

分布式链路追踪系统预研第二篇
本文为博主原创文章,未经博主允许不得转载。
在上篇随笔后,分布式链路在缓慢推进。一直没什么兴致写,zipkin使用elasticsearch作为数据完全是可行的。但是揉合这两者,就存在两种方案:
第一种,保持zipkin,替换掉存储。即保持zipkin架构,替换掉默认数据存储,改用elasticsearch作为存储。这完全是可行的,但是做出来的也仅仅是一个分布式链路追踪系统。zipkin官方有相应的多数据源的实现源码,有兴趣大家可以自行去git上看。
由于我们想要的不只是分布式链路追踪系统,我们往往要的是一套完善的日志分析、监控和分布式链路追踪于一身的系统。ELK实现日志分析,在此我们能否用ELK进行扩展,实现自己的调用链追踪。从方案上来看完全是可行的,我们可以利用zipkin的数据存储结构进行对接,使用zipkin查询elasticsearch数据作为调用链展示。
当然我们也可以利用自己收集的数据,自己根据google dapper自己写一套查询 分析展示调用链,不一定需要跟zipkin一致。
所以第二种方案脱离zipkin,扩展ELK实现自己的分布式链路追踪系统。根据google dapper思想,与zipkin大同小异,实现tracing service服务。架构简图如图:
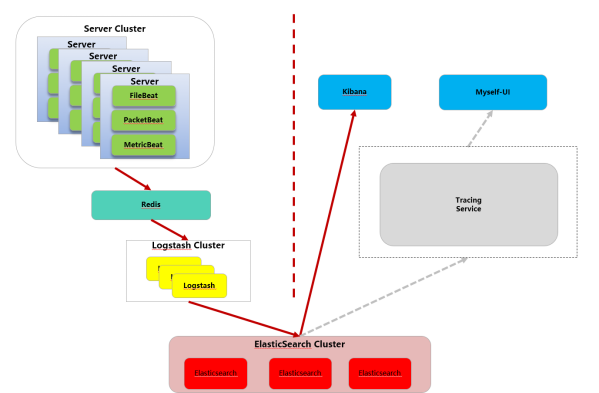
Tracing服务通过elasticsearch暴露的API,查询出我们需要的数据。然后数据分析成调用链结构,展示到UI层。这里Tracing作为一个服务暴露出去。
方案暂时如此,能否走通还需要时间验证。难免采坑,如:日志埋点现在的设计就比zipkin的粒度更细,所带来的问题也就越多。
也看了一些方案,其实都差不多,都是基于google dapper的想法,只是数据和实现效果上有所区别。
这里可以推荐大家去看的方案有:zipkin(twitter)、鹰眼(阿里)、hydra(京东)、tracing(窝窝)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号