

Linux运维08
一.总结 tomcat实现多虚拟机

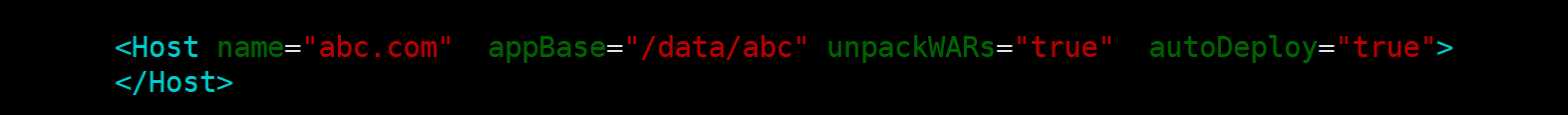
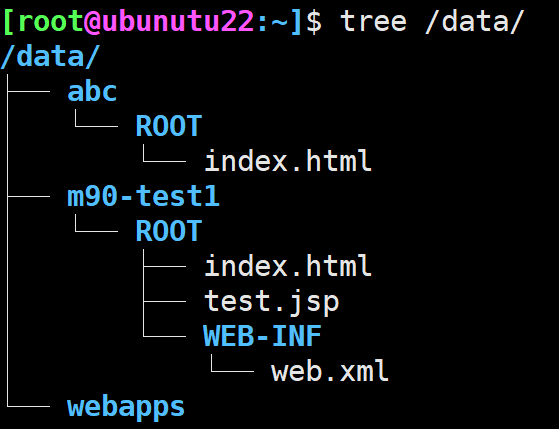
简而言之,在一个目录下建立对应目录在目录里面的ROOT文件夹里建立html,jsp等等文件,然后在/usr/local/tomcat下的conf/server.xml里面的Host栏添加对应路径
二.总结 tomcat定制访问日志格式和反向代理tomcat
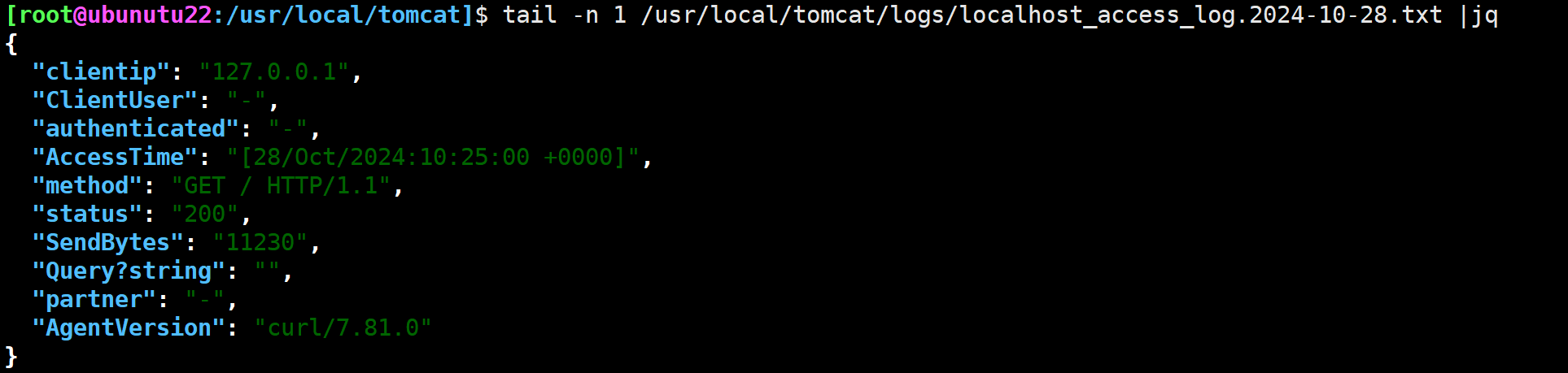
tomcat定制访问日志格式
在/usr/local/tomcat下vim conf/server.xml

查看
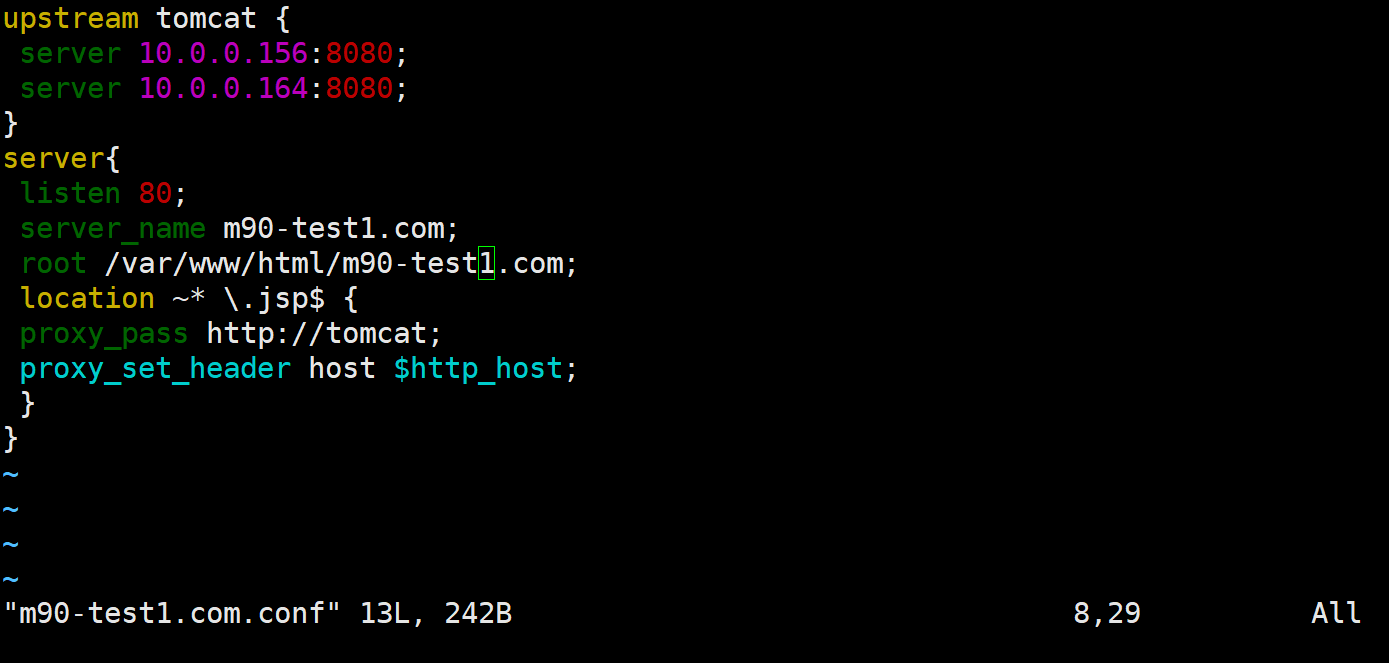
反向代理tomcat
单应用部署:仅部署单机 Tomcat ,由 Tomcat 直接响应客户端请求
单机反向代理部署:前端部署 Nginx 或 Httpd 来响应客户端请求,将需要由 Tomcat 处理的请求转发到后端,可实现动静分离
多机反向代理部署:前端部署 Nginx 来响应客户端请求,配合负载均衡将动态请求轮流转发到后端Tomcat 服务器处理,可以将静态资源直接部署在前端 Nginx 上,实现动静分离
多机多级反向代理部署:可以分别用 Nginx 实现四层和七层的代理
Nginx 代理多机 Tomcat 实现
两台虚拟机配置一样的


三.总结iptable 5表5链, 基本使用,扩展模块。

基本使用
规则取反
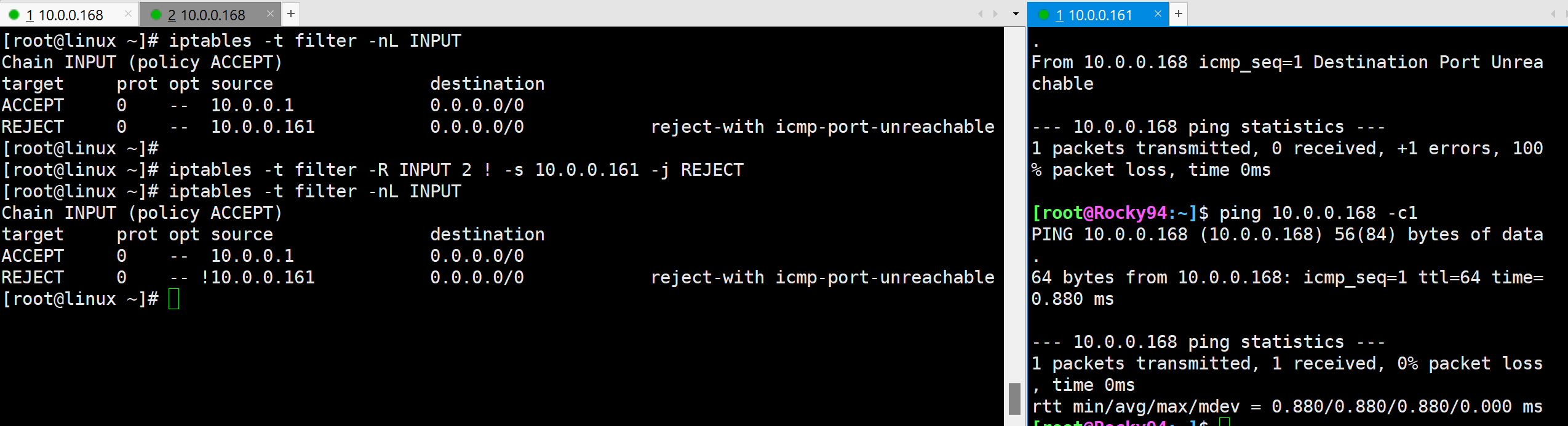
