一过程类似于图表示学习任务常见的节点分类。而为了减轻聚合过程中产生的噪声,作者提出两种注意力,包括簇意识注意力和搜索意识注意力。
兴趣图池化有点类似于卷积神经网络中的池化操作,通过学习一个集群指定矩阵,再通过矩阵相乘的到不同的兴趣集群表示,然后利用图中每个节点的重要性分数,得到全局图表示。
预测层对于上一阶段得到的兴趣图进行位置平整的到精简版的兴趣序列,利用 AUGRU(GRU with attentional update gate) 输出用户层的表示,最后将用户表示,兴趣图表示以及下一个需要预测的项目表示进行级联(concat) 后接 MLP 层,得到最后 CTR 预估的结果。
在 EasyRec 中将序列特征快速落地
接下来以 DIN 模型为例介绍将序列特征快速落地。
EasyRec 介绍
EasyRec[1] 是阿里云计算平台机器学习PAI团队开源的大规模分布式推荐算法框架,github 地址为:
EasyRec 环境配置及运行
使用 EasyRec 可以见 EasyRec 文档[2], 快速运行 EasyRec 可以见教程:
序列特征数据前期准备
序列特征,是多个特征的集合,组成序列。构建序列特征一般分为两步,第一步是构建原始序列特征。以实际工作为例,原始序列特征一般用 ":" 来分隔特征名和值,用 "#" 来分隔多个特征,用 ";" 来分隔多个序列。
第二阶段是预处理。预处理的目的是要处理成 EasyRec 可以接受的处理方式,预处理后每个单独的序列特征要放在一起。如对于 item__svid 特征,就要把序列中的所有的 item__svid 特征都要挑出来,放在一起,可以用 "|" 分隔,在 EasyRec 中配置好后就可以进行训练。此处还要注意要保证离线在线一致性。
在 Easyrec 中使用序列特征
序列特征在 EasyRec 中有专门的示例 config ,可以查看位于 samples/model_config/din_on_taobao.config 的配置文件,在配置文件中序列特征可用如下表示:
feature_configs : {
input_names: 'tag_brand_list'
feature_type: SequenceFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 16
}
feature_configs : {
input_names: 'tag_category_list'
feature_type: SequenceFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 16
}
其对应的两个特征的原始输入形式为:
4281|4281|4281|4281|4281|4281|4281|4281|4281|4281|4281|4281|4281|4281|4526|4526,283837|283837|283837|283837|283837|283837|283837|283837|283837|283837|283837|283837|283837|283837|367594|367594
这个配置文件使用了 DIN 模型,具体细节可以参考对应的论文[6]。 离线训练完成后,可以再参考文档[8]进行导出操作,部署到线上,快速应用到推荐场景中。
参考文献
[1] EasyRec :
[2] EasyRec 文档:
[3] Chang J, Gao C, Zheng Y, et al. Sequential Recommendation with Graph Neural Networks[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 378-387.
[4] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commerce recommendation in alibaba[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[5] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[6] Yu Z, Lian J, Mahmoody A, et al. Adaptive User Modeling with Long and Short-Term Preferences for Personalized Recommendation[C]//IJCAI. 2019: 4213-4219.
[7] Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]//Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 2008: 426-434.
[8] EasyRec 导出文档:
[9] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1059-1068.
[10] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Recsys'16
[11] Ouyang, Wentao, Xiuwu Zhang, Li Li, Heng Zou, Xin Xing, Zhaojie Liu, and Yanlong Du. "Deep spatio-temporal neural networks for click-through rate prediction." KDD'19.
[12] Zhou, Guorui, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. "Deep interest evolution network for click-through rate prediction." AAAI'19.
[13] Ni, Yabo, Dan Ou, Shichen Liu, Xiang Li, Wenwu Ou, Anxiang Zeng, and Luo Si. "Perceive your users in depth: Learning universal user representations from multiple e-commerce tasks." KDD'18.
[14] Li, Chao, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Huan Zhao, Pipei Huang, Guoliang Kang, Qiwei Chen, Wei Li, and Dik Lun Lee. "Multi-interest network with dynamic routing for recommendation at Tmall." CIKM'19.
[15] Cen, Yukuo, Jianwei Zhang, Xu Zou, Chang Zhou, Hongxia Yang, and Jie Tang. "Controllable Multi-Interest Framework for Recommendation." KDD'20.
[16] [AliSearch]:
[17] Zhou, Chang, Jinze Bai, Junshuai Song, Xiaofei Liu, Zhengchao Zhao, Xiusi Chen, and Jun Gao. "Atrank: An attention-based user behavior modeling framework for recommendation." AAAI'18.
[18] Feng, Yufei, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, and Keping Yang. "Deep session interest network for click-through rate prediction." IJCAI'19.
[19] Lei, Chenyi, Shouling Ji, and Zhao Li. "Tissa: A time slice self-attention approach for modeling sequential user behaviors." WWW'19.
[20] Lv, Fuyu, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wilfred Ng. "SDM: Sequential deep matching model for online large-scale recommender system." CIKM'19.
[21] Liu, Hu, Jing Lu, Xiwei Zhao, Sulong Xu, Hao Peng, Yutong Liu, Zehua Zhang et al. "Kalman Filtering Attention for User Behavior Modeling in CTR Prediction." NIPS'20.
[22] Xie, Ruobing, Cheng Ling, Yalong Wang, Rui Wang, Feng Xia, and Leyu Lin. "Deep Feedback Network for Recommendation." IJCAI'20.
[23] Pi, Qi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. "Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction." CIKM'20.
[24] Gu, Yulong, Zhuoye Ding, Shuaiqiang Wang, Lixin Zou, Yiding Liu, and Dawei Yin. "Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender Systems." CIKM'20.
本文为阿里云原创内容,未经允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号