


java技术栈
1 java基础:
1.1 算法
- 1.1 排序算法:直接插入排序、希尔排序、冒泡排序、快速排序、直接选择排序、堆排序、归并排序、基数排序
- 1.2 二叉查找树、红黑树、B树、B+树、LSM树(分别有对应的应用,数据库、HBase)
- 1.3 BitSet解决数据重复和是否存在等问题
1.2 基本
- 2.1 字符串常量池的迁移
- 2.2 字符串KMP算法
- 2.3 equals和hashcode
-
1、equals方法用于比较对象的内容是否相等(覆盖以后)
2、hashcode方法只有在集合中用到
3、当覆盖了equals方法时,比较对象是否相等将通过覆盖后的equals方法进行比较(判断对象的内容是否相等)。
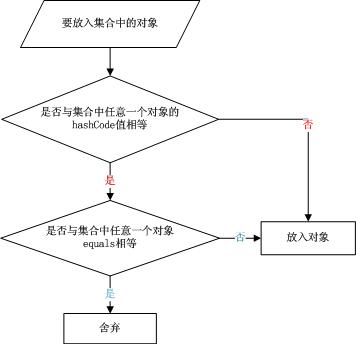
4、将对象放入到集合中时,首先判断要放入对象的hashcode值与集合中的任意一个元素的hashcode值是否相等,如果不相等直接将该对象放入集合中。如果hashcode值相等,然后再通过equals方法判断要放入对象与集合中的任意一个对象是否相等,如果equals判断不相等,直接将该元素放入到集合中,否则不放入。
5、将元素放入集合的流程图:
![]()
-
- 2.4 泛型、异常、反射
- 2.5 string的hash算法
- 设计高效算法往往需要使用Hash表,O(1)级的查找速度是任何别的算法无法比拟的。
所谓Hash,一般是一个整数,通过某种算法,可以把一个字符串"pack"成一个整数,这个数称为Hash,当然,一个整数是无法对应一个字符串的。
所以Hash函数是Hash表最核心的部分,对于一个Hash函数,评价其优劣的标准应为随机性或离散性,即对任意一组标本,进入Hash表每一个单元(cell)之概率的平均程度,因为这个概率越平均,两个字符串计算出的Hash值相等hash collision的可能越小,数据在表中的分布就越平均,表的空间利用率就越高。
- 设计高效算法往往需要使用Hash表,O(1)级的查找速度是任何别的算法无法比拟的。
- 2.6 hash冲突的解决办法:拉链法
-
拉链法
(1)拉链法解决冲突的方法
拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于 1,但一般均取α≤1。
【例】设有 m = 5 , H(K) = K mod 5 ,关键字值序例 5 , 21 , 17 , 9 , 15 , 36 , 41 , 24 ,按外链地址法所建立的哈希表如下图所示:
![]()
(2)拉链法的优点
与开放定址法相比,拉链法有如下几个优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
(3)拉链法的缺点
拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
-
- 2.7 foreach循环的原理
-
- 对于list编译器会调用Iterable接口的 iterator方法来循环遍历数组的元素,iterator方法中是调用Iterator接口的的 next()和hasNext()方法来做循环遍历。java中有一个叫做迭代器模式的设计模式,这个其实就是对迭代器模式的一个实现。
- 对于数组,就是转化为对数组中的每一个元素的循环引用
-
- 2.8 static、final、transient等关键字的作用
-
static 和final
static 静态修饰关键字,可以修饰 变量,程序块,类的方法;
当你定义一个static的变量的时候jvm会将将其分配在内存堆上,所有程序对它的引用都会指向这一个地址而不会重新分配内存;
修饰一个程序块的时候(也就是直接将代码写在static{...}中)时候,虚拟机就会优先加载静态块中代码,这主要用于系统初始化;
当修饰一个类方法时候你就可以直接通过类来调用而不需要新建对象。
final 只能赋值一次;修饰变量、方法及类,
当你定义一个final变量时,jvm会将其分配到常量池中,程序不可改变其值;当你定义一个方法时,改方法在子类中将不能被重写;当你修饰一个类时,该类不能被继承。
static和final使用范围:类、方法、变量。
2.区别和联系:
2.1.static 含义:静态的,被 static 修饰的方法和属性只属于类不属于类的任何对象。
2.2.static 用法:
2.2.1.static 可以修饰【内部类】、方法和成员变量。
