python爬虫学习基础之网页解析(1)re正则
网页解析:从网页中提取出所需的信息(例如新的url,数据等等)
网页解析常用的方法有:re(正则表达式),BeautifulSoup,lxml,parsel,requests-html
这一篇只讲re,以后每一会发一篇文章,敬请期待吧
官方文档:re --- 正则表达式操作 — Python 3.9.9 文档
为了便于理解我先举一个实例:
上代码:
import re text="电话号码:(86)180 145322356575." a=re.findall('电话号码:',text) #在text中查询 "电话号码:" 的字符串,返回为列表a['电话号码:'] print(a)
运行结果:
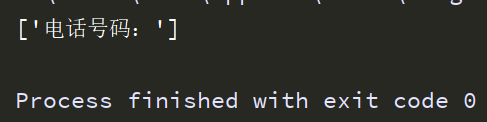
把a= 的部分改成 a=re.findall('码号11:',text),找一个不存在于text的字符串
运行结果:
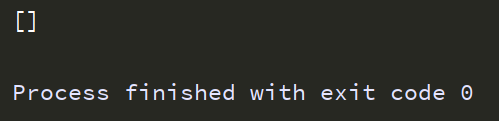
我们有时候的url链接只是数字不同,需要特定的字符串就可以利用re进行匹配。
一、正则表达式模式
模式 代表
. 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
^ 匹配字符串的开头
$ 匹配字符串的末尾。
* 对它前面的正则式匹配0到任意次重复,尽量多的匹配字符串。
例如: ab* (b出现0到任意次)所以匹配结果有: 'a','ab',或者 'a' 后面跟随任意个 'b'。
+ 匹配前一个元字符1到多次
例如:ab+ (b出现1次及以上)所以匹配结果有:'ab' 或 ’a’后面跟随1个以上到任意个 'b'。
? 匹配前一个元字符0到1次
例如:ab? (b出现0或1次)所以匹配结果有: 'a' 或者 'ab'。
{m,n} 匹配前一个元字符m到n次
\\ 转义字符'\'
[] 字符集,一个字符的集合,可匹配其中任意一个字符
| 逻辑表达式 或 ,比如 a|b 代表可匹配 a 或者 b
(...) 分组,默认为捕获,即被分组的内容可以被单独取出,默认每个分组有个索引,从 1 开始,按照"("的顺序决定索引值
(?iLmsux) 分组中可以设置模式,iLmsux之中的每个字符代表一个模式,用法参见 模式 I
(?:...) 分组的不捕获模式,计算索引时会跳过这个分组
(?P<name>...) 分组的命名模式,取此分组中的内容时可以使用索引也可以使用name
(?P=name) 分组的引用模式,可在同一个正则表达式用引用前面命名过的正则
(?#...) 注释,不影响正则表达式其它部分,用法参见 模式 I
(?=...) 顺序肯定环视,表示所在位置右侧能够匹配括号内正则
(?!...) 顺序否定环视,表示所在位置右侧不能匹配括号内正则
(?<=...) 逆序肯定环视,表示所在位置左侧能够匹配括号内正则
(?<!...) 逆序否定环视,表示所在位置左侧不能匹配括号内正则
(?(id/name)yes|no) 若前面指定id或name的分区匹配成功则执行yes处的正则,否则执行no处的正则
\number 匹配和前面索引为number的分组捕获到的内容一样的字符串
\A 匹配字符串开始位置,忽略多行模式
\Z 匹配字符串结束位置,忽略多行模式
\b 匹配位于单词开始或结束位置的空字符串
\B 匹配不位于单词开始或结束位置的空字符串
\d 匹配一个数字, 相当于 [0-9]
\D 匹配非数字,相当于 [^0-9]
\G 匹配最后匹配完成的位置。
\s 匹配任意空白字符, 相当于 [ \t\n\r\f\v]
\S 匹配非空白字符,相当于 [^ \t\n\r\f\v]
\w 匹配数字、字母、下划线中任意一个字符, 相当于 [a-zA-Z0-9_]
\W 匹配非数字、字母、下划线中的任意字符,相当于 [^a-zA-Z0-9_]
\n, \t, 等. 匹配一个换行符。匹配一个制表符。等
\1...\9 匹配第n个分组的内容。
\10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。
讲几个比较常用的组合方式
*?,+?,??
