python爬虫小刀牛试之搜狗图片
引言:
进过前戏的讲解,应该都有一些了解了吧。接下来就进入正题吧。
为了增加大家的兴趣,我就从搜狗图片的爬取讲解吧
python爬虫的步骤:
一般为四步骤:
1、发起请求
对服务器发送请求需要的url进行分析,与请求需要的参数
2、获取响应内容
如果服务器能正常响应,则会得到一个Response的对象,该对象的文件格式有:html,json,图片,视频等
3、解析内容
如果我们需要的信息在网页(html文件)里面,则需要提取网页的某种信息,称为:解析html数据:方法有
正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
对爬取到的数据进行存储。
文件
数据库(MySQL,Mongdb、Redis)
爬取的网页:搜狗图片搜索 - 上网从搜狗开始 (sogou.com)
一、先分析一下url链接:

搜索1图片回车之后的链接。
https://pic.sogou.com/pics?query=1&w=05009900
氧气美女
https://pic.sogou.com/pics?query=%E6%B0%A7%E6%B0%94%E7%BE%8E%E5%A5%B3&w=05009900
两个链接会发现只有 query= 的内容不同,搞明白就好。英语好的可以知道query是查询的意思。
你可以试一下把&w=和后面的一起删除,你会发现结果是一样的。
参考:(23条消息) python网址编码转换_python实现中文转换url编码的方法_weixin_39996134的博客-CSDN博客
这里我直接用:
from urllib.parse import quote
key=quote('氧气美女')
把括号里面的中文可以替换你想要的即可,它会自动转换为query需要的字符串。
二、网页分析
win+F12,开发者,点击网格,会发现什么也没有ctrl+R刷新
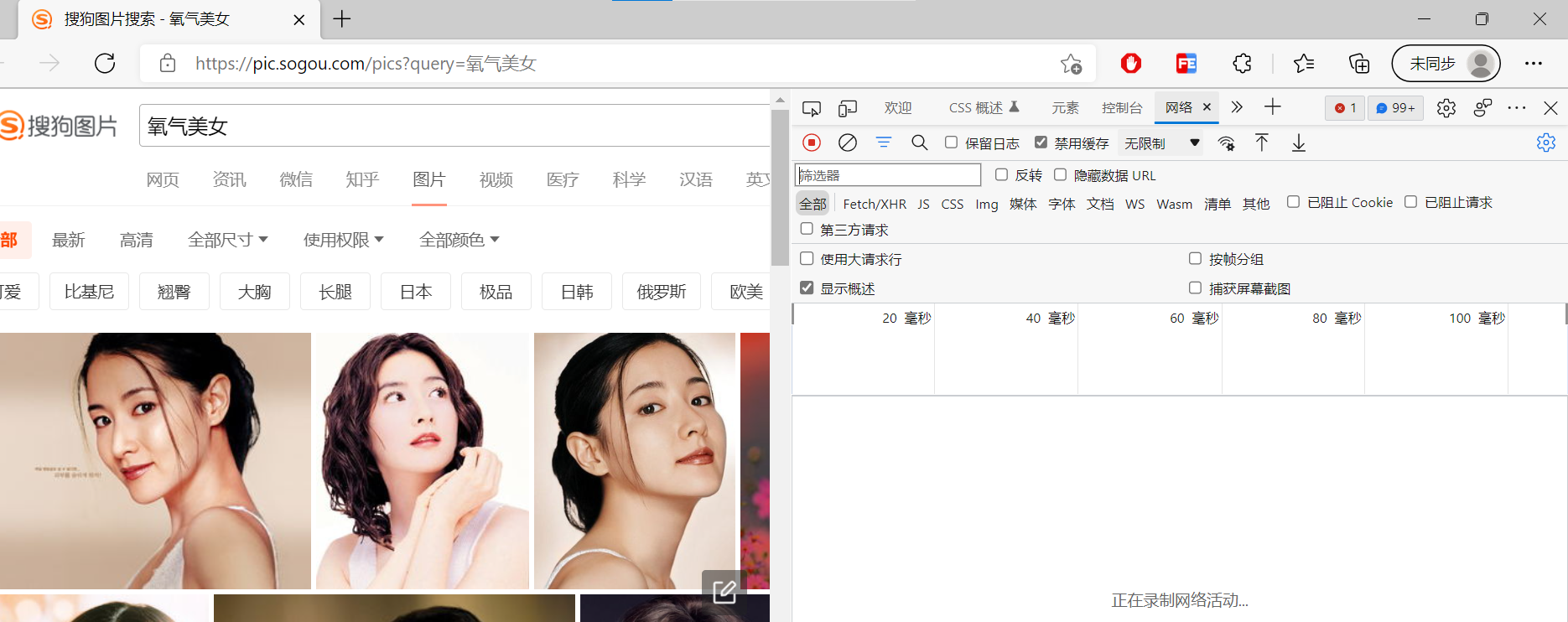
我先说明一下,Sogou是动态加载图片的,需要再分析一下链接。这里需要通过分析XHR。
因为每一页加载的图片是有限的,通过不断的往下滑它会动态的加载下一页。
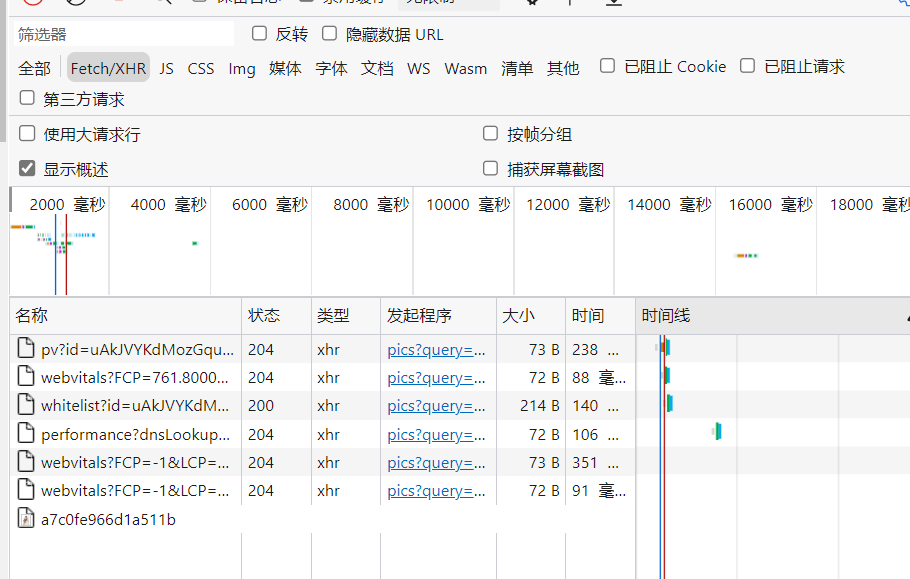
通过不停的往下滑动,不断地加载图片。会发现它会不断地出现一个重复的searchList?mode
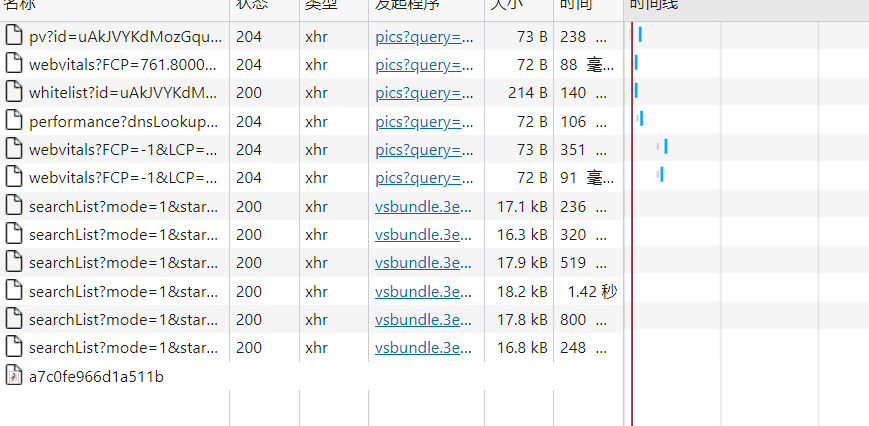
通过分析每一页的请求url
第一个:
https://pic.sogou.com/napi/pc/searchList?mode=1&start=48&xml_len=48&query=氧气美女
第二个:
https://pic.sogou.com/napi/pc/searchList?mode=1&start=96&xml_len=48&query=氧气美女
对比可知道只有start=的数字不同,由len可知道每一页有48张图片,所以每次的开始是48的倍数
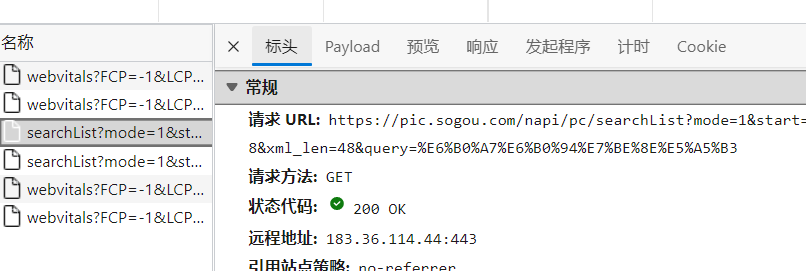
再通过预览分析图片需要的片头url,与名字
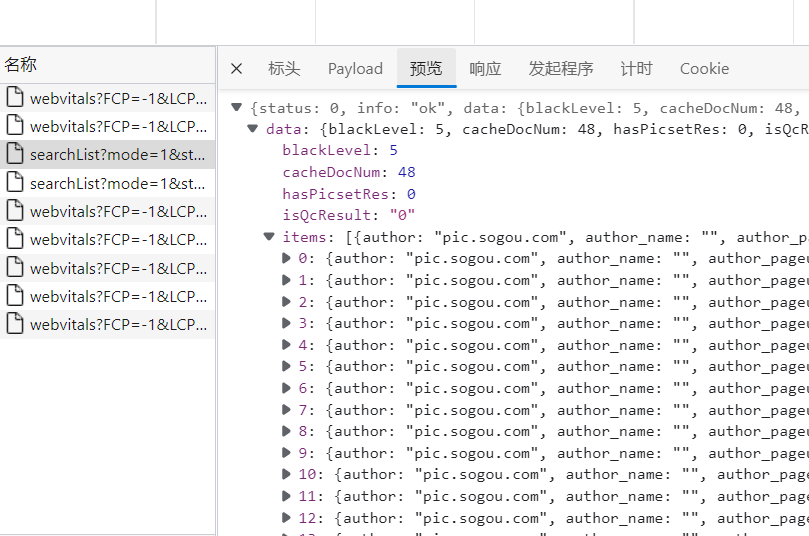