根据目标地址匹配
添加IP地址 清空规则 当前两个ip都能ping通
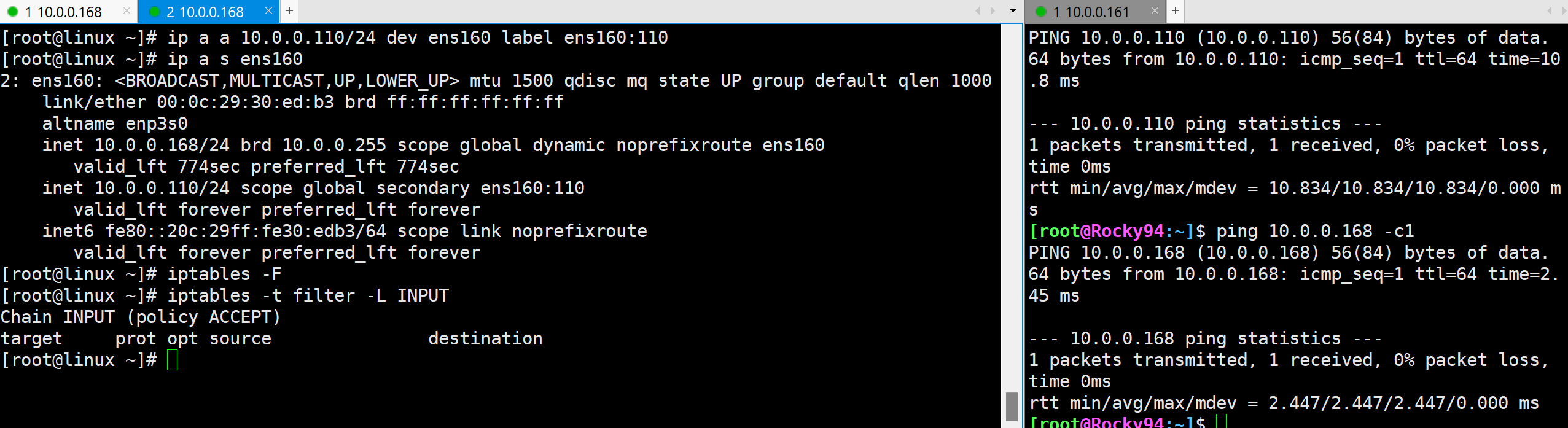
拒绝110ip
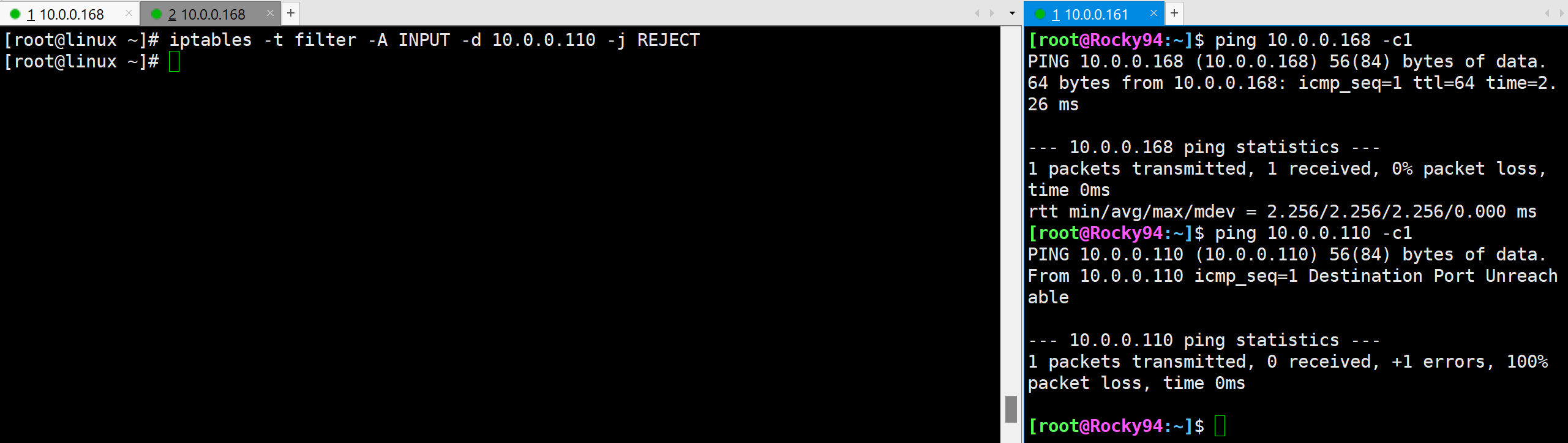
规则取反
iptables -t filter -R INPUT 1 ! -d 10.0.0.110 -j REJECT

扩展模块
隐式扩展
iptables 在使用 -p 选项指明了特定的协议时,无需再用 -m 选项指明扩展模块的扩展机制,不需要手动加载扩展模块,不需要用 -m 显式指定的扩展,即隐式扩展。
tcp,upd,icmp 这三个协议是可以用 -m 指定的模块,但同时,也可以在基本匹配里面用 -p 来指定这几个协议
用tcp 协议和目标端口拒绝ssh服务

显式扩展及相关模块
显示扩展即必须使用 -m 选项指明要调用的扩展模块名称,需要手动加载扩展模块。
Multiport 模块
作用:匹配多个端口。
iptables -A INPUT -p tcp -m multiport --dports 22,80,443 -j ACCEPT
这允许来自TCP端口22, 80, 和443的流量通过。
Limit 模块
作用:限制流量的频率。
iptables -A INPUT -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 10 -j ACCEPT
限制SSH登录尝试,每分钟最多5次,但可以有10个突发尝试。
MAC 模块
作用:基于源MAC地址进行匹配。
iptables -A INPUT -m mac --mac-source 00:11:22:33:44:55 -j ACCEPT
