擦亮自己的眼睛去看SQLServer之整体介绍
也许你不需要了解SQLServer的内部机制,你照样能完成CRUD,而且可能完成的还不错,也许你不需要研究SQLServer的架构设计,你照样可以根据自己参与的项目经验设计出自己需要的架构,也许你会说不断的需求变化已经把自己的精力耗尽,也许你会说针对项目目前的情况不需要对SQLServer有较深的了解,也许你还会说我喜欢研究某某公司某产品,也许你还会觉得SQLServer太过庞大无从下手……
但是总有些问题迟早会促使我们(以SQLServer为主要存储数据容器的开发人员)开始踏上研究SQLServer的。比如你的数据库随着数据量增长性能越来越慢;再比如你的数据库经常莫名其妙挂掉;再比如你照着网络或者书籍上的各种清单优化和学习数据库时,发现他们很多地方不可靠;再比如你在做sql语句优化时你会发现对很多SQLServer输出信息不明白具体的意思…等等这些都再向你传递一个信息,你需要擦亮自己的眼睛去系统深入的学习SQLServer。而不是眯着眼睛简单了解一下。
园子有位朋友写的一篇<<程序员是否需要底层知识>>,其中有句尽量去打开身边的盒子,觉得很有道理。研究SQLServer后你会发现原来我们身边有设计这么好的产品值得我们研究。下面简单的从SQLServer产品结构、SQLServer数据库引擎结构、SQLServer执行模型三方面整体介绍一下SQLServer。
一、SQLServer2008产品结构
介绍这部分的主要原因是,总能发现不少人对SQLServer产品没有整体的了解。下面部分主要是照搬msdn,其中一部分加了自己的理解。在介绍之前有必要说下OLAP与OLTP。OLTP,联机事务处理。这是大部分基于数据库的项目中用到的。主要记录系统的具体交易事务。OLAP,联机分析处理。 这个经常是和BI密切相关,简单理解这是BI的的核心技术之一。下面的Analysis Services、Integration Services都属于OLAP范畴。
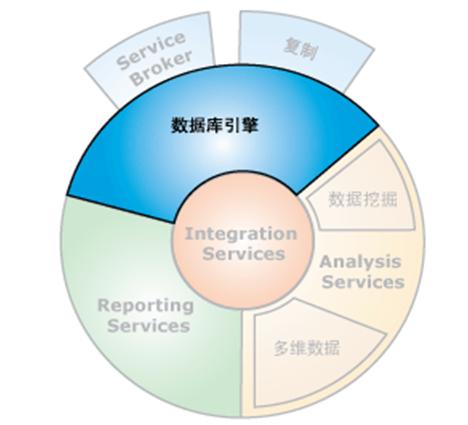
数据库引擎是用于存储、处理和保护数据的核心服务。数据库引擎提供了受控访问和快速事务处理,以满足企业内最苛刻的数据消费应用程序的要求。数据库引擎还提供了大量的支持以保持高可用性。这个组件可以说是SQLServer最核心最底层的部分,其他组件都依赖于数据库引擎。
Analysis Services(多维数据) 允许您设计、创建和管理包含从其他数据源(如关系数据库)聚合的数据的多维结构,从而实现对 OLAP 的支持。当然你可以不需要使用这个组件也能实现多维数据,但是它让你更加方便有效。
Analysis Services(数据挖掘) 使您可以设计、创建和可视化数据挖掘模型。通过使用多种行业标准数据挖掘算法,可以基于其他数据源构造这些挖掘模型。通过这个组件,可以方便你从数据中得到对于企业决策有效的信息。