2.2.2.static【不可以修饰外部类】、【不可以修饰局部变量】(因为 static 本身就是定义为类级别的,所以局部级别的变量是不可以用 static 修饰的)。
2.3 final 含义:【只能赋值一次】的。
2.2.final 用法:
2.2.1.final 修饰属性,表示属性【只能赋值一次】,(1)基本类型:值不能被修改;(2)引用类型:引用不可以被修改该。
2.2.2.final 修饰方法,表示方法不可以重写,但是可以被子类访问(如果方法不是 private 类型话)。
2.2.2.final 修饰类,表示类不可以被继承。
3.联合使用 static final3.1.适用范围:
3.1.2.两者范围的交集,所以只能修饰:成员变量、方法、内部类。
3.2.含义:也是二者交集:
3.2.1.方法:属于类的方法且不可以被重写。
3.2.2.成员变量:属于类的变量且只能赋值一次。
3.2.3.内部类:属于外部类,且不能被继承
transient
类型修饰符,只能用来修饰字段,如果用transient声明一个实例变量,当对象存储时,它的值不需要维持。换句话来说就是,用transient关键字标记的成员变量不参与序列化过程。
-
- 2.9 volatile关键字的底层实现原理
-
volatile
volatile也是变量修饰符,只能用来修饰变量。volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。在此解释一下Java的内存机制:
Java使用一个主内存来保存变量当前值,而每个线程则有其独立的工作内存。线程访问变量的时候会将变量的值拷贝到自己的工作内存中,这样,当线程对自己工作内存中的变量进行操作之后,就造成了工作内存中的变量拷贝的值与主内存中的变量值不同。
Java语言规范中指出:为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与共享成员变量的原始值对比。
这样当多个线程同时与某个对象交互时,就必须要注意到要让线程及时的得到共享成员变量的变化。
而volatile关键字就是提示VM:对于这个成员变量不能保存它的私有拷贝,而应直接与共享成员变量交互。
使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,不必使用。
由于使用volatile屏蔽掉了VM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
-
- 2.10 Collections.sort方法使用的是哪种排序方法
-
Collections是个服务于Collection的工具类(静态的),它里面定义了一些集合可以用到的方法。
本文演示了Collections类里sort()的两个方法。第一种只需传入被排序的集合,便会为它自然排序。但有时我们需要自定义排序的方式,这是我们就得定义一个比较器,里面定义我们要排序的方式,调用sort()时,把被排序的集合和比较器同时传入,就可以按照自定义的方式排序了。
-
- 2.11 Future接口,常见的线程池中的FutureTask实现等
- 2.12 string的intern方法的内部细节,jdk1.6和jdk1.7的变化以及内部cpp代码StringTable的实现

1.3 设计模式
- 单例模式
- 工厂模式
- 装饰者模式
- 观察者设计模式
- ThreadLocal设计模式
- 。。。
1.4 正则表达式
- 4.1 捕获组和非捕获组
- http://www.360doc.com/content/12/0123/05/820209_181153675.shtml
- 4.2 贪婪,勉强,独占模式
-
正则表达式中匹配的三种量词:贪婪(Greedy)、勉强(Reluctant)、独占(Possessive)
贪婪 非贪婪(?) 独占(+)
X? X?? X?+
X* X*? X*+
X+ X+? X++
X{n} X{n}? X{n}+
X{n,} X{n,}? X{n,}+
X{n,m} X{n,m}? X{n,m}+Greedy:贪婪
匹配最长。在贪婪量词模式下,正则表达式会尽可能长地去匹配符合规则的字符串,且会回溯。Reluctant :非贪婪
匹配最短。在非贪婪量词模式下,正则表达式会匹配尽可能短的字符串。Possessive :独占
同贪婪一样匹配最长。不过在独占量词模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。
-
1.5 java内存模型以及垃圾回收算法
-
5.1 类加载机制,也就是双亲委派模型
- 见JVM P229
