
短视频app源代码,利用一级缓存提升查询效率
短视频app源代码,利用一级缓存提升查询效率
一. 一级缓存机制展示
在Mybatis中如果多次执行完全相同的SQL语句时,Mybatis提供了一级缓存机制用于提高查询效率。一级缓存是默认开启的,如果想要手动配置,需要在Mybatis配置文件中加入如下配置。
<settings>
<setting name="localCacheScope" value="SESSION"/>
</settings>
其中localCacheScope可以配置为SESSION(默认)或者STATEMENT,含义如下所示。

下面以一个例子对Mybatis的一级缓存机制进行演示和说明。首先开启日志打印,然后关闭二级缓存,并将一级缓存作用范围设置为SESSION,配置如下。
<settings>
<setting name="logImpl" value="STDOUT_LOGGING" />
<setting name="cacheEnabled" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
</settings>
映射接口如下所示。
public interface BookMapper {
Book selectBookById(int id);
}
映射文件如下所示。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
</mapper>
Mybatis的执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession = sqlSessionFactory.openSession(false);
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
System.out.println(bookMapper.selectBookById(1));
System.out.println(bookMapper.selectBookById(1));
System.out.println(bookMapper.selectBookById(1));
}
}
在执行代码中,连续执行了三次查询操作,看一下日志打印,如下所示。
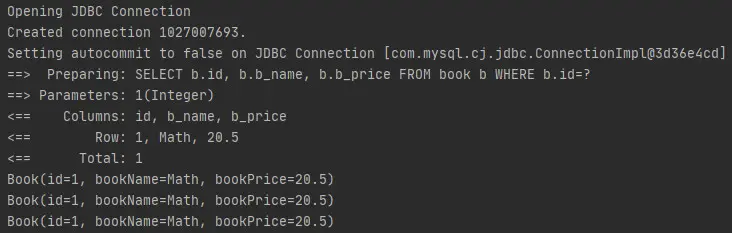
可以知道,只有第一次查询时和数据库进行了交互,后面两次查询均是从一级缓存中查询的数据。现在往映射接口和映射文件中加入更改数据的逻辑,如下所示。
public interface BookMapper {
Book selectBookById(int id);
// 根据id更改图书价格
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org// DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
<insert id="updateBookPriceById">
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
</insert>
</mapper>
执行的操作为先执行一次查询操作,然后执行一次更新操作并提交事务,最后再执行一次查询操作,执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession = sqlSessionFactory.openSession(false);
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
System.out.println(bookMapper.selectBookById(1));
System.out.println("Change database.");
bookMapper.updateBookPriceById(1, 22.5f);
sqlSession.commit();
System.out.println(bookMapper.selectBookById(1));
}
}
执行结果如下所示。
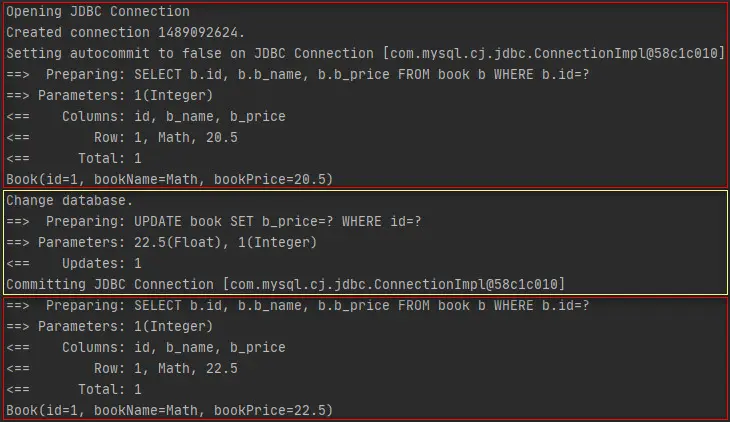
通过上述结果可以知道,在执行更新操作之后,再执行查询操作时,是直接从数据库查询的数据,并未使用一级缓存,即在一个会话中,对数据库的增,删,改操作,均会使一级缓存失效。