仅允许特定MAC地址的流量通过。
Time 模块
作用:基于时间进行匹配。
iptables -A INPUT -m time --timestart 09:00 --timestop 17:00 -j ACCEPT
只在工作时间(9:00 AM - 5:00 PM)允许流量通过。
String 模块
作用:匹配数据包中的特定字符串。
iptables -A INPUT -p tcp --dport 80 -m string --algo bm --string "malicious" -j DROP
Connlimit 模块
作用:限制每个IP地址的最大连接数。
iptables -A INPUT -p tcp --syn --dport 22 -m connlimit --connlimit-above 2 -j REJECT
限制每个IP地址对SSH端口的连接数不超过2。
IPRange 模块
作用:匹配特定的IP范围。
iptables -A INPUT -m iprange --src-range 192.168.1.100-192.168.1.200 -j ACCEPT
允许来自192.168.1.100到192.168.1.200的IP地址的流量。
Recent 模块
作用:根据最近的活动匹配流量。
iptables -A INPUT -p tcp --dport 22 -m recent --update --seconds 60 --hitcount 4 -j DROP
如果在60秒内来自同一IP地址的SSH连接尝试超过4次,则拒绝该IP的连接。
四.总结iptables规则优化实践,规则保存和恢复。
规则优化最佳实践:
安全放行所有入站和出站的状态为ESTABLISHED状态连接,建议放在第一条,效率更高
谨慎放行入站的新请求
有特殊目的限制访问功能,要在放行规则之前加以拒绝
同类规则(访问同一应用,比如:http ),匹配范围小的放在前面,用于特殊处理
不同类的规则(访问不同应用,一个是http,另一个是mysql ),匹配范围大的放在前面,效率更高
应该将那些可由一条规则能够描述的多个规则合并为一条,减少规则数量,提高检查效率
设置默认策略,建议白名单(只放行特定连接)
默认规则(iptables -P)是 ACCEPT,不建议修改,容易出现 “自杀” 现象
规则的最后定义规则做为默认策略,推荐使用,放在最后一条
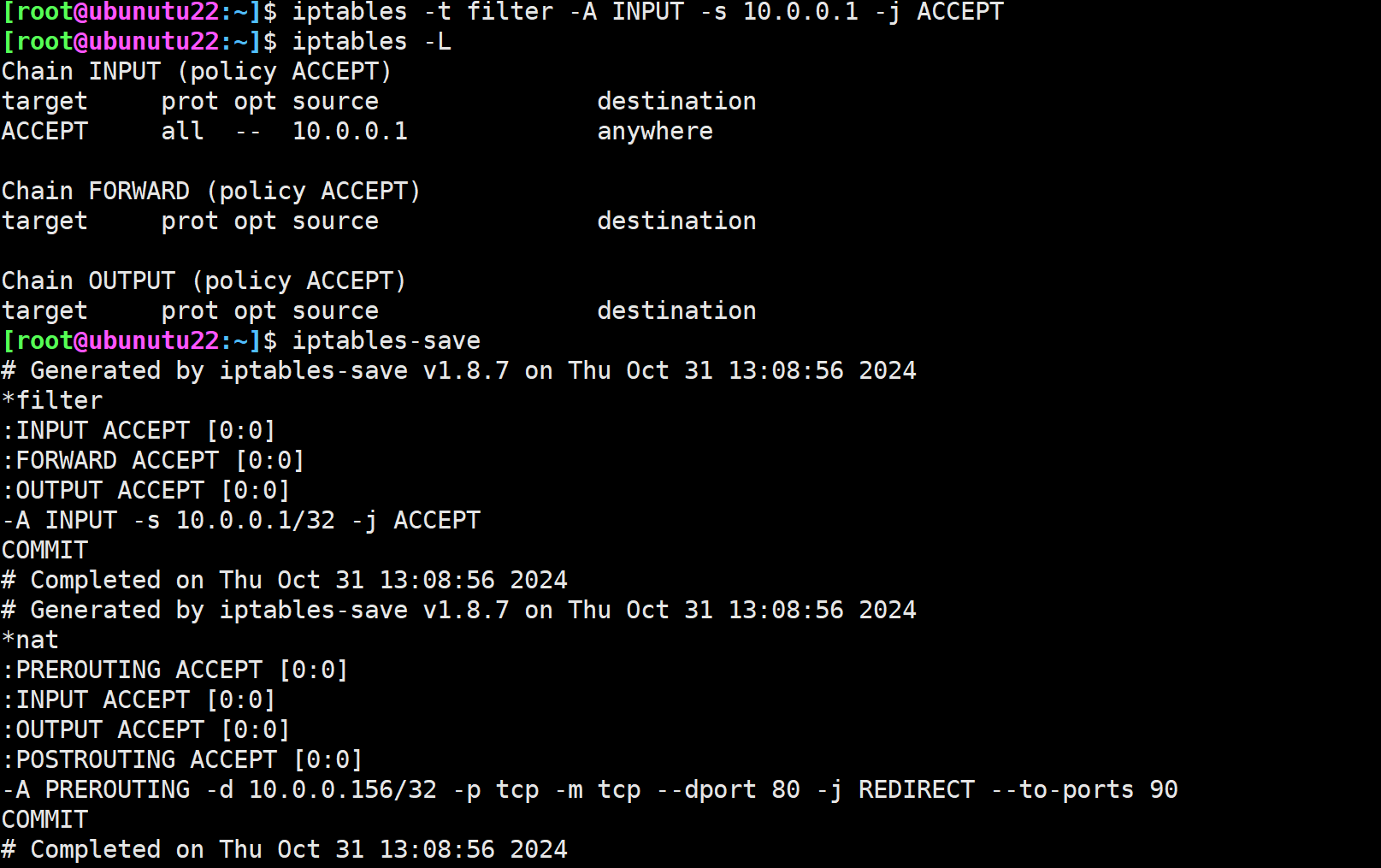
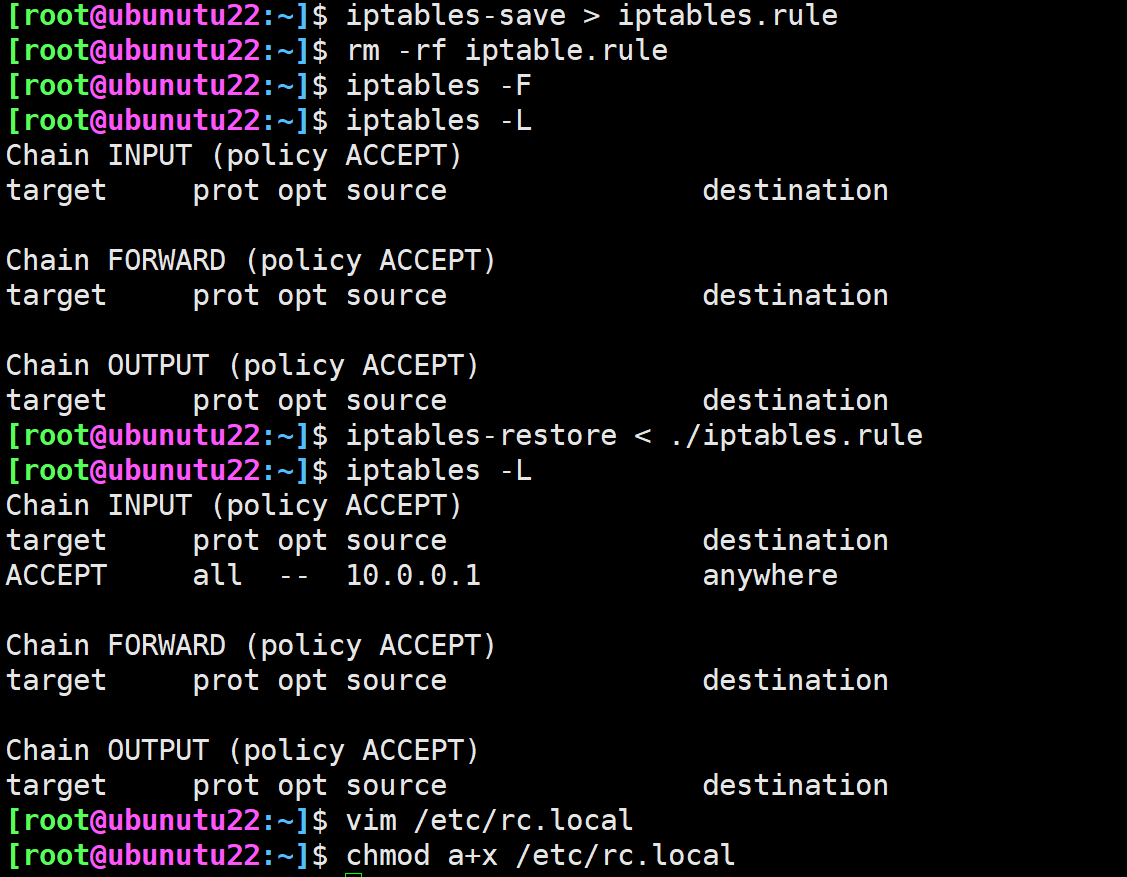
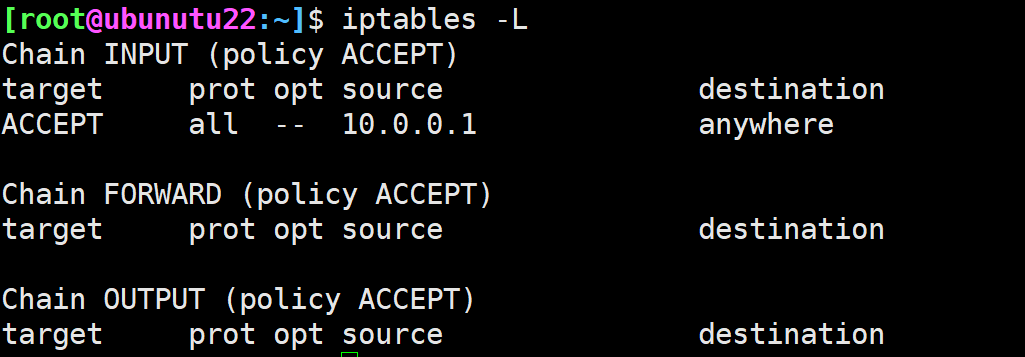
规则保存和恢复
五.总结NAT转换原理, DNAT/SDNAT原理,并自行设计架构实现DNAT/SNAT。
NAT:(Network Address Translation) 网络地址转换
局域网中的主机都是分配的私有IP地址,这些IP地址在互联网上是不可达的,局域网中的主机,在与互
联网通讯时,要经过网络地址转换,去到互联网时,变成公网IP地址对外发送数据。服务器返回数据
时,也是返回到这个公网地址,再经由网络地址转换返回给局域网中的主机。
一个局域网中的主机,想要访问互联网,在出口处,应该有一个公网可达的IP地址,应该能将局域网中
的IP地址通过NAT转换成公网IP。