-
5.2 java内存分配模型(默认HotSpot)
线程共享的:堆区、永久区 线程独享的:虚拟机栈、本地方法栈、程序计数器
-
5.3 内存分配机制:年轻代(Eden区、两个Survivor区)、年老代、永久代以及他们的分配过程
-
5.4 强引用、软引用、弱引用、虚引用与GC
-
5.5 happens-before规则
-
5.6 指令重排序、内存栅栏
-
5.7 Java 8的内存分代改进
-
5.8 垃圾回收算法:
标记-清除(不足之处:效率不高、内存碎片)
复制算法(解决了上述问题,但是内存只能使用一半,针对大部分对象存活时间短的场景,引出了一个默认的8:1:1的改进,缺点是仍然需要借助外界来解决可能承载不下的问题)
标记整理
-
5.8 常用垃圾收集器:
新生代:Serial收集器、ParNew收集器、Parallel Scavenge 收集器
老年代:Serial Old收集器、Parallel Old收集器、CMS(Concurrent Mark Sweep)收集器、 G1 收集器(跨新生代和老年代)
-
5.9 常用gc的参数:-Xmn、-Xms、-Xmx、-XX:MaxPermSize、-XX:SurvivorRatio、-XX:-PrintGCDetails
-
5.10 常用工具: jps、jstat、jmap、jstack、图形工具jConsole、Visual VM、MAT
1.6 锁以及并发容器的源码
- 6.1 synchronized和volatile理解
- 6.2 Unsafe类的原理,使用它来实现CAS。因此诞生了AtomicInteger系列等
- 6.3 CAS可能产生的ABA问题的解决,如加入修改次数、版本号
- 6.4 同步器AQS的实现原理
- 6.5 独占锁、共享锁;可重入的独占锁ReentrantLock、共享锁 实现原理
- 6.6 公平锁和非公平锁
- 6.7 读写锁 ReentrantReadWriteLock的实现原理
- 6.8 LockSupport工具
- 6.9 Condition接口及其实现原理
- 6.10 HashMap、HashSet、ArrayList、LinkedList、HashTable、ConcurrentHashMap、TreeMap的实现原理
- 6.11 HashMap的并发问题
- 6.12 ConcurrentLinkedQueue的实现原理
- 6.13 Fork/Join框架
- 6.14 CountDownLatch和CyclicBarrier
1.7 线程池源码
- 7.1 内部执行原理
- 7.2 各种线程池的区别
2 web方面:
2.1 SpringMVC的架构设计
- 1.1 servlet开发存在的问题:映射问题、参数获取问题、格式化转换问题、返回值处理问题、视图渲染问题
- 1.2 SpringMVC为解决上述问题开发的几大组件及接口:HandlerMapping、HandlerAdapter、HandlerMethodArgumentResolver、HttpMessageConverter、Converter、GenericConverter、HandlerMethodReturnValueHandler、ViewResolver、MultipartResolver
- 1.3 DispatcherServlet、容器、组件三者之间的关系
- 1.4 叙述SpringMVC对请求的整体处理流程
- 1.5 SpringBoot
2.2 SpringAOP源码
-
2.1 AOP的实现分类:编译期、字节码加载前、字节码加载后三种时机来实现AOP
-
2.2 深刻理解其中的角色:AOP联盟、aspectj、jboss AOP、Spring自身实现的AOP、Spring嵌入aspectj。特别是能用代码区分后两者
-
2.3 接口设计:
AOP联盟定义的概念或接口:Pointcut(概念,没有定义对应的接口)、Joinpoint、Advice、MethodInterceptor、MethodInvocation
SpringAOP针对上述Advice接口定义的接口及其实现类:BeforeAdvice、AfterAdvice、MethodBeforeAdvice、AfterReturningAdvice;针对aspectj对上述接口的实现AspectJMethodBeforeAdvice、AspectJAfterReturningAdvice、AspectJAfterThrowingAdvice、AspectJAfterAdvice。
