0.常用代码
常用代码
1.解压安装
sudo tar -zxf ~/下载/scala-2.13.8.tgz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./scala-2.13.8/ ./scala # 将文件夹名改为flume
sudo chown -R hadoop ./scala #给该文件夹赋予权限
sudo tar -zxvf ~/下载/scala-2.13.8.tgz -C /usr/local
tar 是Linux下经常使用的归档工具,对文件或者目录进行打包归档,归档成一个目录,但是并不进行压缩。
格式:
tar [主选项+辅助选项] 文件或目录
主选项 说 明
-c 新建文件
-r 把要归档的文件追加到档案文件的末尾
-t 列出档案文件中已经归档的文件列表
-x 从打包的档案文件中还原出文件
-u 更新档案文件,用新建文件替换档案中的原始文件
辅助选项 说 明
-z 调用gzip命令在文件打包的过程中压缩/解压文件
-w 在还原文件时,把所有文件的修改时间设定为现在时间
-j 调用bzip2命令在文件打包的过程中压缩/解压文件
-Z 调用compress命令过渡档案
-f “-f"选项后面紧跟档案文件的存储设备,默认是磁盘,需要指定档案文件名;
如果是磁盘,只需指定磁带设备名即可。
注意,在”-f"选项之后不能再跟任何其他选项,
也就是说,"-f"必须是tar命令的最后一个选项
-v 指定在创建归档文件过程中,显示各个归档文件的名称
-p 在文件归档的过程中,保持文件的属性不发生变化
ubuntu下运行name.sh文件
运行Linux.sh文件
进入到目录文件下
./name.sh
#or
bash name.sh
2.编辑环境变量
vim ~/.bashrc
source ~/.bashrc
3.开启和关闭相关服务
1.Hadoop
start-all.sh
stop-all.sh
2.Hbase
start-hbase.sh
stop-hbase.sh
注意:先开启Hadoop服务再开启Hbase服务,关闭先关Hbase服务再关Hadoop服务。
4.Ubuntu删除文件的命令
-r表示强制删除,-f表示不提示
强制删除文件夹并提示
sudo rm -r 文件夹名
强制删除文件夹不提示 (最暴力)
sudo rm -rf 文件夹名
5.sqoop 导入导出
1.连接数据库
jdbc串必须添加引号不然会报错;
sqoop list-tables --connect "jdbc:mysql://127.0.0.1:3306/moviedata?useSSl=false&characterEnconding=UTF-8" --username root --password root
sqoop list-tables --connect "jdbc:mysql://localhost:3306/hiveDB?useSSl=false&characterEnconding=UTF-8" --username 'root' --password 'root'
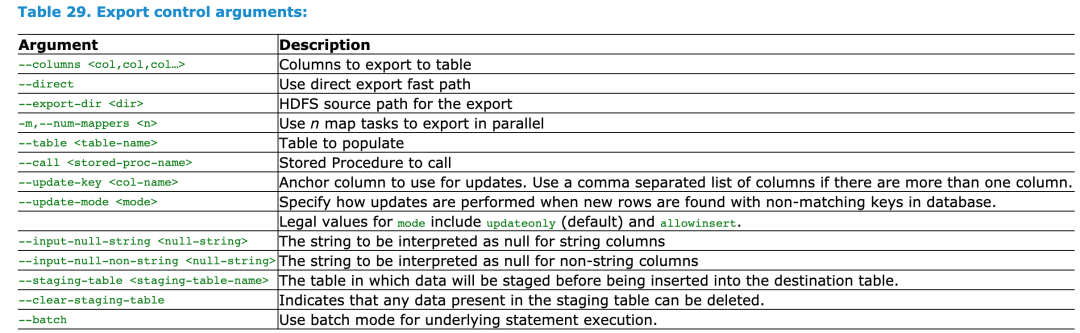
2.hive导出到mysql
sqoop export \
--connect "jdbc:mysql://127.0.0.1:3306/moviedata?characterEncoding=UTF-8&useSSL=false" \
--username root \
--password root \
--table movie_year_result_fangqiujian \
--export-dir /hive/warehouse/moviedata.db/movie_year_result_fangqiujian/* \
--input-fields-terminated-by '\001' \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
-m 1
参数说明:
--connect '数据库连接' \
--username '数据库账号' \
--password '数据库密码' \
--table '数据库表名' \
--export-dir 集群hdfs中导出的数据目录 \
--input-fields-terminated-by '分隔符,textfile类型默认\001' \
--input-null-string '空值处理:\\N' \
--input-null-non-string '空值处理:\\N'
--m 1 '即num-mappers的缩写,默认启动MapReduce数量:1个,不宜太多数据库顶不住,-m:表明需要使用几个map任务并发执行' \
## “--export-dir” 参数是数据在hdfs中的路径
## 可在hive中,通过 show create 表(即:show create dc_dev.export_txt_demo)
## 即可知道表数据在hdfs中的位置
3.mysql导入到hive
sqoop import \
--connect "jdbc:mysql://127.0.0.1:3306/moviedata?characterEncoding=UTF-8&useSSL=false" \
--username root \
--password root \
--table t_movie \
-m 1 \
--hive-import \
--create-hive-table \
--fields-terminated-by '\t' \
--hive-table moviedata.t_movie_fangqiujian1
4.sqoop从hive导入数据到hbase(通过mysql传递)
1.在Hive中建表
首先是操作过sogou数据了的,我需要导入的数据是基于之前操作的sogou的数据的
在hive中连接sogou数据库(之前创建的,翻之前的博客)
use sogou1
在hive的sogou数据库下新建表
CREATE TABLE sogou.uid_cnt(
uid STRING,
cnt INT)
COMMENT 'This is the sogou search data of one day'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;1234567