SNAT:Source NAT,源地址转换,基于nat表,工作在 POSTROUTING 链上。
具体是指将经过当前主机转发的请求报文的源IP地址转换成根据防火墙规则指定的IP地址。
DNAT:Destination NAT,目标地址转换,基于nat表,工作在 PREROUTING 链上。
在流量进入内部网络时,根据配置规则将目的IP地址或端口转换为内部服务器地址。常用于实现外部访问内部服务的需求,如将公网IP上的请求转发到内网服务器上。
自行设计架构实现SNAT
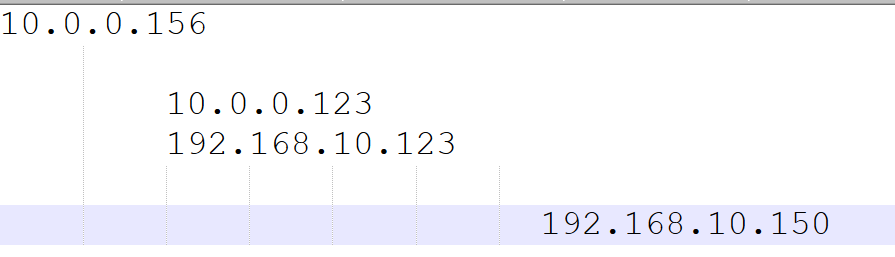
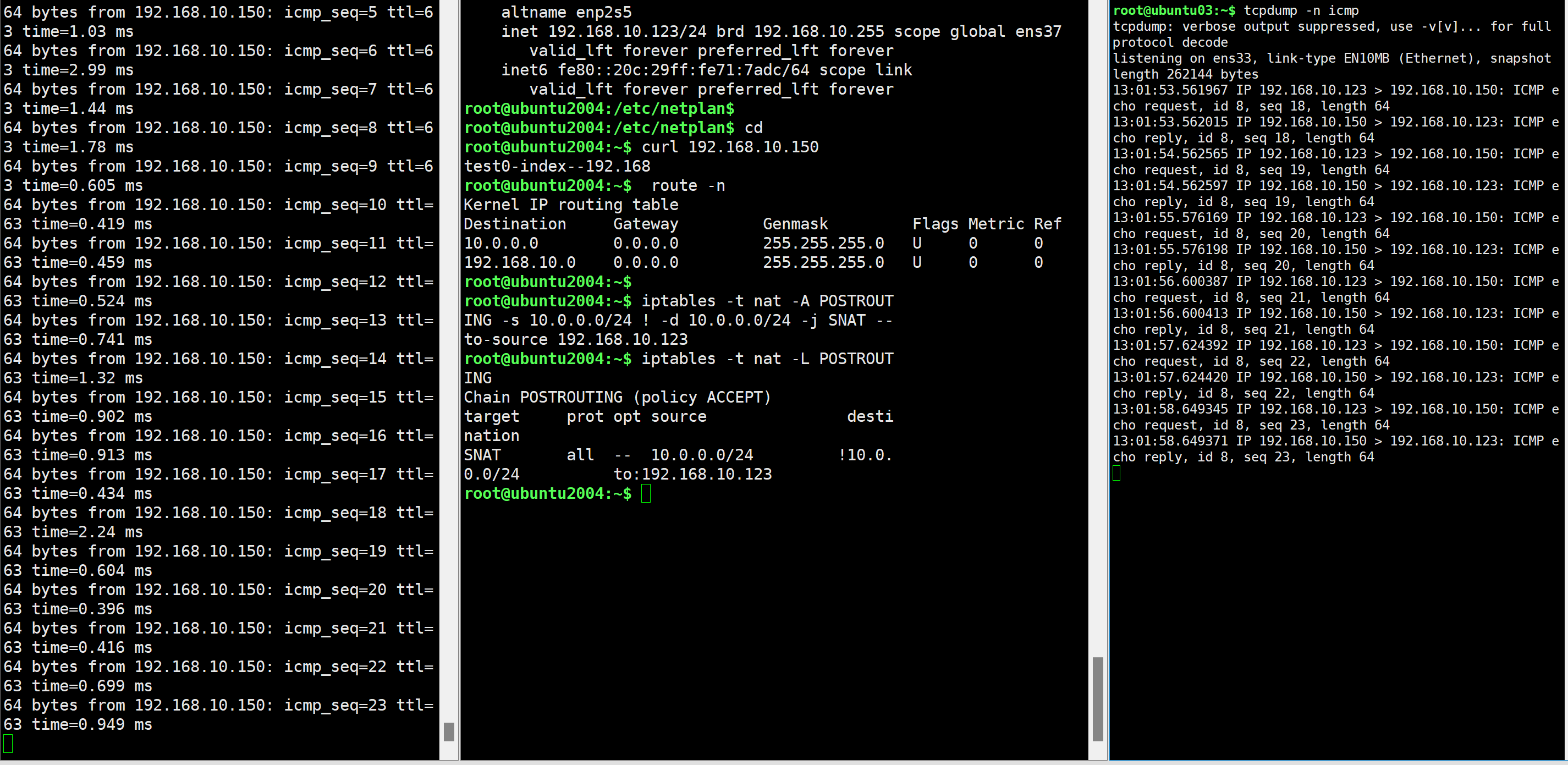
在防火墙主机上添加规则,如果源IP是 10.0.0.0/24网段的IP,则出去的时候,替换成192.168.10.123
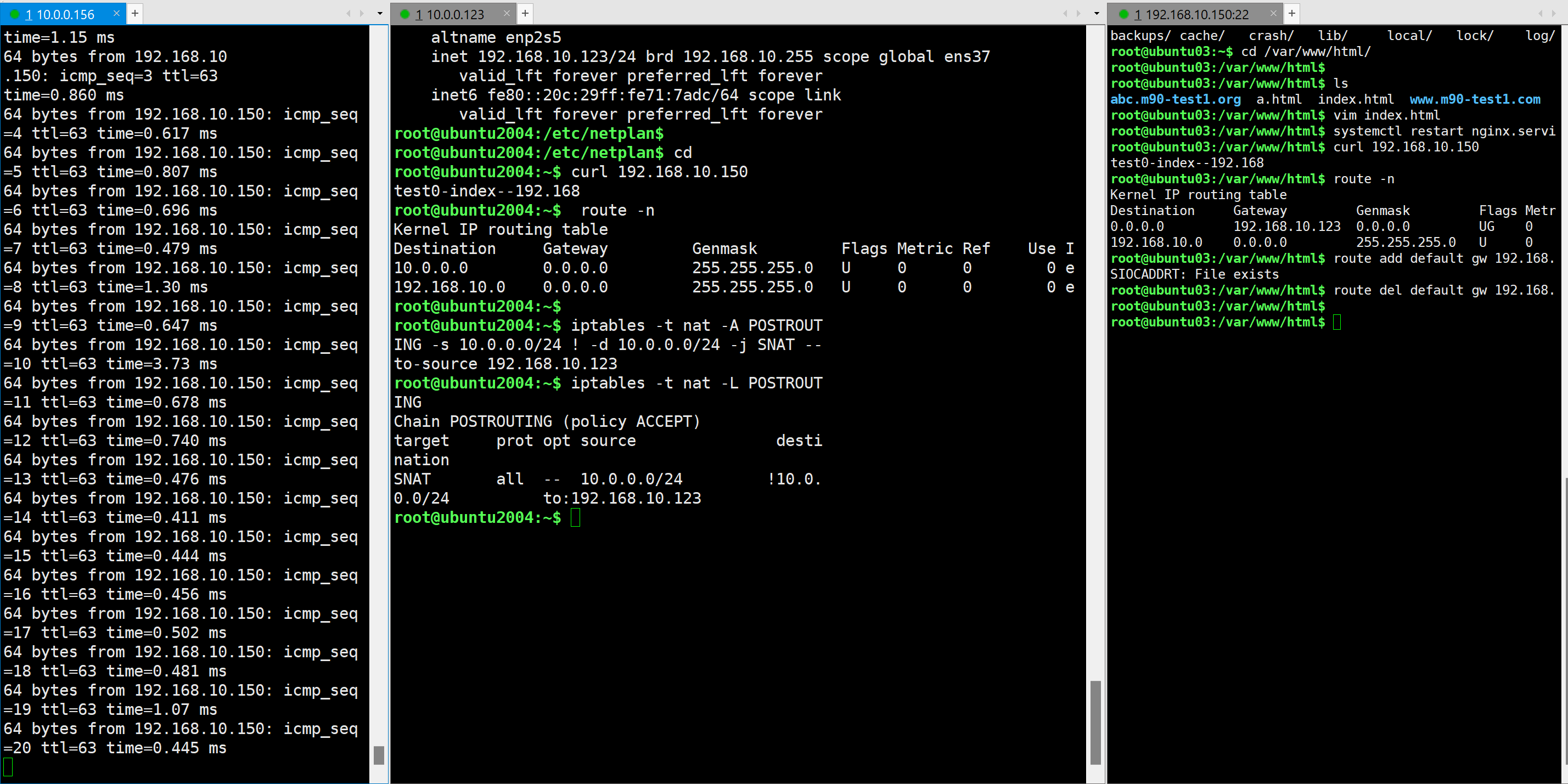
测试,10.0.0.156 主机可以到达 192.168.10.150
192.168.10.150主机上抓PING包 所有的PING包都来自于 192.168.10.123,而并非是 10.0.0.156
MASQUERADE 实现源IP地址转换
用 MASQUERADE 设置SNAT转发
将防火墙主机的IP改成192.168.10.143
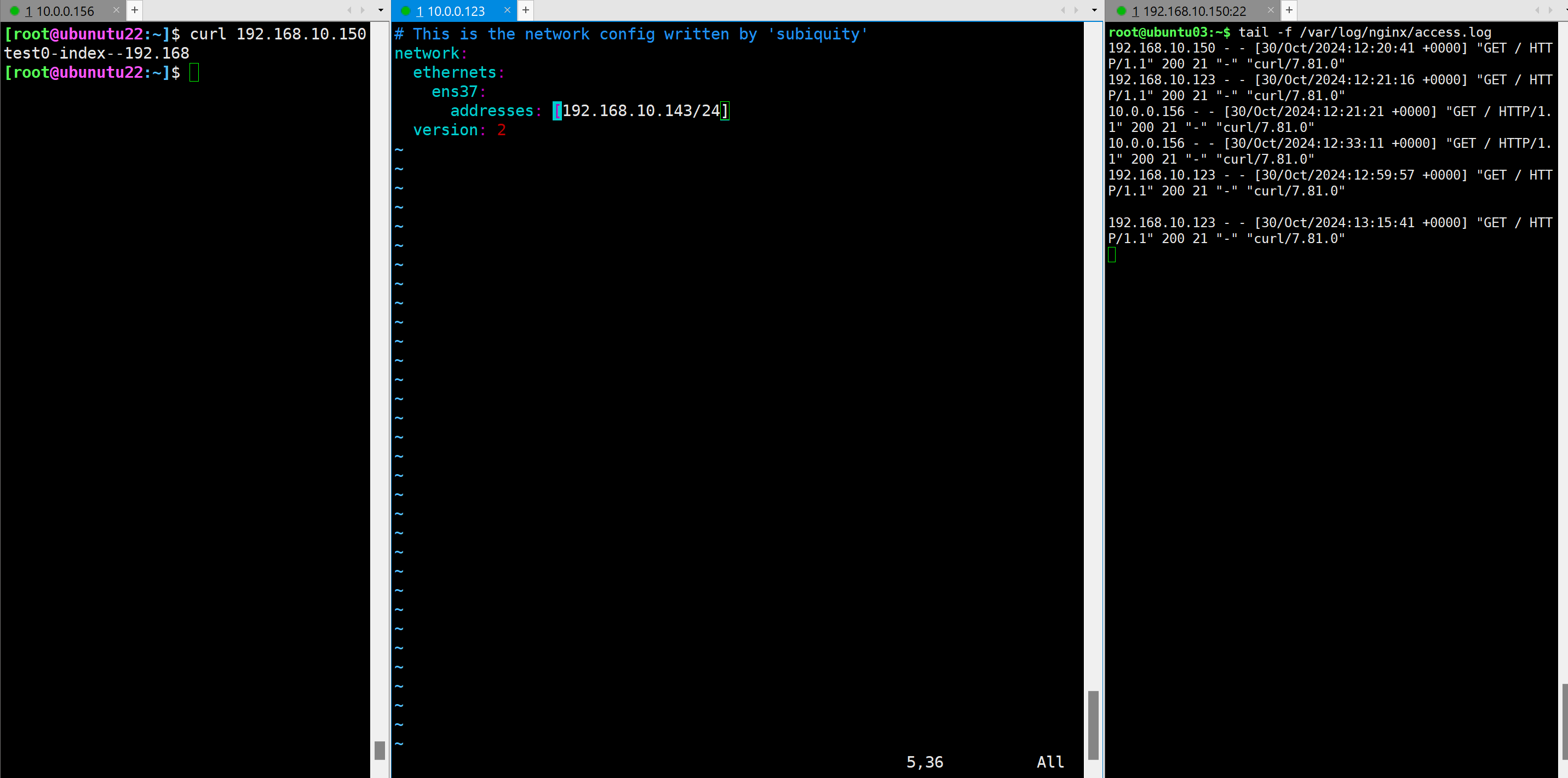
请求IP己经变成 192.168.10.143
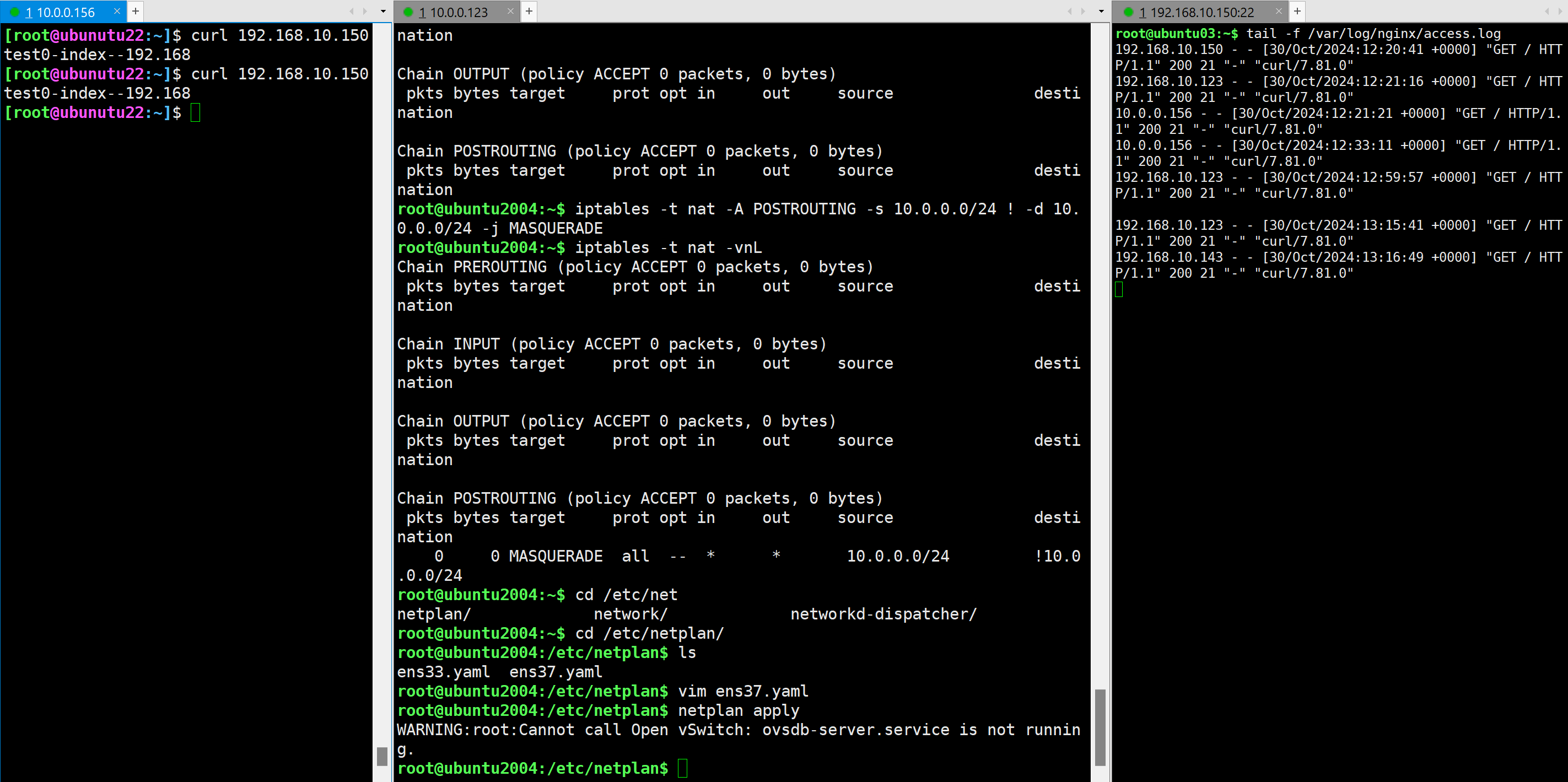
自行设计架构实现DNAT
