
告别“从头训练”:微调,让你的AI模型快速“专业对口”
引言:为什么你需要关心“微调”?
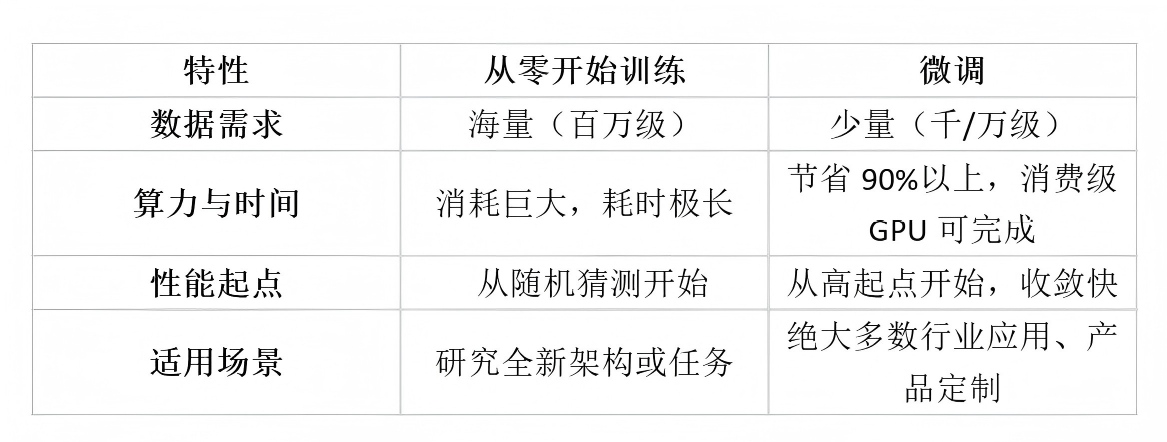
想象一下,你想训练一个AI来识别你家宠物狗的品种。最笨的办法是:收集数十万张各种狗的照片,搭建一个复杂的神经网络,然后投入海量算力和几周时间从头开始训练——这就像为了学做一道蛋炒饭,先从小麦育种、水稻种植开始学起,效率极低,且对大多数人来说根本不现实。
而“微调”提供的,是一条捷径。它允许你基于一个已经“博览群书”(在超大规模数据集上预训练好)的通用AI模型(比如能识别1000种物体的ResNet,或精通自然语言的BERT),只用自己相对少量的“专业资料”(你的宠物狗照片),对这个通才进行一番“针对性进修”,让它迅速变成“宠物狗识别专家”。
核心价值就是:用很少的数据、有限的算力,在较短时间内,获得一个针对你特定任务的高性能模型。 从智能客服、法律文书分析,到工业质检、医学影像辅助诊断,微调技术正是当前AI落地到千行百业的幕后英雄。
一、 技术原理:深入浅出拆解微调
让我们暂时忘掉复杂的数学公式,用三个关键词来理解微调。
1. 预训练:模型的“通识教育”
一个大型预训练模型(如GPT、ResNet、YOLO),就像一位在顶尖大学完成了通识教育的博士生。它通过阅读“互联网全书”(海量文本或图像数据),掌握了极其丰富且通用的知识:
· 对于CV模型:它学会了识别边缘、轮廓、纹理、基础形状,乃至猫、狗、汽车等常见物体的通用特征。
· 对于NLP模型:它理解了语法、语义、上下文逻辑,掌握了庞大词汇库和世界知识。
这个阶段耗费巨大(百万美金级的算力),但一旦完成,我们就获得了一个能力强大的“基础模型”。
2. 特征提取:知识的“分层抽象”
神经网络是分层结构。我们可以通俗地理解:
· 底层网络(靠近输入层):学习的是通用基础特征。例如,在图像模型中,第一层可能学的是“边缘”和“角点”;在文本模型中,可能学的是“词根”和“词性”。这些特征对几乎所有视觉或语言任务都有用。
· 高层网络(靠近输出层):学习的是抽象任务特征。例如,图像模型的最后一层,可能学的是如何组合下层特征来判断“这是一只拉布拉多犬”;文本模型的最后一层,可能学的是如何组织语言来进行“情感分析”。
预训练模型的价值,很大程度上在于其底层和中间层已经学会了优秀的通用特征提取能力。
3. 微调操作:针对性的“专业培训”
当我们要让这位“通才博士生”去当“皮肤科医生”时,微调就开始了:
**· **步骤A:架构微调****。将模型原本为通用任务设计的“最后一层”(比如输出1000类物体),替换为符合我们新任务需求的“新层”(比如输出2类:“健康皮肤”、“病变皮肤”)。
· 步骤B:参数调教(关键!)。我们用自己的“皮肤科专业资料”(少量医疗影像数据集)来训练这个修改后的模型。这里有重要策略:
· 初期冻结:先“冻结”模型底层参数的更新。因为这些底层提取的通用特征(边缘、纹理)对看皮肤也有用,我们暂时不动它们,让模型专注于学习高层与新任务相关的特征。
· 后期解冻:随后,可以“解冻”所有或部分网络层,用一个很小的学习率对整个模型进行精细化调整。小学习率是为了确保在适应新任务时,不会粗暴地“洗掉”模型原有的宝贵通用知识(这种现象称为“灾难性遗忘”),只是进行温和的校准。
简单比喻:微调不是从头造一辆车,而是拿到一辆性能优秀的全能越野车(预训练模型),然后根据你的需求(比如跑沙漠),有针对性地更换轮胎、调校悬挂(调整最后几层),并让司机(模型参数)稍微适应一下新环境(用新数据训练),它就变成了一辆专业的沙漠越野车。
二、 实践步骤:手把手带你微调一个模型(以图像分类为例)
让我们理论结合实践,假设我们要做一个“工地安全帽佩戴检测”分类模型(两类:佩戴、未佩戴)。
在开始实践前,一个高质量、标注好的数据集至关重要。对于图像类任务,你可以使用如Label Studio、CVAT 等开源标注工具自行标注,也可以在一些公开数据集平台或专业数据服务商寻找相关数据。
步骤1:准备你的专属数据集
- 收集数据:通过网络爬虫、现场拍摄等方式,收集约1000-5000张包含“佩戴安全帽”和“未佩戴安全帽”工人的图片。数据多样性很重要(不同光照、角度、背景)。
- 标注数据:将图片分为两个文件夹/helmet和/no_helmet,这就是最简单的图像分类标注。确保类别平衡。
步骤2:选择并加载预训练模型
这里我们选用经典的ResNet50(在ImageNet上预训练)。
import torchvision.models as models
import torch.nn as nn