现在在执行代码中创建两个会话,先让会话1执行一次查询操作,然后让会话2执行一次更新操作并提交事务,最后让会话1再执行一次相同的查询。执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
System.out.println("Change database.");
bookMapper2.updateBookPriceById(1, 22.5f);
sqlSession2.commit();
System.out.println(bookMapper1.selectBookById(1));
}
}
执行结果如下所示。
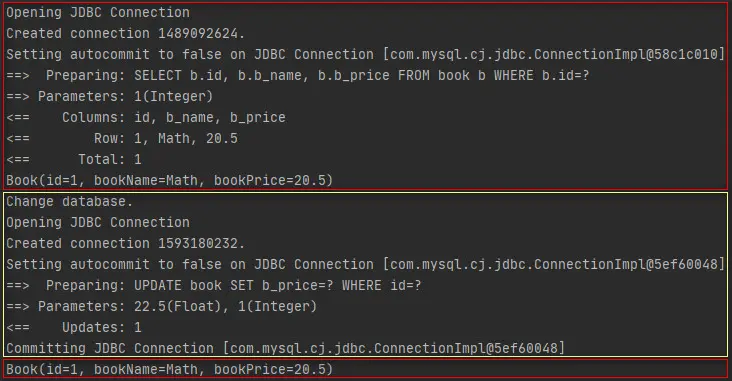
上述结果表明,会话1的第一次查询是直接查询的数据库,然后会话2执行了一次更新操作并提交了事务,此时数据库中id为1的图书的价格已经变更为了22.5,紧接着会话1又做了一次查询,但查询结果中的图书价格为20.5,说明会话1的第二次查询是从缓存获取的查询结果。所以在这里可以知道,Mybatis中每个会话均会维护一份一级缓存,不同会话之间的一级缓存各不影响。
在本小节最后,对Mybatis的一级缓存机制做一个总结,如下所示。
Mybatis的一级缓存默认开启,且默认作用范围为SESSION,即一级缓存在一个会话中生效,也可以通过配置将作用范围设置为STATEMENT,让一级缓存仅针对当前执行的SQL语句生效;
在同一个会话中,执行增,删,改操作会使本会话中的一级缓存失效;
不同会话持有不同的一级缓存,本会话内的操作不会影响其它会话内的一级缓存。
本小节将对一级缓存对应的Mybatis源码进行讨论。在Mybatis源码-Executor的执行过程中已经知道,禁用二级缓存的情况下,执行查询操作时,调用链如下所示。

在BaseExecutor中有两个重载的query()方法,下面先看第一个query()方法的实现,如下所示。
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
// 获取Sql语句
BoundSql boundSql = ms.getBoundSql(parameter);
// 生成CacheKey
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用重载的query()方法
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
在上述query()方法中,先会在MappedStatement中获取SQL语句,然后生成CacheKey,这个CacheKey实际就是本会话一级缓存中缓存的唯一标识,CacheKey类图如下所示。
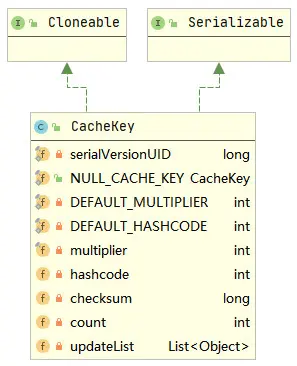
CacheKey中的multiplier,hashcode,checksum,count和updateList字段用于判断CacheKey之间是否相等,这些字段会在CacheKey的构造函数中进行初始化,如下所示。
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLIER;
this.count = 0;
this.updateList = new ArrayList<>();
}
同时hashcode,checksum,count和updateList字段会在CacheKey的update()方法中被更新,如下所示。
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
主要逻辑就是基于update()方法的入参计算并更新hashcode,checksum和count的值,然后再将入参添加到updateList集合中。同时,在CacheKey重写的equals()方法中,只有当hashcode相等,checksum相等,count相等,以及updateList集合中的元素也全都相等时,才算做两个CacheKey是相等。
回到上述的BaseExecutor中的query()方法,在其中会调用createCacheKey()方法生成CacheKey,其部分源码如下所示。
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, BoundSql boundSql) {
......
