2.安装MySQL&Hive及其相关用法
一、安装Mysql和Hive及其用法(方法一,推荐)
1.Mysql
1.安装MySQL
1.安装
简述Ubuntu版本安装命令:自动下载为8.0版本部分使用代码与5.7不同。
sudo apt-get install mysql-server
sudo apt-get install mysql-client
sudo apt-get install libmysqlclient-dev
2.初始设置
最好在解决mysql登录和root初始密码设置后进行步骤3-3:
1.使用root 用户登录
2.创建数据库
3.创建普通用户:hadoop,密码:hadoop:
4.授权bee用户拥有刚才创建数据库的所有权限
5.刷新权限表
mysql -uroot -p
create database hiveDB DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
create user 'hadoop' identified by 'hadoop';
grant all privileges on hiveDB.* to 'hadoop'@'%' identified by 'hadoop';
flush privileges;
3.会出现的问题(注意事项)
在Ubuntu上使用sudo apt-get install mysql-server指令安装mysql后,你会发现你登录不上,会出现这样的情况。
hadoop@yjp:~$ mysql
ERROR 1045 (28000): Access denied for user 'hadoop'@'localhost' (using password: NO)
hadoop@yjp:~$ mysql -uroot -p
Enter password:
ERROR 1698 (28000): Access denied for user 'root'@'localhost'
问题解决
1.root用户登录问题
使用命令查看mysql数据库自动设置的随机账户与密码
sudo cat /etc/mysql/debian.cnf

图中显示的就是默认随机的账户与密码,我们可以使用这组账号与面进行mysql登录

登陆成功!
2.修改mysql用户密码问题
1.情况一
1、切换数据库
use mysql
2、修改root用户密码
注意下面两条修改mysql root用户密码的命令只适用于mysql5.7版本及以下
1.这里你会发现你在网上搜出来的大部分修改面的命令都是
update user set password=PASSWORD("root") where user=root;
--设置密码为root
或者是
update user set authentication_string=PASSWORD(“root”) where user=‘root’;
--设置密码为root
执行完命令之后 flush privileges; 更新所有操作权限,重启数据库 service mysql restart 即可
mysql 5.7.9以后(即mysql 8.0)废弃了password字段和password()函数;authentication_string:字段表示用户密码,而authentication_string字段下只能是mysql加密后的41位字符串密码。
2.情况二
我们一般现在使用指令安装mysql会默认安装最新版mysql8.0
修改mysql8.0 root用户密码正确打开方式
MySql 从8.0开始修改密码有了变化,在user表加了字段authentication_string,修改密码前先检查authentication_string是否为空
如果不为空,先置空字段在修改密码
use mysql;
update user set authentication_string='' where user='root'; #将字段置为空
alter user 'root'@'localhost' identified with mysql_native_password by 'root'; #修改密码
--修改密码为root。
如果为空,则直接修改密码
alter user 'root'@'localhost' identified with mysql_native_password by 'root';
--修改密码为root。
修改成功!

需要重启MySQL服务
service mysql restart
登陆成功!

查看数据库
show databases;
3.授权mysql用户拥有创建数据库的所有权限问题(3-3)
在mysql执行授权语句
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'password'WITH GRANT OPTION;
时提示如下错误:
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'IDENTIFIED BY 'Tibco123'WITH GRANT OPTION' at line 1、
在Mysql 8版本中,不能使用
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'password'WITH GRANT OPTION;
这一行命令来设置用户权限,必须分两步来实现设置用户权限【先创建用户、在对该用户分配用户权限】,最后刷新权限
CREATE USER 'user'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON DBname.* TO 'user'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
与之初始设置代码对比
CREATE USER 'user'@'%' IDENTIFIED BY 'password';
create user 'hadoop' identified by 'hadoop';
GRANT ALL PRIVILEGES ON DBname.* TO 'user'@'%' WITH GRANT OPTION;
grant all privileges on hiveDB.* to 'hadoop'@'%' identified by 'hadoop';
4.Mysql JDBC下载:官网
下载官网:https://downloads.mysql.com/archives/c-j/
重点:将JDBC驱动文件复制到Hive的lib目录:

