VPA安装与使用
官网地址:https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
什么是 VPA?
VPA 全称 Vertical Pod Autoscaler,即垂直 Pod 自动扩缩容,它根据容器资源使用率自动设置 CPU 和内存的requests, 以便为每个 Pod 提供适当的资源。
使用 VPA 的意义:
- Pod 资源用其所需,提升集群节点使用效率;
- 不必运行基准测试任务来确定 CPU 和内存请求的合适值;
- VPA可以随时调整CPU和内存请求,无需人为操作,因此可以减少维护时间。
VPA 主要包括两个组件:
- 1)VPA Controller
- Recommendr:给出 pod 资源调整建议
- Updater:对比建议值和当前值,不一致时驱逐 Pod
- 2)VPA Admission Controller
- Pod 重建时将 Pod 的资源请求量修改为推荐值
VPA 工作流程如下图所示:

首先 Recommender 会根据应用当前的资源使用情况以及历史的资源使用情况,计算接下来可能的资源使用阈值,如果计算出的值和当前值不一致则会给出一条资源调整建议。
然后 Updater 则根据这些建议进行调整,具体调整方法为:
- 1)Updater 根据建议发现需要调整,然后调用 api 驱逐 Pod
- 2)Pod 被驱逐后就会重建,然后再重建过程中VPA Admission Controller 会进行拦截,根据 Recommend 来调整 Pod 的资源请求量
- 3)最终 Pod 重建出来就是按照推荐资源请求量重建的了。
Recommenderd 设计理念
推荐模型(MVP) 假设内存和CPU利用率是独立的随机变量,其分布等于过去 N 天观察到的变量(推荐值为 N=8 以捕获每周峰值)。
- 对于 CPU,目标是将容器使用率超过请求的高百分比(例如95%)时的时间部分保持在某个阈值(例如1%的时间)以下。
- 在此模型中,CPU 使用率 被定义为在短时间间隔内测量的平均使用率。测量间隔越短,针对尖峰、延迟敏感的工作负载的建议质量就越高。
- 最小合理分辨率为1/min,推荐为1/sec。
- 对于内存,目标是将特定时间窗口内容器使用率超过请求的概率保持在某个阈值以下(例如,24小时内低于1%)。
- 窗口必须很长(≥24小时)以确保由 OOM 引起的驱逐不会明显影响(a)服务应用程序的可用性(b)批处理计算的进度(更高级的模型可以允许用户指定SLO来控制它)。
| VPA version | Kubernetes version |
|---|---|
| 1.0 | 1.25+ |
| 0.14 | 1.25+ |
| 0.13 | 1.25+ |
| 0.12 | 1.25+ |
| 0.11 | 1.22 - 1.24 |
| 0.10 | 1.22+ |
| 0.9 | 1.16+ |
| 0.8 | 1.13+ |
| 0.4 to 0.7 | 1.11+ |
| 0.3.X and lower | 1.7+ |
安装条件
首先注意版本差距,尽量不要错版本发布。在 Release 中搜索对于版本的代码,名称如 Vertical Pod Autoscaler 0.9.2 。 注意:从 release 中 Vertical Pod Autoscaler 拉取后的代码包里镜像版本可能不与 release 版本一致,要差一个版本。
- kubectl应连接到您要安装 VPA 的集群。
- 指标服务器必须部署在您的集群中。了解有关指标服务器的更多信息。