-
'*','+',修饰符都是 贪婪的;它们在字符串进行尽可能多的匹配。如果正则式<.*>希望找到'<a> b <c>'。在修饰符之后添加
?将使样式以 非贪婪`方式或者 :dfn:`最小 方式进行匹配; 尽量 少 的字符将会被匹配。 使用正则式<.*?>将会仅仅匹配'<a>'。
(.*) 任意字符出现任意次数,贪婪模式
(.*?) 代表非贪婪模式,也就是说只匹配符合条件的最少字符
二、了解它一些常用的方法
1、re.match函数:
功能: 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
函数语法:re.match(pattern, string, flags=0)
参数解释:
参数 作用
pattern 匹配的正则表达式
string 要匹配的对象,类型是字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
例子:
import re # 要匹配的字符串 text='12adgdfgh@#%$^$^' # 从开头匹配一个数字 str=re.match('\d',text) print('\d的匹配结果',str) # 从开头匹配两个连续数字 str=re.match('\d\d',text) print('\d\d的匹配结果',str) # 从开头匹配两个连续数字,第三个任意 str=re.match('\d\d.',text) print('\d\d.的匹配结果',str) # 从开头匹配三个连续数字,显然在这个字符串中不存在,返回空None str=re.match('\d\d\d',text) print('\d\d\d的匹配结果',str)
运行结果:
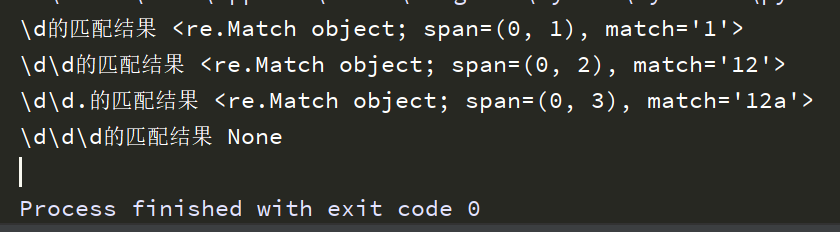
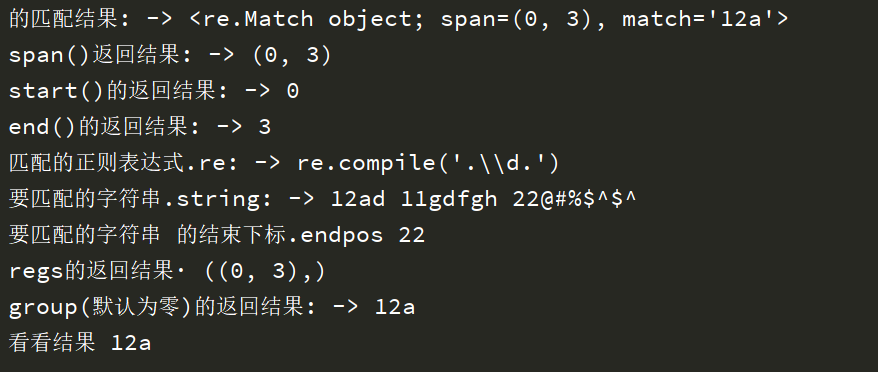
re.Match object说明这里的str为re匹配结果的对象。span说明其范围,match说明匹配的结果
有没有感觉匹配的结果对象不是我们最后想要的,所以我们需要再对这个对象再进一步操作。
import re # 要匹配的字符串 text='12ad 11gdfgh 22@#%$^$^' str=re.match('.\d.',text) print('的匹配结果: ->',str) # span(),与str里面的span一致 print('span()返回结果: ->',str.span()) # start()结果的初始下标,如果str为空则会报错 print('start()的返回结果: ->',str.start()) # 与start相同,不过为结果的最后下标 print('end()的返回结果: ->',str.end()) # 匹配的正则表达式 print('匹配的正则表达式.re: ->',str.re) # 要匹配的字符串 print('要匹配的字符串.string: ->',str.string) # 要匹配的字符串 的结束下标 print('要匹配的字符串 的结束下标.endpos',str.endpos) # print('regs的返回结果·',str.regs) # 将匹配结果输出 print('group(默认为零)的返回结果: ->',str.group(0)) # 利用regs与group对比,其实是一致的。 print('看看结果',text[0:3])
运行结果:
2、re.search函数
功能:re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:re.search(pattern, string, flags=0)
参数解释:
参数 作用
pattern 匹配的正则表达式
string 要匹配的对象,类型是字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
可以看出与match()差不多。search就是不一定是在,要匹配的字符串的开始位置。但match不在开始位置就是None。
import re text = 'big Dog 11a small 222 dog'
# 在字符串中匹配出第一个2连续的数字 str = re.search('\d\d', text) print(str)
运行结果:

3、re.sub函数
功能:re.sub用于替换字符串中的匹配项
函数语法:re.sub(pattern, repl, string, count=0, flags=0)
参数解释:
参数 作用
pattern 正则中的模式字符串(要被替换的一些字符串)
repl 替换成什么字符串,可以为函数
string 在哪一个字符串中使用替换