Integration Services 是一个生成高性能数据集成解决方案的平台,其中包括对数据仓库提供提取、转换和加载 (ETL) 处理的包。
复制是一组技术,用于在数据库间复制和分发数据和数据库对象,然后在数据库间进行同步操作以维持一致性。使用复制时,可以通过局域网和广域网、拨号连接、无线连接和 Internet,将数据分发到不同位置以及分发给远程用户或移动用户。可以用在master-slave的设计中。
Reporting Services 提供企业级的 Web 报表功能,从而使您可以创建从多个数据源提取数据的表,发布各种格式的表,以及集中管理安全性和订阅。
Service Broker 帮助开发人员生成安全的可缩放数据库应用程序。这一新的数据库引擎技术提供了一个基于消息的通信平台,从而使独立的应用程序组件可作为一个工作整体来执行。Service Broker 包括可用于异步编程的基础结构,该结构可用于单个数据库或单个实例中的应用程序,也可用于分布式应用程序。二、SQLServer2008数据库引擎结构
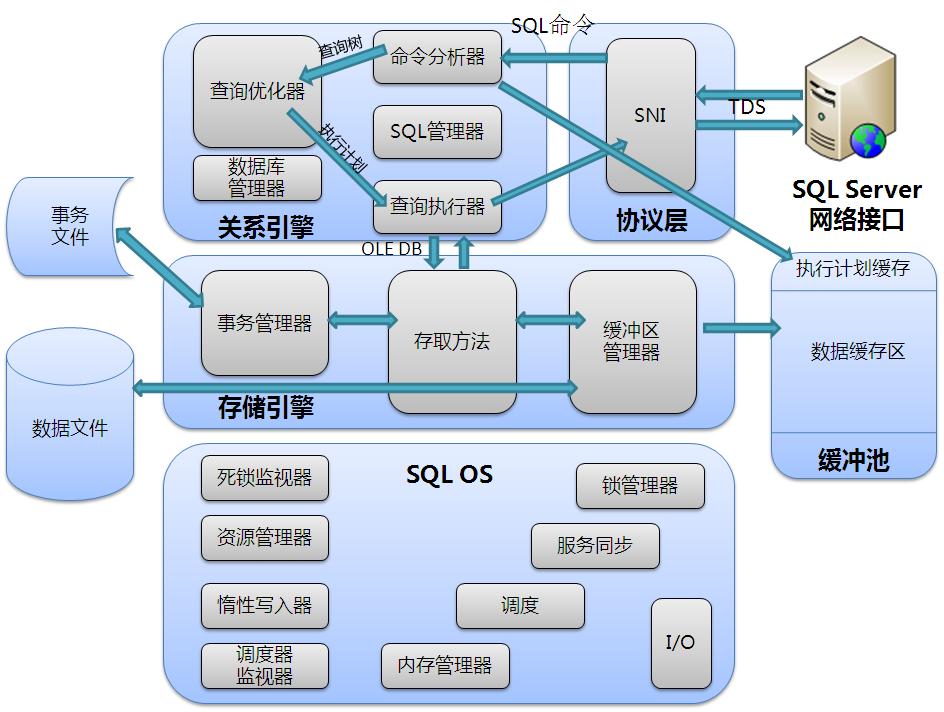
一、协议层(Protocol Layer)
当一个应用程序与SQL Server数据库引擎通讯时,协议层提供的应用程序编程接口利用微软自定义的tabular data stream(TDS)package来规范通讯格式。这一层的意义在于向应用程序提供访问SQL Server的接口。
SQL Server Network Interface(简称SNI)
SNI是在服务器和客户端之间建立网络连接的一种协议,他提供一组在数据库引擎和SQL Server客户端使用的API函数。SNI代替了SQL Server2000下的Net- Libraries组件和MDAC组件。主要是因为MDAC是随着Windows一起发布的,SQLServer小组在研发SQLServer2005后期去协调Windows中的MDAC是一件头疼的事情。所以他们决定SNI的解决方案,这意味这部分代码随着SQLServer一起发布。SQL Server支持共享内存(Shared memory)、TCP/IP、命名管道(Named Pipes)、虚拟接口适配器(Virtual Interface Adapter,即VIA)四种协议。一旦建立连接,SNI就会向服务器的TDS断点创建一条安全的连接,用来进行数据的请求和返回。
表格格式数据流端点(Tabular Data Stream,简称TDS)
TDS是一种微软具有自主知识产权的协议,原本是Sybase设计的。SQL Server在安装时为其支持的四种协议各创建一个端点,如果协议被激活,那么所有用户均可以使用这个协议。此外还有一个专门为专用管理员连接(DAC)而设置的端点。一条SQL语句则会通过TCP/IP连接以TDS消息的形式发送给SQL Server。