在防火墙主机上设置DNAT转发规则,在访问 10.0.0.123 的 web 服务时,转发到 192.168.10.150上 并测试
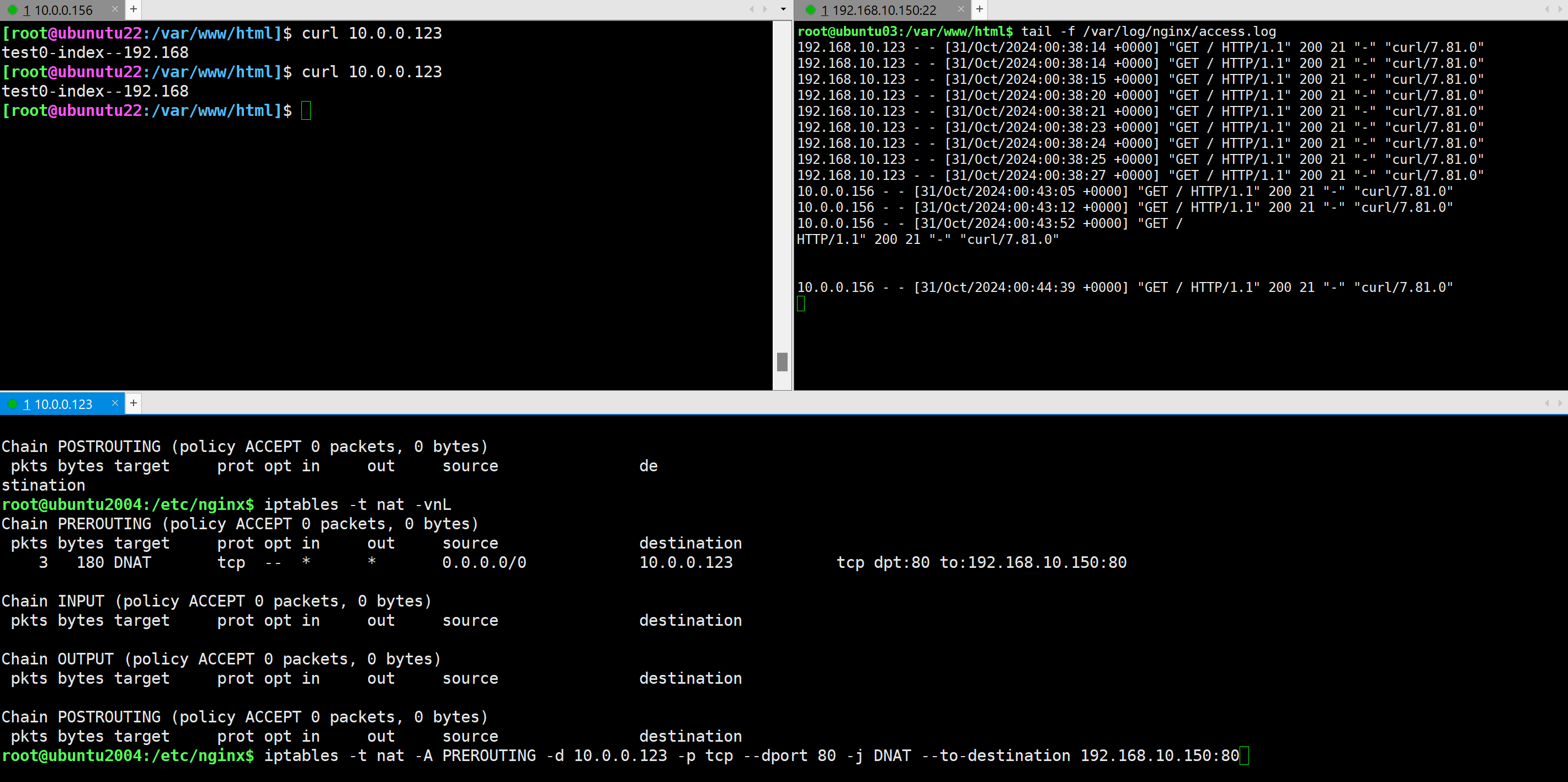
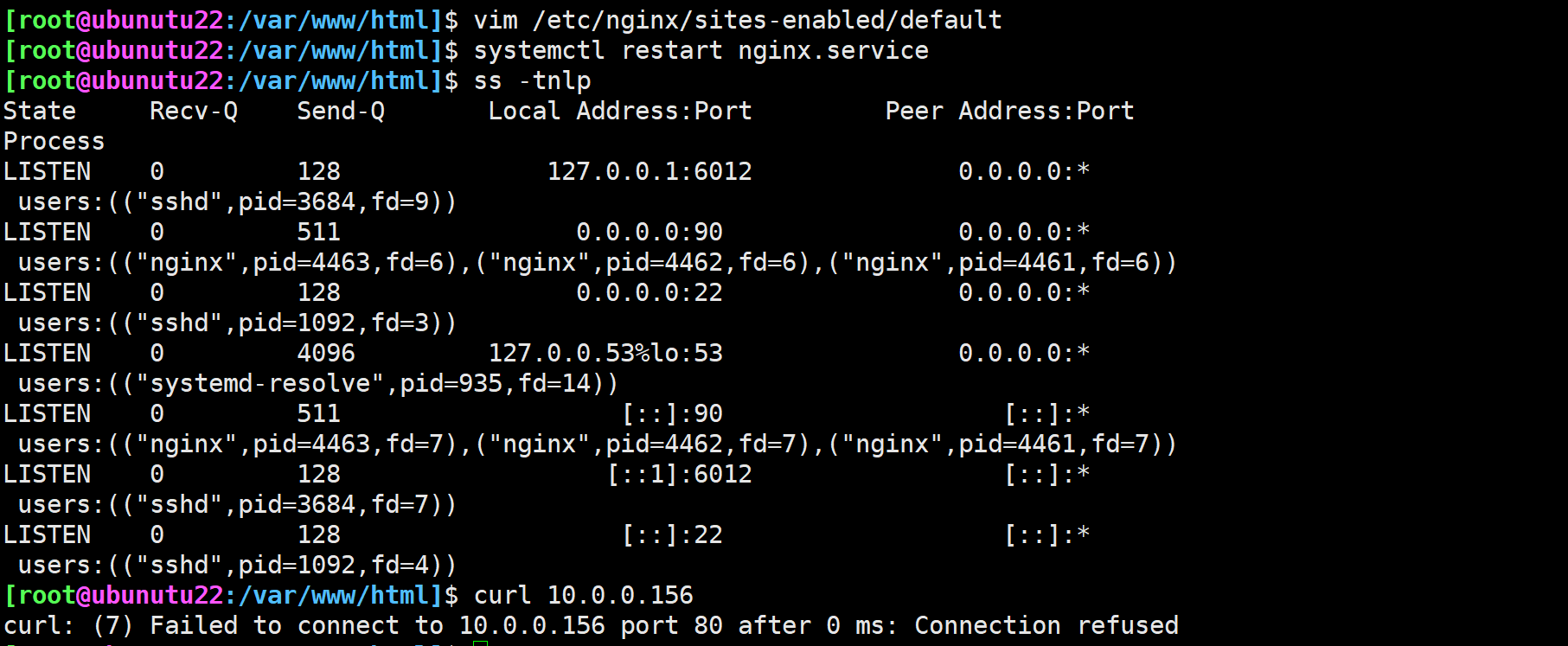
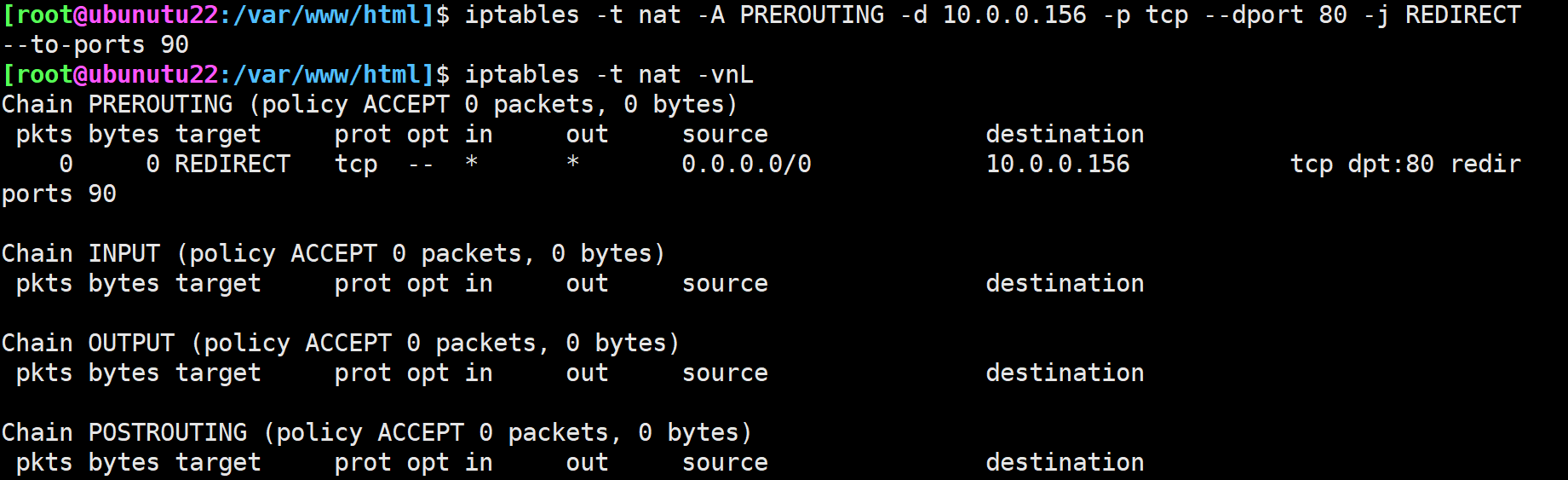
六.使用REDIRECT将90端口重定向80,并可以访问到80端口的服务
修改nginx配置,监听90端口
在10.0.0.156上添加REDIRECT规则,将80端口的请求转发到90端口
在10.0.0.123 上访问 156 的 web服务

七.firewalld常见区域总结。

八.通过ntftable来实现暴露本机80/443/ssh服务端口给指定网络访问
创建表和链
nft add table ip filter
nft add chain ip filter input { type filter hook input priority 0 ; }
添加规则
nft add rule ip filter input ip saddr 192.168.1.0/24 tcp dport 80 accept
nft add rule ip filter input ip saddr 192.168.1.0/24 tcp dport 443 accept
nft add rule ip filter input ip saddr 192.168.1.0/24 tcp dport 22 accept
保存规则
sudo nft list ruleset > /etc/nftables.conf
加载规则
sudo nft -f /etc/nftables.conf