count 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
这个直接上代码:
import re text = '1 it is, 2 he is, 3 she is' # 用was替换is str = re.sub('is','was', text,0) print('用was替换is,结果:',str) # 用number代替数字 str1 = re.sub('/d','number',text,0) print('用number代替数字,结果是:',str1)
运行结果:

4、re.compile函数
功能:函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法:re.compile(pattern[, flags])
参数解释:
pattern : 一个字符串形式的正则表达式
flags :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
上代码:
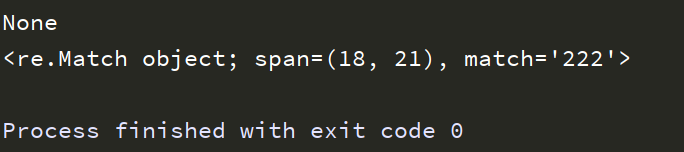
import re text = 'big Dog 11a small 222 dog' # 连续三个数字 pattern_object = re.compile('\d\d\d') str = pattern_object.match(text) print(str) str1 = pattern_object.search(text) print(str1)
运行结果:
5、findall函数
功能:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
语法:re.findall(pattern,string,flags)
参数解释:
pattern:匹配的正则表达式
string : 待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
另外一种
语法:re.compile的对象.findall(string, pos, endpos)
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
如果只写string就是默认的从整个string中找
代码:
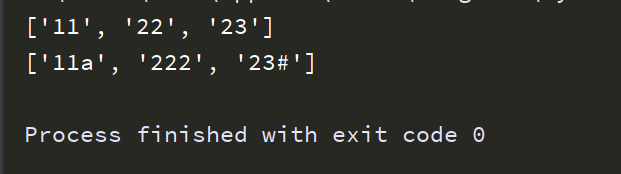
import re text = 'big 11a small 222 and 23###@@' # re.findall() # 连续两个数字 str = re.findall('\d\d',text) print(str) # re.compile对象.findall() # 前两个为数字的三个字符串 pattern_object = re.compile('\d\d.') str1 = pattern_object.findall(text) print(str1)
运行结果:
6、finditer函数
和 findall 用法一致,不同的是返回的结果数据类型不同,finditer返回一个迭代器。
代码
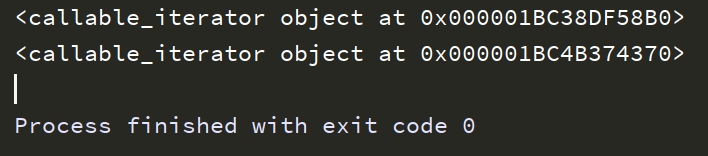
import re text = 'big 11a small 222 and 23###@@' # re.findall() # 连续两个数字 str = re.finditer('\d\d',text) print(str) # re.compile对象.findall() # 前两个为数字的三个字符串 pattern_object = re.compile('\d\d.') str1 = pattern_object.finditer(text) print(str1)
运行结果:
7、re.split函数
功能:split 方法按照能够匹配的子串将字符串分割后返回列表
语法:re.split(pattern, string, maxsplit=0, flags=0)
参数解释:
pattern:匹配的正则表达式
string : 待匹配的字符串。
maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
后面两个可以不用写,有默认的。也可以用于re.compile对象,参数没了pattern,flags。
代码:
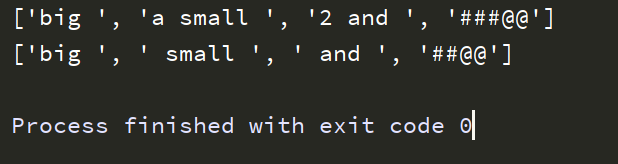
import re text = 'big 11a small 222 and 23###@@' str = re.split('\d\d',text) print(str):