协议层(Protocol Layer)
一旦协议层接收到TDS包,就会在反转和解包工作,以找到所包含的请求。协议层也负责打包结果和状态消息,并以TDS消息的形式返回客户端。
二、关系引擎(Relational Engine)
关系引擎又成为查询处理器,包括用来确定某个查询所要做的操作及进行这些操作最佳方式的SQL Server组件。同时关系引擎也负责向存储引擎请求数据时查询的执行,并处理返回的结果。
命令分析器(Cmd Parser)
命令分析器处理发送给SQL Server的T-SQL语言事件。它会先检查T-SQL语法,并返回任何错误信息客户端,如果语法有效,就会进一步产生执行计划或者去查找一个已经存在的执行计划。命令解析器通过T-SQL哈希值向位于缓冲池中的Plan Cache发出匹配要求,以检查是否存在该执行计划;如果不存在则把T-SQL翻译成可以执行的内部格式,即查询树。
查询优化器(Optimizer)
查询优化器从命令解析器中获取查询树,并为它的实际执行做准备。生成执行计划的第一步是对每个查询进行规范化,规范化的过程有可能将单个查询分解成多个粒度合适的查询。然后进行最优化,SQL Server的查询优化器是基于成本的,它会选择它认为成本在合理时间范围内最低的执行计划,它使用一些内部指标(内存需求、CPU利用率和I/O需求数目)作为选择的依据。此外查询优化器还会考虑请求语句的类型、检查受到影响的各表的数据量、表中的索引,以及SQL Server统计数据。这部分可以说是SQLServer最智能最负责的部分。
SQL管理器
SQL管理器负责管理与存储过程及其计划有关的事务,并负责管理查询的自动化参数。
数据库管理器
数据库管理器管理查询编译和查询优化所需的对元数据的访问。比如,对SQL语法库的访问。
查询执行器(Query Executor)
查询执行器运行查询优化器生成的执行计划,根据执行计划中的步骤与存储引擎进行交互,检索或修改数据。
三、存储引擎(Storage Engine)
存储引擎包括存取方法、事务管理和缓冲区管理器。
存取方法(Access Methods)
SQL Server需要定位数据库时,会调用存取方法代码。它提供了一组代码,用来创建和请求对数据页面和索引页面进行扫描,并且将准备好的OLE DB数据行集返回给关系引擎。存取方法并不真正进行操作,它只负责向缓冲区管理器发出请求。存取方法不仅仅如此,它还会预测哪些数据页面索引页面即将处理,这样才能保证SQLServer高速处理。
事务管理器(Transaction Manager)
事务管理器包括两个组件:日志管理器和锁管理器。
锁管理器负责数据的并发保护和基于特定隔离级别的管理。