九.完成 nginx 反向代理 tomcat实现基于redis会话复制的集群构建
在 server.xml 中 指定基目的 Host 标签内添加下列内容
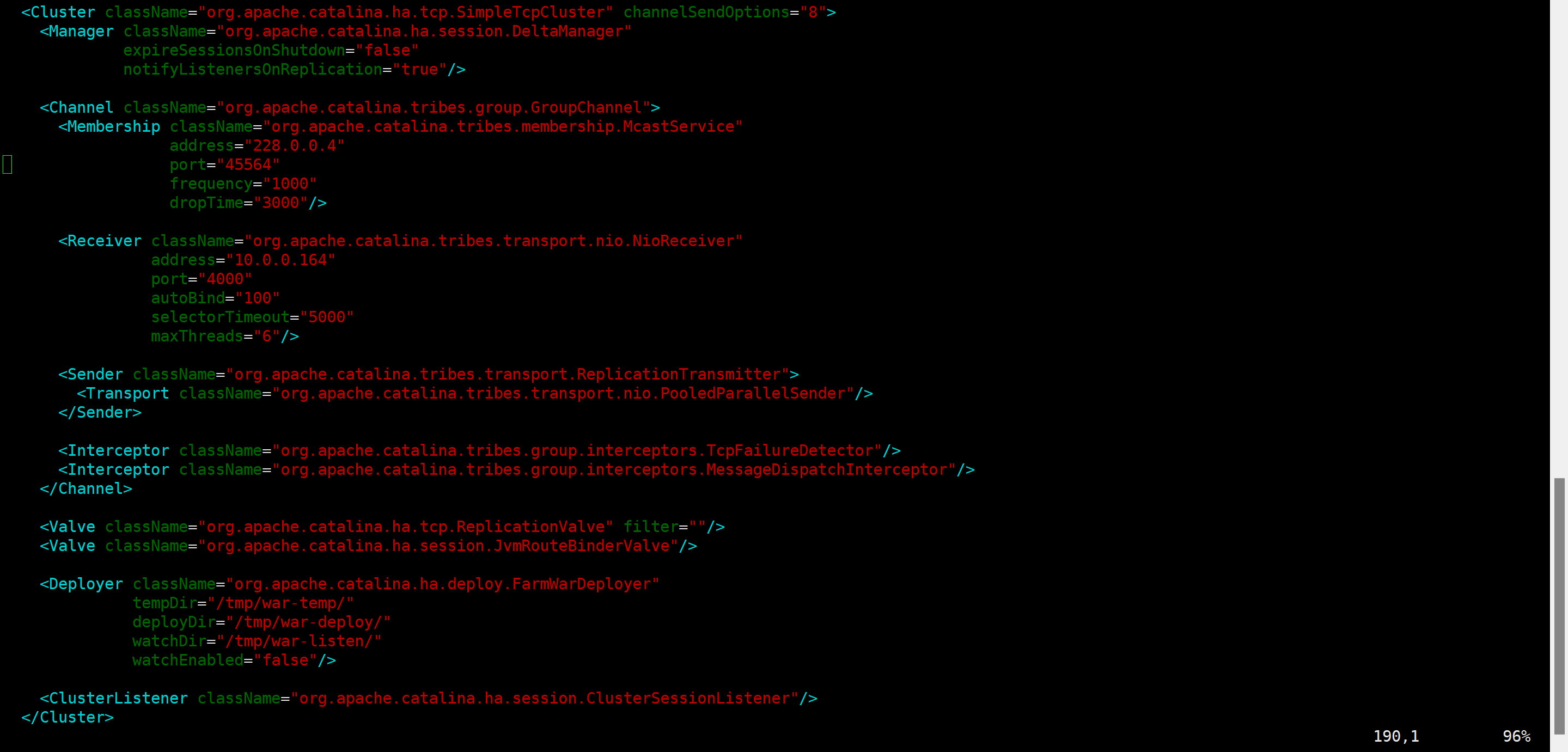
下载jar 包,修改 tomcat 配置
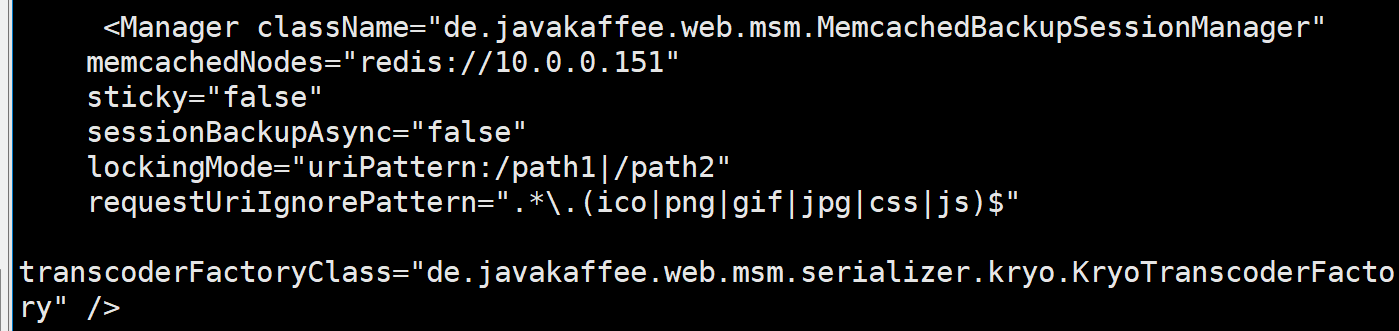
tomcat 节点配置 session 共享
下载相关jar 包
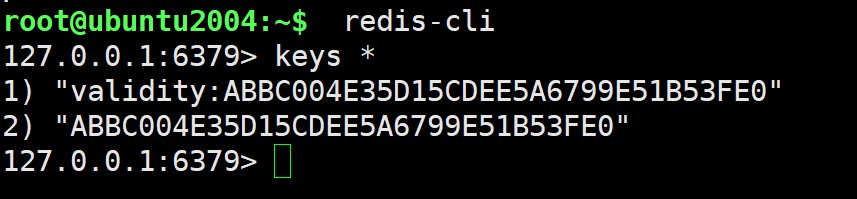
重启 tomcat,并在浏览器中访问 再次查看 redis


十.总结 JVM垃圾回收算法和分代
标记-清除 Mark-Sweep
分垃圾标记阶段和内存释放两个阶段
标记阶段,找到所有可访问对象打个标记。清理阶段,遍历整个堆对未标记对象(即不再使用的对象)逐一进行清理
特点:算法简单,不会浪费内存空间,效率较高,但会形成内存碎片
标记-压缩 (压实)Mark-Compact
分垃圾标记阶段和内存整理两个阶段
标记阶段,找到所有可访问对象打个标记内存清理阶段时,整理时将对象向内存一端移动,整理后存活对象连续的集中在内存一端
特点:整理后的内存空间是连续分配的,有大段的连续内存可分配,没有内存碎片,缺点是内存整理过程有消耗,效率相对低下
复制 Copying
先将可用内存分为大小相同两块区域A和B,每次只用其中一块,比如A。当A用完后,则将A中存活的对象复制到B。复制到B的时候连续的使用内存,最后将A一次性清除干净
特点:好处是没有碎片,复制过程中保证对象使用连续空间,且一次性清除所有垃圾,所以即使对象很多,收回效率也很高,缺点是比较浪费内存,只能使用原来一半内存,因为内存对半划分了,复制过程毕竟也是有代价
