pyhton爬虫学习基础之前戏
为了方便后面的学习,我将先介绍一些知识。
一、先对爬虫有一定的知识了解:
定义:网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
分类:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web。
通用网络爬虫的结构大致可以分为页面爬行模块、页面分析模块、链接过滤模块、页面数据库、URL 队列、初始 URL 集合几个部分。
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。 和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面。
聚焦网络爬虫和通用网络爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性。
增量式网络爬虫(Incremental Web Crawler)是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
增量式网络爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL 集]。
二、接着对爬取的对象去了解
(UniformResourceLocation的缩写)统一资源定位系统是因特网的万维网服务程序上用于指定信息位置的表示方法。因特网上的可用资源可以用简单字符串来表示,这些字符串则被称为:“统一资源定位器”(URL)。url是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
URL = HTTP协议 + 域名 + 路径 + 查询参数 + 锚点。

User-agent: * 这里的*代表的所有的搜索引擎种类。
Disallow:是不允许爬取什么。
Allow: 是允许爬取什么。
4、原理:用户发送请求,服务器响应求情(向url对应的服务器发送请求)。
前戏讲完了,可以切入。
具体看一下网页的请求与响应的一些相关知识。
F12开发者,或者右键检查。

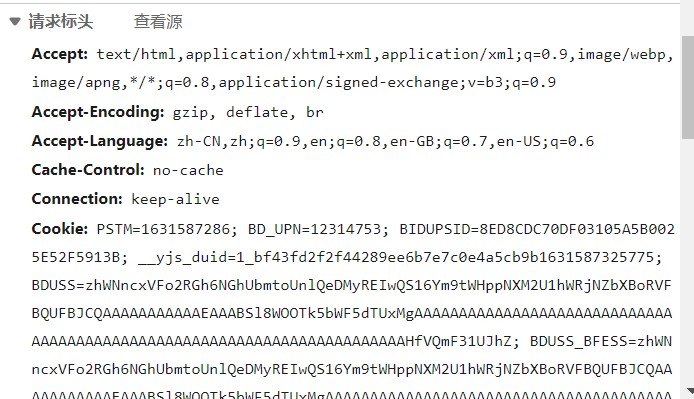
响应的信息