(因下载的mysql为8.0,可以选择mysql-connector-java-8的连接器,但未尝试,详细步骤看2-7)
5.创建数据库database
CREATE DATABASE hiveDB;
show databases;
use hiveDB;
2.Hive
1.下载
下载网站:http://www.apache.org/dyn/closer.cgi/hive/
这里下载的是2.3.4 版本。
解压到 /home/hadoop/目,并修改名称:
1.安装
sudo tar -zxf ~/下载/apache-hive-2.3.4-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./apache-hive-2.3.4-bin/ ./hive # 将文件夹名改为hive
sudo chown -R hadoop ./hive
sudo tar -zxvf ~/下载/apache-hive-2.3.4-bin.tar.gz -C /usr/local
2.tar命令
tar 是Linux下经常使用的归档工具,对文件或者目录进行打包归档,归档成一个目录,但是并不进行压缩。
格式:
tar [主选项+辅助选项] 文件或目录
主选项 说 明
-c 新建文件
-r 把要归档的文件追加到档案文件的末尾
-t 列出档案文件中已经归档的文件列表
-x 从打包的档案文件中还原出文件
-u 更新档案文件,用新建文件替换档案中的原始文件
辅助选项 说 明
-z 调用gzip命令在文件打包的过程中压缩/解压文件
-w 在还原文件时,把所有文件的修改时间设定为现在时间
-j 调用bzip2命令在文件打包的过程中压缩/解压文件
-Z 调用compress命令过渡档案
-f “-f"选项后面紧跟档案文件的存储设备,默认是磁盘,需要指定档案文件名;
如果是磁盘,只需指定磁带设备名即可。
注意,在”-f"选项之后不能再跟任何其他选项,
也就是说,"-f"必须是tar命令的最后一个选项
-v 指定在创建归档文件过程中,显示各个归档文件的名称
-p 在文件归档的过程中,保持文件的属性不发生变化
2.配置环境变量
vim ~/.bashrc
export HIVE_HOME=/home/hadoop/hive
export PATH=$PATH:$HIVE_HOME/bin/
执行
source ~/.bashrc
3.配置Hive文件
在hive/conf目录下
1.hive-env.sh
在末尾加入Hadoop安装目录,如我的目录为:
#打开hive-env.sh文件编辑
vim /usr/local/hadoop/hive/conf/hive-env.sh
#一般只需要添加以下内容即可
HADOOP_HOME=/usr/local/hadoop
剩下内容对比自身需要添加内容,在 hive-env.sh 文件中指定 Hadoop 安装路径:
export JAVA_HOME=/usr/java... ##Java路径
export HADOOP_HOME=/usr/local/hadoop ##Hadoop安装路径
export HIVE_HOME=/usr/local/hive ##Hive安装路径
export HIVE_CONF_DIR=/usr/local/hive/conf ##Hive配置文件路径
2.hive-site.xml
目录下应该不存在,所以自己创建,在此附上完整配置代码:
注意修改对应位置为自己的主机名,数据库密码。
网页复制内容需要修改:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://master:9000/hive/warehouse</value>
<description>location to default database for the warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hiveDB?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>Hive access metastore using JDBC connectionURL</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
<description>password to access metastore database</description>
</property>
<property>
<name>javax.jdo.option.Multithreaded</name>
<value>true</value>
</property>
<!-- 分割 -->
<property>
<name>hive.metasotre.schema.verification</name>
<value>true</value>
</property>
</configuration>
hive-site.xml修改内容
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://master:9000/hive/warehouse</value>
<description>location to default database for the warehouse</description>
</property>
这里的hdfs://master:9000/hive/warehouse应改为hdfs://loaclhost:9000/hive/warehouse。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hiveDB?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>Hive access metastore using JDBC connectionURL</description>
</property>
这里的jdbc:mysql://localhost:3306/hiveDB?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false,hiveDB应修改为自己在mysql建立的数据库。
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
<description>password to access metastore database</description>
</property>
对应位置为自己数据库账户及密码。
修改后完整hive-site.xml
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://localhost:9000/hive/warehouse</value>
<description>location to default database for the warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hiveDB?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>Hive access metastore using JDBC connectionURL</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>user</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>user</value>
<description>password to access metastore database</description>
</property>
<property>
<name>javax.jdo.option.Multithreaded</name>
<value>true</value>
</property>
<!-- 分割 -->
<property>
<name>hive.metasotre.schema.verification</name>
<value>true</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
<!--这里的线程数必须大于0 :理想状态和分桶数一致-->
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
4.HDFS创建目录
开启HDFS情况下,创建上述配置中的目录,并赋予权限:
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -mkdir -p /hive/warehouse
hdfs dfs -chmod -R g+w,o+w /tmp
hdfs dfs -chmod -R g+w,o+w /hive
g+/-w: filename 给同组用户增加filename文件的写权限, chmod go+rw filename 给同组和组外用户增加写和读的权限, chmod g-w filename 给同组用户去除写权限。
o+/-w:o表示other 其他组,w表示写,+/-表示增加/去除权限,整个命令的意思是给其他组的成员增加或者去除写权限。
5.初始化数据库
schematool -dbType mysql -initSchema
6.启动Hive
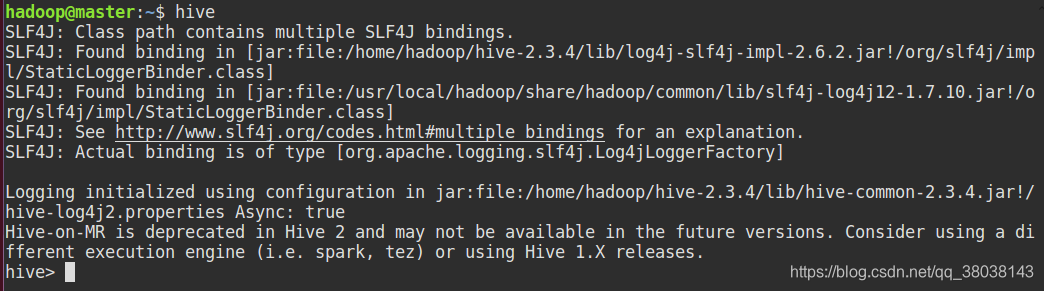
7.若选择mysql-connector-java-8连接器(2-7)
因未尝试,暂时不知是否可行
配置方式同1-1-4
hive客户端:
修改hive-site.xml
<configuration>
<!-- Hive 产生的元数据存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- 连接服务器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://slave2:9083</value>
</property>
</configuration>
修改hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/hadoop/hadoop-2.10.1
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/hive/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/usr/hive/hive/lib
hive服务端:
修改hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
对应hive-site.xml修改内容:
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/hadoop/hadoop-2.10.1
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/hive/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/usr/hive/hive/lib
有部分机器会报错有关publickey的错误 可以尝试改为
jdbc:mysql://slave1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true&allowPublicKeyRetrieval=true
初始化数据(在hive服务端上!)
本次配置好hive-site.xml之后执行初始化数据:
schematool -initSchema -dbType mysql
启动hive服务端
(本博客为slave2)
hive --service metastore
或者后台运行(作用相同,只不过这个命令可以继续操作别的命令)
hive --service metastore &
启动hive客户端
直接输入
hive
8.将hive导出到hbase(教程一:推荐)
1创建同步关联表
1.在Hive的命令行执行如下SQL创建Hive与HBase关联表
CREATE TABLE hive_hbase_table(
key int,
name String,
age String
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:name,cf1:age")
TBLPROPERTIES ("hbase.table.name" = "hbase_table", "hbase.mapred.output.outputtable" = "hbase_table");
复制