没有最好的算法,在不同场景选择最合适的算法
效率:复制算法>标记清除算法> 标记压缩算法
内存整齐度:复制算法=标记压缩算法> 标记清除算法
内存利用率:标记压缩算法=标记清除算法>复制算法
STW:对于大多数垃圾回收算法而言,GC线程工作时,停止所有工作的线程,称为Stop The World。
GC 完成时,恢复其他工作线程运行。这也是JVM运行中最头疼的问题
堆内存分代
将heap内存空间分为三个不同类别: 年轻代、老年代、持久代
年轻代 Young:Young Generation
伊甸园区 eden:只有一个,刚刚创建的对象
幸存(存活)区 Servivor Space:有2个幸存区,一个是from区,一个是to区。大小相等、地位相同、可互换
老年代Tenured:Old Generation, 长时间存活的对象
永久代:JDK1.7之前使用,即Method Area方法区,保存 JVM 自身的类和方法,存储 JAVA 运行时的环境信息,JDK1.8 后改名为 MetaSpace,此空间不存在垃圾回收,关闭JVM会释放此区域内存,此空间物理上不属于heap内存,但逻辑上存在于heap内存
永久代必须指定大小限制,字符串常量JDK1.7存放在永久代,1.8后存放在heap中
MetaSpace 可以设置,也可不设置,无上限
默认空间大小比例:
默认JVM试图分配最大内存的总内存的1/4,初始化默认总内存为总内存的1/64,年青代中heap的1/3,老年代占2/3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号