# 加载预训练模型,并“冻结”其所有参数
model = models.resnet50(pretrained=True)
for param in model.parameters():
param.requires_grad = False # 冻结,不参与梯度更新
步骤3:修改模型输出层(架构调整)
ResNet50原输出为1000类(对应ImageNet),我们需要改为2类。
# 获取原模型最后一层(fc层)的输入特征数
num_features = model.fc.in_features
# 替换为一个新的全连接层,输出为2
model.fc = nn.Linear(num_features, 2)
# 注意:新添加的 fc 层参数默认 requires_grad=True,是可训练的
步骤4:配置训练环境(损失函数、优化器)
import torch.optim as optim
from torchvision import transforms, datasets
# 数据预处理和加载(使用PyTorch的DataLoader)
# ... (数据加载代码略)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 分类任务常用交叉熵损失
# 优化器只更新我们新添加的 fc 层参数(因为其他层被冻结了)
optimizer = optim.Adam(model.fc.parameters(), lr=0.001) # 初始使用较小学习率
步骤5:进行微调训练
先训练几轮只更新最后一层,然后可以解冻更多层进行精细化微调。
# 第一阶段:仅训练输出层
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for images, labels in train_loader:
# 前向传播、计算损失、反向传播、优化器更新(标准训练循环)
# ... (训练代码略)
# 第二阶段:解冻部分底层,使用更小的学习率进行全模型微调
for param in model.layer4.parameters(): # 举例:解冻ResNet的最后一个大块(layer4)
param.requires_grad = True
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 学习率调小一个数量级
# 继续训练更多轮次
# ... (继续训练代码略)
三、 效果评估:如何判断微调是否成功?
训练完成后,不能只看最后的准确率数字,需要多维度评估:
1. 基础指标:在独立的验证集/测试集上计算准确率、精确率、召回率、F1分数等。这是量化性能的基石。
2. 损失曲线:观察训练集和验证集的损失曲线。理想情况是二者同步平稳下降,最后收敛。如果验证集损失先降后升,可能出现了过拟合(模型只记住了训练数据,泛化能力差),这时需要增加数据、使用数据增强或更强的正则化。
3. 混淆矩阵:可视化模型具体在哪两个类别上容易混淆。例如,我们的模型是否容易将“戴黄色安全帽”误判为“未佩戴”?这能指导我们补充特定类型的数据。
4. 实际推理测试:用一些训练集之外的全新图片进行测试,观察模型在实际场景中的表现。这是终极检验,能发现数据分布偏差等问题。
成功的微调:模型在新任务测试集上表现优异,且损失曲线健康,对未见过的同类数据也有很好的泛化能力。
四、 总结与展望
总结一下,微调技术是我们将庞大、通用的AI能力“牵引”到具体、专业领域的桥梁。它完美地平衡了性能、效率与成本,是AI工程化应用的核心手段。
展望未来,微调技术本身也在进化:
· 更高效的微调方法:如LoRA、Adapter等,通过插入少量可训练参数而非修改整个模型,极大降低了微调的成本和存储开销。
· 提示词微调:对于超大规模语言模型,Prompt Tuning、Instruction Tuning等方法,让用户通过调整“提示词”而非模型权重来引导模型行为。
· 自动化微调:AutoML技术正被用于自动选择要微调的层、超参数等,让微调过程更加智能和便捷。
无论技术如何演变,其核心思想不变:站在巨人的肩膀上,让我们看得更远,走得更快。 希望这篇文章能帮你夯实基础,勇敢地迈出使用AI解决实际问题的第一步!
我个人比较推荐直接上手做一次微调,比如用 LLaMA-Factory Online 这种低门槛大模型微调平台,把自己的数据真正“喂”进模型里,生产出属于自己的专属模型。
即使没有代码基础,也能轻松跑完微调流程,在实践中理解怎么让模型“更像你想要的样子”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号