2.在HBase Shell命令行查看

3.删除hive_hbase_table表

再次登录HBase Shell查看hbase_table表已不存在被删除

可以看到通过上述命令创建Hive与HBase关联表,如果HBase表不存在时会自动创建,但通过Hive将表删除时也同时会删除与之关联的HBase表。
2.创建外部关联表
1.在HBase上创建一个hbase_hive表
hbase(main):003:0> create 'hbase_table','cf1'
hbase(main):004:0> list
复制

2.在Hive上执行如下SQL创建Hive与HBase关联的外部表
CREATE EXTERNAL TABLE hive_hbase_table(
key int,
name String,
age String
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:name,cf1:age")
TBLPROPERTIES ("hbase.table.name" = "hbase_table", "hbase.mapred.output.outputtable" = "hbase_table");
复制

3.在Hive上执行drop操作,HBase表不会被同步删除

HBase表依然存在不会被同步删除

可以看到通过创建Hive与HB 从vase的外部关联表,在删除Hive表的时候并不会同步的将HBase表删除。
3.Hive表导出到HBase表
1.准备一个hive的测试表,这里测试表的字段与之前创建的Hive与HBase关联表字段一致,为了能够方便的将数据导入到HBase表中
hive> create table hive_data (key int,name String,age string);
hive> insert into hive_data values(1,"za","13");
hive> insert into hive_data values(2,"ff","44");
hive> select * from hive_data;
复制
查看hive_data表的数据,插入数据成功。准备完毕。