查询并插入
INSERT OVERWRITE TABLE sogou.uid_cnt SELECT uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid;1

2.使用 Sqoop 将数据从Hive导入 MySQL
mysql中新建数据库并连接
CREATE DATABASE my_test;1
use my_test1

mysql my_test中创建一个表uid_cnt
CREATE TABLE uid_cnt(
uid varchar(255) DEFAULT NULL,
cnt int(11) DEFAULT NULL
)DEFAULT CHARSET=utf8;1234
设置mysql的访问权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;1
FLUSH PRIVILEGES;1
进入sqoop安装目录开始导入数据
bin/sqoop export --connect jdbc:mysql://master:3306/my_test --username root -password 123456 --table uid_cnt --export-dir '/user/hive/warehouse/sogou.db/uid_cnt' --fields-terminated-by '\t'1
整理后代码:
sqoop export \
--connect "jdbc:mysql://localhost:3306/moviedata?characterEncoding=UTF-8&useSSL=false" \
--username root \
--password root \
--table uid_cnt \
--export-dir '/user/hive/warehouse/sogou.db/uid_cnt' \
--fields-terminated-by '\t'1

查看mysql中之前创建的表的内容
select * from uid_cnt1


hbase新建表
create 'uid_cnt', {NAME=>'f1', VERSON=>5}1
3.使用 Sqoop 从Mysql将数据导入 HBase
输入以下代码
bin/sqoop import --connect jdbc:mysql://master:3306/my_test --username root --password 123456 --table uid_cnt --hbase-table uid_cnt --column-family f1 --hbase-row-key uid --hbase-create-table -m 11
整理后代码:
sqoop import \
--connect "jdbc:mysql://localhost:3306/moviedata?characterEncoding=UTF-8&useSSL=false" \
--username root \
--password root \
--table uid_cnt \
--hbase-table uid_cnt \
--column-family f1 \
--hbase-row-key uid \
--hbase-create-table \
-m 1