SpringAOP定义的定义的AdvisorAdapter接口:将上述Advise转化为MethodInterceptor
SpringAOP定义的Pointcut接口:含有两个属性ClassFilter(过滤类)、MethodMatcher(过滤方法)
SpringAOP定义的ExpressionPointcut接口:实现中会引入aspectj的pointcut表达式
SpringAOP定义的PointcutAdvisor接口(将上述Advice接口和Pointcut接口结合起来)
-
2.4 SpringAOP的调用流程
-
2.5 SpringAOP自己的实现方式(代表人物ProxyFactoryBean)和借助aspectj实现方式区分
2.3 Spring事务体系源码以及分布式事务Jotm Atomikos源码实现
- 3.1 jdbc事务存在的问题
- 3.2 Hibernate对事务的改进
- 3.3 针对各种各样的事务,Spring如何定义事务体系的接口,以及如何融合jdbc事务和Hibernate事务的
- 3.4 三种事务模型包含的角色以及各自的职责
- 3.5 事务代码也业务代码分离的实现(AOP+ThreadLocal来实现)
- 3.6 Spring事务拦截器TransactionInterceptor全景
- 3.7 X/Open DTP模型,两阶段提交,JTA接口定义
- 3.8 Jotm、Atomikos的实现原理
- 3.9 事务的传播属性
- 3.10 PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED的实现原理以及区别
- 3.11 事物的挂起和恢复的原理
2.4 数据库隔离级别
- 4.1 Read uncommitted:读未提交
- 4.2 Read committed : 读已提交
- 4.3 Repeatable read:可重复读
- 4.4 Serializable :串行化
2.5 数据库
-
5.1 数据库性能的优化
-
5.2 深入理解mysql的Record Locks、Gap Locks、Next-Key Locks
例如下面的在什么情况下会出现死锁:
start transaction; DELETE FROM t WHERE id =6; INSERT INTO t VALUES(6); commit;
-
5.3 insert into select语句的加锁情况
-
5.4 事务的ACID特性概念
-
5.5 innodb的MVCC理解
-
5.6 undo redo binlog
- 1 undo redo 都可以实现持久化,他们的流程是什么?为什么选用redo来做持久化?
- 2 undo、redo结合起来实现原子性和持久化,为什么undo log要先于redo log持久化?
- 3 undo为什么要依赖redo?
- 4 日志内容可以是物理日志,也可以是逻辑日志?他们各自的优点和缺点是?
- 5 redo log最终采用的是物理日志加逻辑日志,物理到page,page内逻辑。还存在什么问题?怎么解决?Double Write
- 6 undo log为什么不采用物理日志而采用逻辑日志?
- 7 为什么要引入Checkpoint?
- 8 引入Checkpoint后为了保证一致性需要阻塞用户操作一段时间,怎么解决这个问题?(这个问题还是很有普遍性的,redis、ZooKeeper都有类似的情况以及不同的应对策略)又有了同步Checkpoint和异步Checkpoint
- 9 开启binlog的情况下,事务内部2PC的一般过程(含有2次持久化,redo log和binlog的持久化)
- 10 解释上述过程,为什么binlog的持久化要在redo log之后,在存储引擎commit之前?
- 11 为什么要保持事务之间写入binlog和执行存储引擎commit操作的顺序性?(即先写入binlog日志的事务一定先commit)
- 12 为了保证上述顺序性,之前的办法是加锁prepare_commit_mutex,但是这极大的降低了事务的效率,怎么来实现binlog的group commit?
- 13 怎么将redo log的持久化也实现group commit?至此事务内部2PC的过程,2次持久化的操作都可以group commit了,极大提高了效率
2.6 ORM框架: mybatis、Hibernate
- 6.1 最原始的jdbc->Spring的JdbcTemplate->hibernate->JPA->SpringDataJPA的演进之路