pattern_object = re.compile('\d\d.') str1 = pattern_object.split(text) print(str1)
运行结果:
三、正则表达式修饰符 - 可选标志(就是上面函数的参数flags)
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
模式 作用
re.I:使匹配对大小写不敏感
re.L:做本地化识别(locale-aware)匹配
re.M:多行匹配,影响 ^ 和 $
re.S:使 . 匹配包括换行在内的所有字符
re.U:根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X:该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
1、re.I的例子(区分的时候不区分大小写)
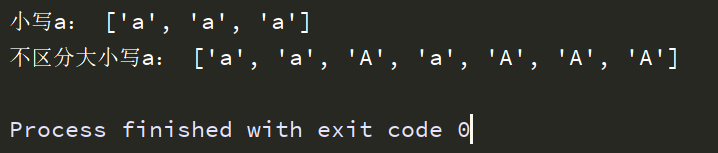
text = 'is a, was A and AAA...' or_str = re.findall('a',text) print('小写a:',or_str) # flags可以省略 str = re.findall('a',text,flags=re.I) print('不区分大小写a:',str)
运行结果:
2、re.L(做本地化识别(locale-aware)匹配)
使预定字符类 \w \W \b \B \s \S 取决于当前区域设定,比如在转义符\w,在英文环境下,它代表[a-zA-Z0-9_],即所以英文字符和数字。如果在一个法语环境下使用,缺省设置下,不能匹配"é" 或 ""。加上这L选项和就可以匹配了,不常用。
3、re.M(多行匹配,影响 ^ 和 $)
改变 ^ 和 $ 的行为,^匹配开始位置,这种模式下匹配每一行的开始,$匹配结束位置,这种模式下匹配每一行的结束。
例子:
import re text ='1\n2\na\n3\n4' print('text=\n',text) or_str = re.findall('^\d',text) print('没有re.M:',or_str) # flags可以省略 str = re.findall('^\d',text,flags=re.M) print(' 有re.M:',str)
运行结果:

4、re.S(使 . 匹配包括换行在内的所有字符)
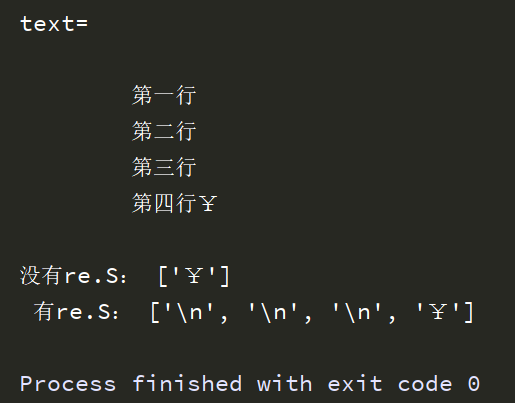
例子:
import re text =''' 第一行 第二行 第三行 第四行¥ ''' print('text=\n',text) # 匹配‘行’后面的一个任意字符,但不能是换行符 or_str = re.findall('行(.)',text) print('没有re.S:',or_str) # 匹配‘行’后面的一个任意字符,可以包含换行符 str = re.findall('行(.)',text,flags=re.S) print(' 有re.S:',str)
运行结果:
5、re.U(根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.)(好像pythonprint()默认会自动转化不用re.U也可以)
例子:
import re text ='=\u4f60=\u597d=我' # 匹配=后面的任意一个字符,会自动转化成Unicode编码(就是:\u..)对应的字符 str = re.findall('=(.)',text,re.U) print(' 有re.S:',str)
运行结果:

6、re.X:该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
冗余模式,这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释,方便理解。
import re text =''' aa 哎 11 ''' # 会把#你好当成匹配的字符串 or_str = re.findall('\d\d#你好',text) print('没有re.X:',or_str) # re.X会忽略正则表达式中的#号后面,只适用于每一行如果换行了,上一行的#管不了这一行的 str = re.findall('''\d\d#你好\d''',text,re.X) print(' 有re.X:',str)
运行结果:

爬虫案例可以看:python爬虫学习基础之re正则案例 - 宇一心途 - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号