- 如果您使用的是 GKE Kubernetes 集群,则需要授予您当前的 Google 身份cluster-admin角色。否则,您将无权向 VPA 系统组件授予额外权限。
$ gcloud info | grep Account # get current google identity
Account: [myname@example.org]
$ kubectl create clusterrolebinding myname-cluster-admin-binding --clusterrole=cluster-admin --user=myname@example.org
Clusterrolebinding "myname-cluster-admin-binding" created
- 如果您的集群中已安装了另一个版本的 VPA,则必须首先在之前的版本文件夹使用以下命令拆除现有安装:
./hack/vpa-down.sh
正式安装
wget https://mirror.ghproxy.com/https://github.com/kubernetes/autoscaler/archive/refs/tags/vertical-pod-autoscaler-0.14.0.tar.gz
tar -zxf vertical-pod-autoscaler-0.14.0.tar.gz
cd /root/autoscaler-vertical-pod-autoscaler-0.14.0/vertical-pod-autoscaler
# 直接安装
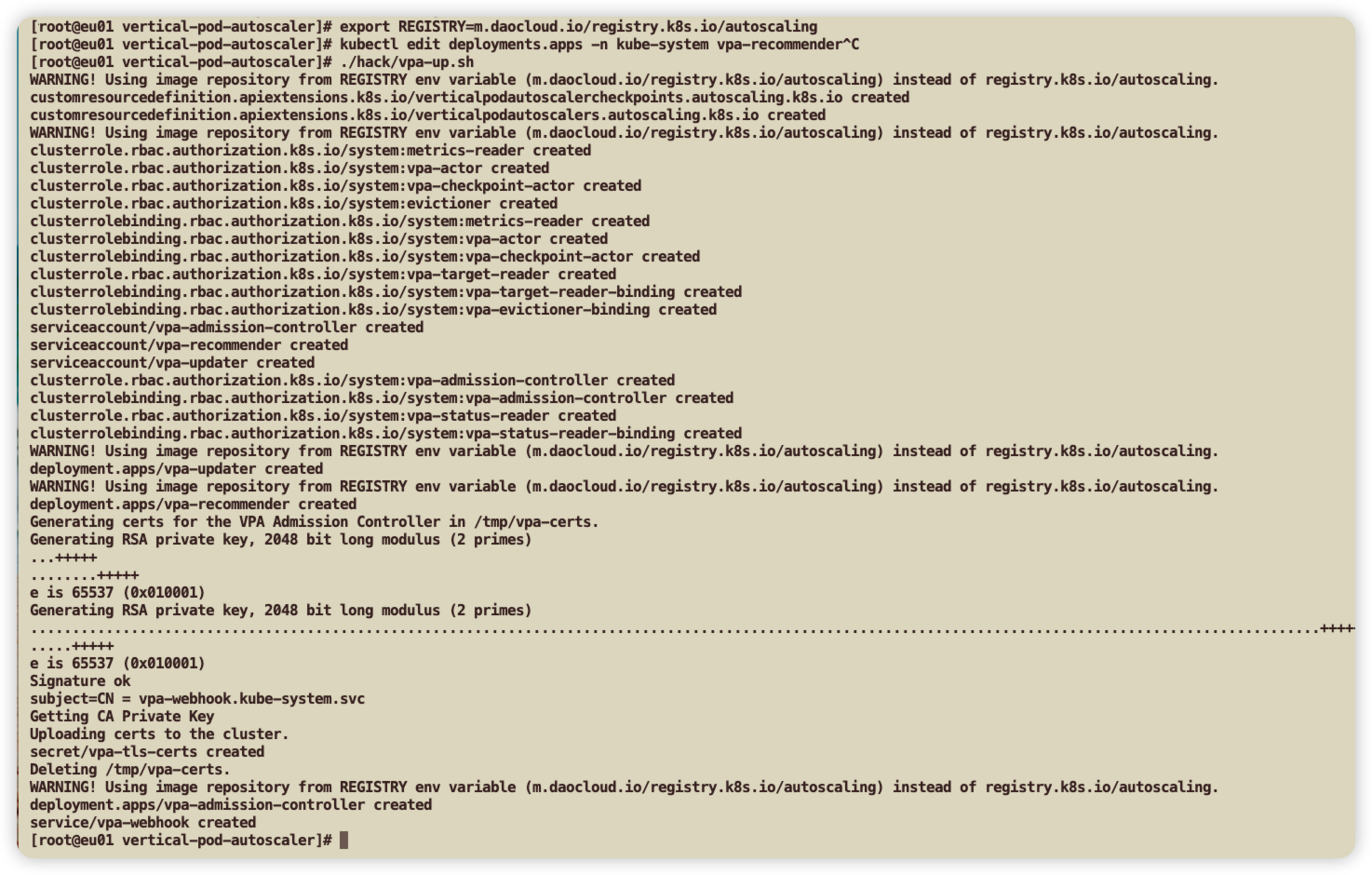
./hack/vpa-up.sh
# 注意:直接安装使用的是registry.k8s.io/autoscaling,该镜像仓库无法拉取,需要修改为m.daocloud.io/registry.k8s.io/autoscaling
# 直接修改仓库地址后安装
# 如果已安装过需要先卸载
./hack/vpa-down.sh
export REGISTRY=m.daocloud.io/registry.k8s.io/autoscaling
./hack/vpa-up.sh
# 在输出日志中会提示warning镜像仓库变化
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: vpa-app-name
spec:
resourcePolicy:
containerPolicies:
- controlledResources:
- memory
controlledValues: RequestsOnly
containerName: app-name
targetRef:
apiVersion: apps/v1
kind: Deployment
name: app-name
updatePolicy:
updateMode: Initial
最低内存值
在实际使用中发现,比如前端 Nginx 应用只是运行一个 NG,没有其他服务,监控上内存也偏低,最多 80Mi,但是 VPA 推荐默认都是262144k 即 250M,使得推荐值超过了实际值,少量 Ng 这种低内存应用下该策略不会有特别影响,但是在有大量同类应用时就会导致超量预留资源,经过查询发现这是由一个参数 pod-recommendation-min-memory-mb 决定的,参考链接: https://github.com/kubernetes/autoscaler/issues/2125 。
所以需要修改 vpa-recommender 添加如下:
- args:
- --pod-recommendation-min-memory-mb=50