日志管理器负责将事务日志提前记录于日志文件中,从而起到保护数据的作用。访问方法代码请求的所有数据更改都必须记入日志中,这种方式称为预写日志。这是数据修改(插入、更新、删除、分配释放区和页、创建删除索引等)唯一总是写磁盘的的操作。它记录的是修改操作发生以后数据页面发生的改变,因此我们很难从中发现有意义的信息。除非用些第三方的工具。
缓冲区管理器(Buffer Manager)
缓冲区管理器用来管理缓冲区内存池中数据页面的分布。所有对数据的操作,都是先在缓冲区中操作的。然后由SQLOS中的检查点或者是惰性写入器同步到磁盘中。这样能保证SQLServer更快的响应请求。操作完成后就结果返回给访问方法。
四、缓冲池
缓冲池是SQLServer最消耗内存的部分。主要包含执行计划缓存和数据缓存。
五、SQLOS
可以理解为是SQLServer的资源管理器,主要负责与操作系统中的一些交互操作。如:内存分配、资源调度、I/O操作、进程线程管理以及同步、闩锁等等。这部分在此不展开,后期考虑专门写一章。
三、SQLServer执行模型
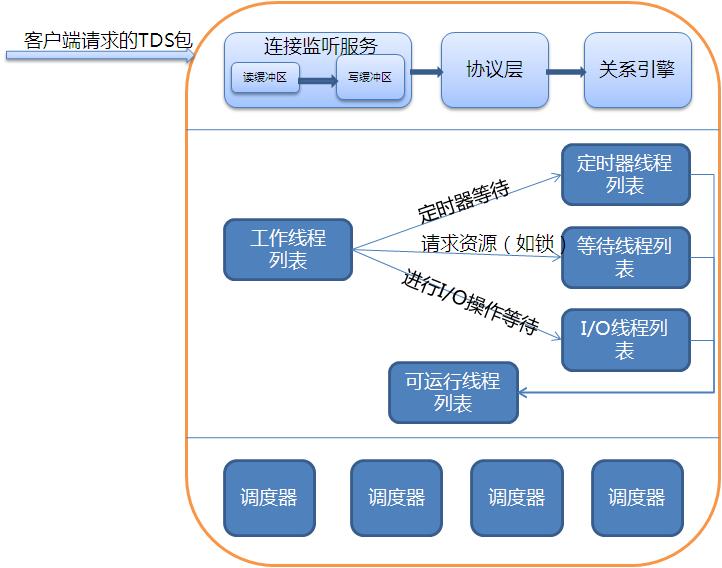
从图中可以看出,我这的执行模型也说的是整个SQLServer服务端在接收请求时,要发生的事情。但是和前面一样,SQLServer很多时候很多细化过于复杂没有办法能用一章图描述清楚。这个图简单的说明了SQLServer的执行模型。在分析这个图前,要明确一个问题。SQLServer是基于C/S的结构的产品。这样很明显就分为客户端与服务端。平时管理数据库的MSSMS以及我们需要访问数据库的系统就是属于SQLServer的客户端,SQLServer服务端主要是由一些服务方式构成。
因为是C/S,那么客户端的所有请求都必须传输到服务端,才能被执行。这样的话就涉及的双方通信的协议,这个协议在SQLServer2005后,就称为SNI。包的格式就是TDS。客户端的TDS通过SQLServer支持的协议传输到SQLServer服务端,服务端有一个组件叫连接监听服务,它一直在监听这请求端口。它负责监听新的连接,清除失败连接,将结果集、消息和状态返回给客户端。连接监听服务会把包发送给协议层,协议层对这个包进行解包,提取里面要执行的SQL语句,交给关系引擎,关系引擎经过处理后生成执行计划,并且执行计划。一旦关系引擎开发执行工作计划时,就会创建任务对象。任务对象必须关联一个空闲工作线程。工作线程关联到新任务后,状态设置为初始化。当完成初始化后,工作线程就转成为可运行。这时工作线程就准备就绪,只要有空闲的调度器就可以执行了。如果执行过程中遇到定时器等待、请求资源等待、I/O等待就会挂起移至相应的列表中。SQLServer采用了非抢占式调度。一个线程会完成这个任务的操作。不存在上下文切换,当然如果不是SQLServer的代码则采用抢占式调度,比如扩展存储过程。
今天分析就到此结束,文中如有描述不当的地方,欢迎指出。共同进步才是硬道理。