查看数据
scan 'uid_cnt'1

这是通过mysql中转实现数据传递的
6.hbase基本命令
1、进入hbase的shell
hbase提供了一个shell的终端给用户交互
[root@hadoop3 conf]# hbase shell
退出使用quit或者ctrl+c
需要关闭hadoop的安全模式不然进行一些操作,比如scan会卡住
进入到hadoop的bin目录下
在启动hbase之前
[root@hadoop3 conf]# hadoop dfsadmin -safemode leave
2、创建表
create ‘表名’,’列族1’,’列族2’,…’列族n’
craete 'user','info1','info2'
3、查看所有表
list
4、描述表
describe 'user'
Table user is ENABLED
COLUMN FAMILIES DESCRIPTION
{NAME => 'info1', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KE
EP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'info2', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KE
EP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
2 row(s) in 0.0790 seconds
5、删除表
hbase(main):033:0> disable 'user'
0 row(s) in 1.4110 seconds
hbase(main):034:0> drop 'user'
0 row(s) in 0.2330 seconds
hbase(main):035:0> list
TABLE
0 row(s) in 0.0450 seconds
6、判断表是否存在
hbase(main):040:0> exists 'user'
Table user does exist
0 row(s) in 0.0980 seconds
7、向表中添加数据
hbase(main):041:0> put 'user','1234','info1:name','zhangsan'
0 row(s) in 0.1310 seconds
hbase没有直接修改操作,但是可以覆盖,只要rowkey跟列族列名一致就会覆盖
比如这里要修改上面插入数据的info:name为’eve’
hbase(main):041:0> put 'user','1234','info1:name','eve'
0 row(s) in 0.1310 seconds
hbase(main):042:0> scan 'user1'
ROW COLUMN+CELL
1234 column=info1:name, timestamp=1509304915052, value=eve
8、扫描整个表
hbase(main):043:0> scan 'user'
9、查询记录数
rowkey相同只算一条
hbase(main):066:0> count 'user'
2 row(s) in 0.0340 seconds
=> 2
10、查询
查询某一行
hbase(main):067:0> get 'user','1234'
COLUMN CELL
info1:age timestamp=1547125476542, value=18
info1:name timestamp=1547125469727, value=eve
info2:favor timestamp=1547125482454, value=eat
3 row(s) in 0.0330 seconds
查询某个列族:
hbase(main):068:0> get 'user','1234','info1'
COLUMN CELL
info1:age timestamp=1547125476542, value=18
info1:name timestamp=1547125469727, value=eve
2 row(s) in 0.0280 seconds
查询某个列:
hbase(main):068:0> get 'user','1234','info1'
COLUMN CELL
info1:age timestamp=1547125476542, value=18
info1:name timestamp=1547125469727, value=eve
2 row(s) in 0.0280 seconds
查询某个时间戳版本
不知道时间戳
先将这一个列族修改为能选择三个版本的列族,可以随便选择查多少个版本,查的版本只要比存的版本少就行
hbase(main):069:0> alter 'user' ,{NAME=>'info1',VERSIONS=>3}
hbase(main):070:0> get 'user','1234',{COLUMN=>'info1:name',VERSIONS=>3}
知道时间戳
hbase(main):071:0> get 'user', '1234', {COLUMN => 'info1:name',TIMESTAMP => 1538014481194}
11、删除记录
删除列族下的某一列
hbase(main):071:0> delete 'user','1234','info1:name'
0 row(s) in 0.0170 seconds
删除某一列族
hbase(main):072:0> delete 'user','1234','info2'
0 row(s) in 0.0230 seconds
删除某一行
hbase(main):073:0> deleteall 'user','1234'
0 row(s) in 0.0310 seconds
12、清空表
hbase(main):074:0> truncate 'user'
Truncating 'user' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.4540 seconds
hbase(main):075:0> scan 'user'
ROW COLUMN+CELL
0 row(s) in 0.0260 seconds
7.flume
终端:tail -f /.. #监听文件 ctrl+c:退出
flume-ng agent --conf conf --conf-file class3.conf --name a1 -Dflume.hadoop.logger=INFO,console
flume-ng agent -c . -f class3.conf -n a1 -Dflume.root.logger=INFO,console
8.mysql(参考)
select split(split(title,'(')[1],')')[0] from movies_fangqiujian;
#
select substring(title,-5,4) from movies_fangqiujian;
#
select substring(title,-5,4),count(substring(title,-5,4)) from movies_fangqiujian group by substring(title,-5,4);
#
select split(split(title,"\\(")[1],"\\(")[0] from movies_fangqiujian;\\为转义字符
#
select SUBSTR(title,-5,4) from movies_fangqiujian where title<>"title";
#
create table movies_year(year_ string) as SELECT SUBSTR(title,-5,4) FROM movies_fangqiujian WHERE title<>"title";
#
#select regexp_extract(title,"\\(\\d{4}\\)",1) from movies_fangqiujian where title regexp '\\d{4}';
select regexp_extract(title,"(\\d{4})",1) from movies_fangqiujian where title regexp '\\d{4}';
#
select year,count(1) from (select regexp_extract(title,".*\\((\\d{4}\\)",1) as year from movies_fangqiujian where title regexp '\\(\\d{4}\\)')t group by year;
#
select regexp_extract(title,".*\\(\\d{4})\\)",1) from movies_fangqiujian where title regexp '\\(\\d{4}\\)';
#
select explode(split(genres,’\\|’)) as type from movies_fangqiujian;
#那种类型电影最多
select type,count(type) as order_type from (select explode(split(genres,'\\|')) as type from movies_fangqiujian)t group by type order by order_type desc;
#
select movieId,AVG(rating) as avgrating from ratings_fangqiujian group by movieId order by avgrating desc limit 10;
#评分最高的电影top10
select * from (select movieId,AVG(rating) AS avgrating from ratings_fangqiujian group by movieId order by avgrating desc limit 10)t left join movies_fangqiujian on t.movieId = m.movieId;
#
select type,AVG(rating) as avgrating from (select movies_fangqiujian.*,r.rating from (select *,select explode(split(genres,'\\|')) as type from movies_fangqiujian;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号