可以看到真的有48个
进过分析图片的地址是thumbUrl的值(具体是:['data']['items']['thumbUrl'])

其实oriPicUrl要高清许多,但是需要用到后面的知识。

图片名字title(具体是:['data']['items']['title']):

三、实现代码(注意本代码只用于学习交流,要遵守网络协议,切勿用于商业)
import requests from urllib.parse import quote # 搜索的内容 key = quote('氧气美女') # 第几页, 每一页有48张图片。每一页的开始是48的倍数 page=2 start=(page-1)*48 # 拼接url链接 # .format的括号()里面的会代替花括号{},且按顺序一对一,例如第一个{}用start代替,第二个{}用key代替 url = 'https://pic.sogou.com/napi/pc/searchList?mode=1&start={}&xml_len=48&query={}'.format(start,key) # 发送请求,对url对应的服务器发送 response = requests.get(url) # response把它转化为json的数据格式,才能用类似于字典的数据,来获取对应的值 json_data = response.json() all_data = json_data['data']['items'] # 图片的url,下载图片的url pic_urls=[] # 图片的title,保存图片的名字 pic_titles=[] for data in all_data: url = data['thumbUrl'] # 把url添加到pic_urls pic_urls.append(url) # 把title添加到pic_titles title = data['title'] pic_titles.append(title) # 保存 for number in range(len(pic_titles)): data=requests.get(pic_urls[number],timeout=5).content # 写入文件,以jpg with open('./'+pic_titles[number]+str(number)+'.jpg','wb')as file: file.write(data) print(number,'-----------------',pic_titles[number],'下载好了------------------')
每次只需要改变
# 搜索的内容
key = quote('氧气美女')
与 page=2
两个地方即可获取不同的图片。
下一篇文章我会着重于怎样解析网页

 浙公网安备 33010602011771号
浙公网安备 33010602011771号