// 创建CacheKey
CacheKey cacheKey = new CacheKey();
// 基于MappedStatement的id更新CacheKey
cacheKey.update(ms.getId());
// 基于RowBounds的offset更新CacheKey
cacheKey.update(rowBounds.getOffset());
// 基于RowBounds的limit更新CacheKey
cacheKey.update(rowBounds.getLimit());
// 基于Sql语句更新CacheKey
cacheKey.update(boundSql.getSql());
......
// 基于查询参数更新CacheKey
cacheKey.update(value);
......
// 基于Environment的id更新CacheKey
cacheKey.update(configuration.getEnvironment().getId());
return cacheKey;
}
所以可以得出结论,判断CacheKey是否相等的依据就是MappedStatement id + RowBounds offset + RowBounds limit + SQL + Parameter + Environment id相等。
获取到CacheKey后,会调用BaseExecutor中重载的query()方法,如下所示。
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// queryStack是BaseExecutor的成员变量
// queryStack主要用于递归调用query()方法时防止一级缓存被清空
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 先从一级缓存中根据CacheKey命中查询结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 处理存储过程相关逻辑
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 未命中,则直接查数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (BaseExecutor.DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 如果一级缓存作用范围是STATEMENT时,每次query()执行完毕就需要清空一级缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
上述query()方法中,会先根据CacheKey去缓存中命中查询结果,如果命中到查询结果并且映射文件中CURD标签上的statementType为CALLABLE,则会先在handleLocallyCachedOutputParameters()方法中处理存储过程相关逻辑然后再将命中的查询结果返回,如果未命中到查询结果,则会直接查询数据库。上述query()方法中还使用到了BaseExecutor的queryStack字段,主要防止一级缓存作用范围是STATEMENT并且还存在递归调用query()方法时,在递归尚未终止时就将一级缓存删除,如果不存在递归调用,那么一级缓存作用范围是STATEMENT时,每次查询结束后,都会清空缓存。下面看一下BaseExecutor中的一级缓存localCache,其实际是PerpetualCache,类图如下所示。
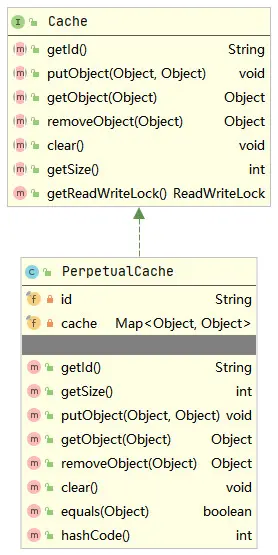
所以PerpetualCache的内部主要是基于一个Map(实际为HashMap)用于数据存储。现在回到上面的BaseExecutor的query()方法中,如果没有在一级缓存中命中查询结果,则会直接查询数据库,queryFromDatabase()方法如下所示。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 调用doQuery()进行查询操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将查询结果添加到一级缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
// 返回查询结果
return list;
}
queryFromDatabase()方法中和一级缓存相关的逻辑就是在查询完数据库后,会将查询结果以CacheKey作为唯一标识缓存到一级缓存中。
Mybatis中如果是执行增,改和删操作,并且在禁用二级缓存的情况下,均会调用到BaseExecutor的update()方法,如下所示。
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource())
.activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 执行操作前先清空缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
所以Mybatis中的一级缓存在执行了增,改和删操作后,会被清空即失效。
最后,一级缓存的使用流程可以用下图进行概括。
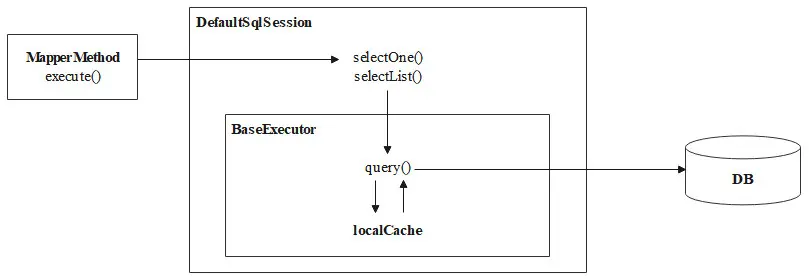
以上就是短视频app源代码,利用一级缓存提升查询效率, 更多内容欢迎关注之后的文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号