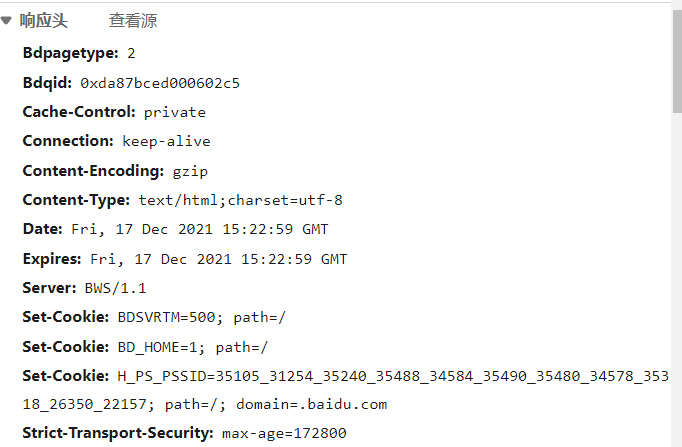
具体的可以参考:(23条消息) HTTP协议简介(请求头、响应头、请求方式)请求协议、响应协议_白骨梦儿-CSDN博客_http请求协议
5、网页请求的方式也分为两种:
GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
三、python爬虫需要安装request模块。
大致分为两类
1、用管理员身份启动cmd控制台:
win+R,然后输入cmd回车进入。
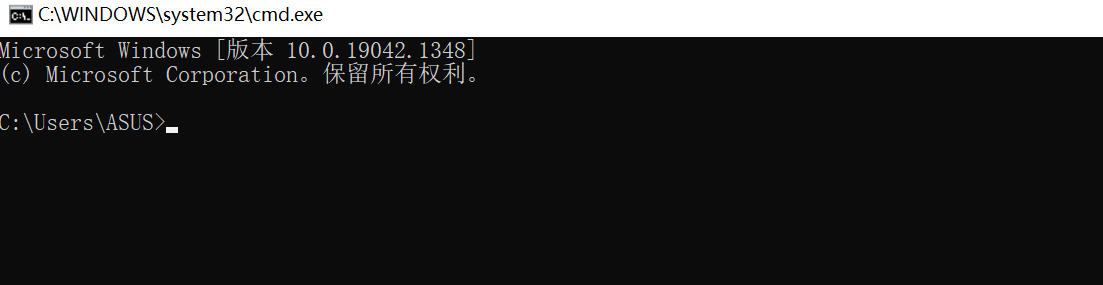
1、输入pip install requests
2、镜像安装可以了解,比较重要,(23条消息) Python 国内换源以及安装requests库(Pycharm)_YANGGEOL-CSDN博客_requests国内源
输入:pip install -i http://mirrors.aliyun.com/pypi/simple/ requests
![]()
1、pycharm安装request
1、pycharm镜像源 (23条消息) pycharm修改镜像源方法_Science Evan Blog-CSDN博客_pycharm镜像源
镜像下载安装一般都要快很多,而且比较容易成功。
2、介绍安装:
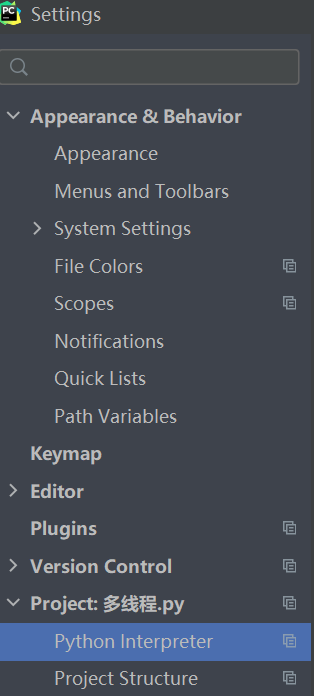
pycharm左上角的file,找到setting,再找到Project,再找到Python Interpreter,点击里面的+,搜索需要的第三方模块。
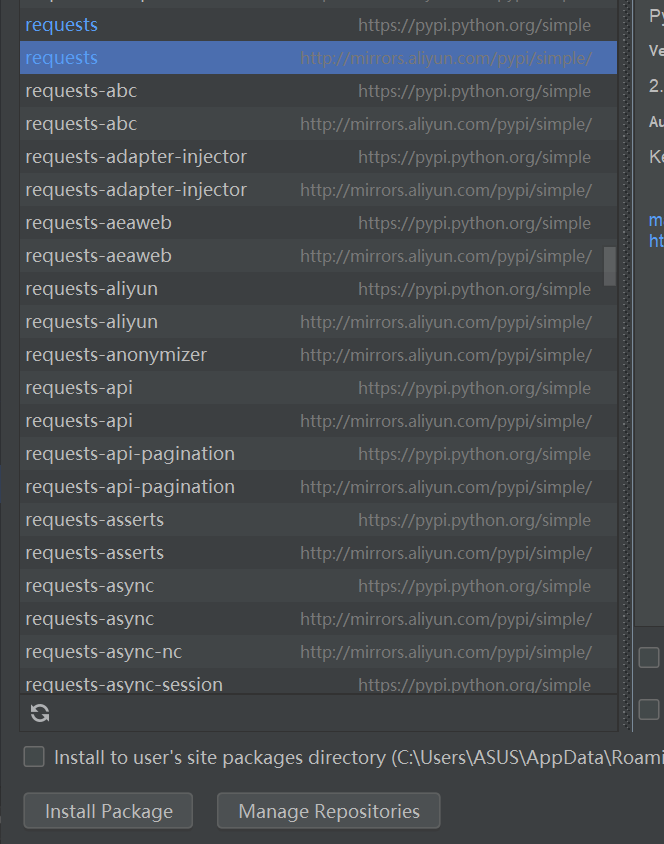
我加入了阿里云的镜像源,所以同一个模块有两种安装,另外一种是python自带的。
阿里云安装需要在options(要勾选)加入:--trusted-host mirrors.aliyun.com,自带的可以不用输入。
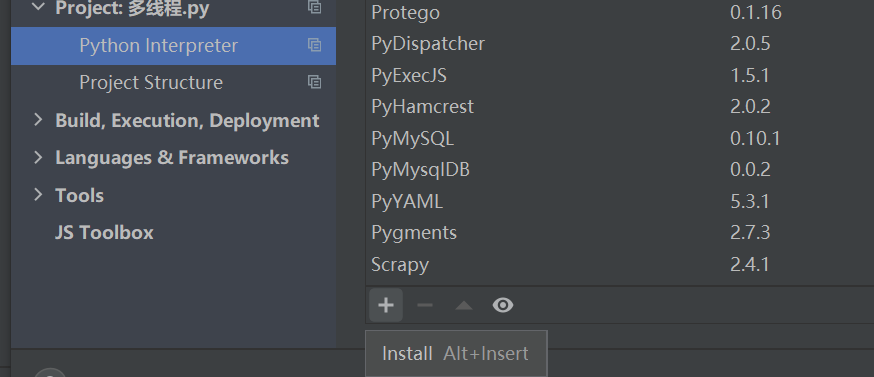
然后选择需要的包,再点击Install Package,后面会出现提示。
![]()
这是成功安装了,但是如果安装失败了重新安装。多试几次


 浙公网安备 33010602011771号
浙公网安备 33010602011771号