2.通过如下SQL语句将hive表的数据导入到Hive与HBase的关联表中,从而实现Hive数据写入HBase
hive> insert into table hive_hbase_table select * from hive_data;
hive> select * from hive_hbase_table;
复制

然后在HBase中查看表hbase_table的数据,也同步了过来,数据与hive表中的数据一致,导入成功。
hbase(main):014:0> scan 'hbase_table'
复制

通过如上方式可以方便的将Hive表的数据写入到HBase表中,为线上业务提供数据服务。
总结
1.未使用EXTERNAL关键字创建Hive与HBase关联表时,如果HBase表不存在会自动创建,且删除Hive表的同时也会删除HBase表。
2.使用EXTERNAL关键字创建Hive与HBase关联表时,HBase表必须存在,且删除Hive表是不会删除HBase表。
3.通过Hive创建与HBase关联的表后,可以方便的使用SQL语句方便的向HBase表中写入数据。
9.将hive导出到hbase(教程一)
方案一:Hive关联HBase表方式
适用场景:数据量不大4T以下(走hbase的api导入数据)
一、hbase表不存在的情况
创建hive表hive_hbase_table映射hbase表hbase_table,会自动创建hbase表hbase_table,且会随着hive表删除而删除,这里需要指定hive的schema到hbase schema的映射关系:
1、建表
CREATE TABLE hive_hbase_table(key int, name String,age String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:name,cf1:age")
TBLPROPERTIES ("hbase.table.name" = "hbase_table",
"hbase.mapred.output.outputtable" = "hbase_table");


2、创建一张原始的hive表,准备一些数据
create table hive_data (key int,name String,age string);
insert into hive_data values(1,"za","13");
insert into hive_data values(2,"ff","44");
3、把hive原表hive_data的数据,通过hive表hive_hbase_table导入到hbase的表hbase_table中
insert into table hive_hbase_table select * from hive_data;
4、查看hbase表hbase_table中是否有数据

二、hbase表存在的情况
创建hive的外表关联hbase表,注意hive schema到hbase schema的映射关系。删除外表不会删除对应hbase表
[ ](javascript:void(0)😉
](javascript:void(0)😉
CREATE EXTERNAL TABLE hive_hbase_external_table(key String, name string,sex String,age String,department String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:sex,info:age,info:department")
TBLPROPERTIES ("hbase.table.name" = "filtertest",
"hbase.mapred.output.outputtable" = "filtertest");
[](javascript:void(0)😉
其他步骤与上面相同
方案二:HIve表生成hfile,通过bulkload导入到hbase
1、适用场景:数据量大(4T以上)
2、把hive数据转换为hfile
3、启动hive并添加相关的hbase的jar包
[](javascript:void(0)😉
add jar /mnt/hive/lib/hive-hbase-handler-2.1.1.jar;
add jar /mnt/hive/lib/hbase-common-1.1.1.jar;
add jar /mnt/hive/lib/hbase-client-1.1.1.jar;
add jar /mnt/hive/lib/hbase-protocol-1.1.1.jar;
add jar /mnt/hive/lib/hbase-server-1.1.1.jar;
[](javascript:void(0)😉
4、创建一个outputformat为HiveHFileOutputFormat的hive表
其中/tmp/hbase_table_hfile/cf_0是hfile保存到hdfs的路径,cf_0是hbase family的名字
create table hbase_hfile_table(key int, name string,age String)
stored as
INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.hbase.HiveHFileOutputFormat'
TBLPROPERTIES ('hfile.family.path' = '/tmp/hbase_table_hfile/cf_0');
5、原始数据表的数据通过hbase_hfile_table表保存为hfile
insert into table hbase_hfile_table select * from hive_data;
6、查看对应hdfs路径是否生成了hfile
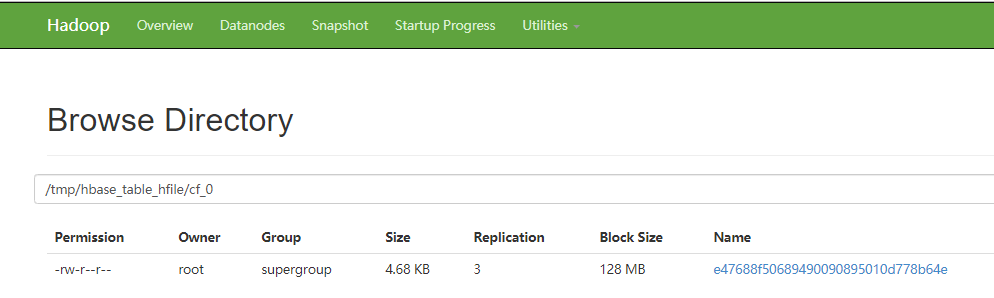
7、通过bulkload将数据导入到hbase表中
建表:使用hbase客户端创建具有上面对应family的hbase表
create 'hbase_hfile_load_table','cf_0'
下载hbase客户端,配置hbase-site.xml,并将hdfs-site.xml、core-site.xml拷贝到hbase/conf目录
导入:
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \
hdfs://master:9000/tmp/hbase_table_hfile/ hbase_hfile_load_table
8、查看

二、安装Mysql及Hive(方法二,不推荐可参考,该教程系统为CentOS与Ubuntu不同)
部分内容参照方法一
一、Hive安装
1.解压hive,移动到指定目录下
配置环境变量
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
2.在hive/conf目录下
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
3.修改hive-env.sh
因为 Hive 使用了 Hadoop, 需要在 hive-env.sh 文件中指定 Hadoop 安装路径:
export JAVA_HOME=/usr/java ##Java路径
export HADOOP_HOME=/usr/local/hadoop ##Hadoop安装路径
export HIVE_HOME=/usr/local/hive ##Hive安装路径
export HIVE_CONF_DIR=/usr/local/hive/conf ##Hive配置文件路径
MySQL安装
CentOS7默认数据库是mariadb,配置等用着不习惯,因此决定改成mysql,但是CentOS7的yum源中默认好像是没有mysql的。为了解决这个问题,我们要先下载mysql的repo源。
1.下载mysql的repo源
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
2.安装mysql-community-release-el7-5.noarch.rpm包
sudo rpm -ivh mysql-community-release-el7-5.noarch.rpm
安装这个包后,会获得两个mysql的yum repo源:
/etc/yum.repos.d/mysql-community.repo
/etc/yum.repos.d/mysql-community-source.repo
3.安装mysql
sudo yum install mysql-server
根据提示安装就可以了,不过安装完成后没有密码,需要重置密码
4.重置mysql密码
mysql -u root
登录时有可能报这样的错:
ERROR 2002 (HY000): Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘ (2)
原因是/var/lib/mysql的访问权限问题。下面的命令把/var/lib/mysql的拥有者改为当前用户:
sudo chown -R root:root /var/lib/mysql
5.重启mysql服务
service mysqld restart
6.接下来登录重置
mysql -u root //直接回车进入mysql控制台
use mysql;
update user set password=password('123456') where user='root';
exit;
三、创建HDFS目录
在 Hive 中创建表之前需要创建以下 HDFS 目录并给它们赋相应的权限。
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod g+w /user/hive/warehouse
hdfs dfs -chmod g+w /usr/hive/tmp
hdfs dfs -chmod g+w /usr/hive/log
四、配置jdbc的驱动
MySQL Java 连接器添加到 $HIVE_HOME/lib 目录下。我安装时使用的是 mysql-connector-java-5.1.43.jar。
五、Hive Metastore配置
默认情况下, Hive 的元数据保存在内嵌的 Derby 数据库里, 但一般情况下生产环境会使用 MySQL 来存放 Hive 元数据。
1.创建数据库和用户
假定你已经安装好 MySQL。下面创建一个 hive 数据库用来存储 Hive 元数据,且数据库访问的用户名和密码都为 hive。
mysql> CREATE DATABASE hive;
mysql> USE hive;
mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive';
mysql> GRANT ALL ON hive.* TO 'hive'@'localhost' IDENTIFIED BY 'hive';
mysql> GRANT ALL ON hive.* TO 'hive'@'%' IDENTIFIED BY 'hive';
mysql> FLUSH PRIVILEGES;
mysql> quit;
2.修改hive-site.xml
然后在配置文件hive-site.xml中,把所有的${system:java.io.tmpdir} 都替换为/usr/local/hive/tmp,把所有的${system:user.name}替换为${user.name}
直接修改为下面这样也可以,注意用户名和密码,对应上一步中mysql创建的用户名和密码。
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
3.创建/usr/local/hive/tmp文件夹
mkdir /usr/local/hive/tmp
4.运行Hive
在命令行运行 hive 命令时必须保证以下两点:
HDFS 已经启动。可以使用 start-dfs.sh 脚本来启动 HDFS。
1.运行 schematool 命令来执行初始化操作。
schematool -dbType mysql -initSchema
2.运行Hive
hive

 浙公网安备 33010602011771号
浙公网安备 33010602011771号