

安装Hadoop
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
Hadoop平台的搭建与实现
3.1 Hadoop 搭建拓扑图
利用拓扑图来简要说明分布式Hadoop的master和多个slave节点的连接关系,结果如下图所示:
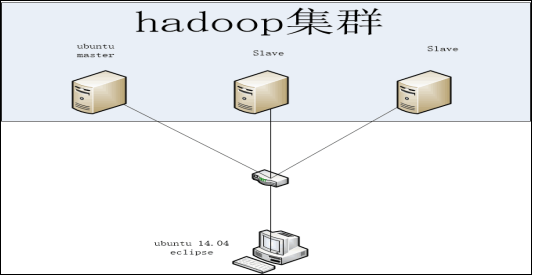
图3.1 Hadoop集群拓扑图
3.2 伪分布式 Hadoop 搭建
在单机版的Hadoop的基础上,优先配置好IP地址,效果截图所示:
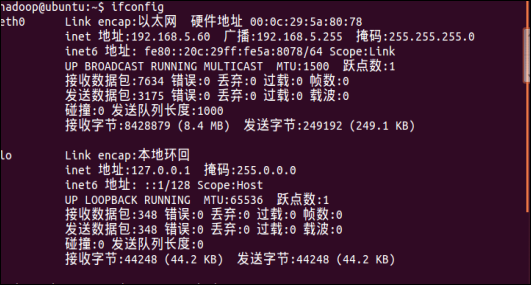
图3.2伪分布式Hadoop配置IP地址
将相关的文件更改配置后,进行首次的格式化并进行启动,效果截图所示:
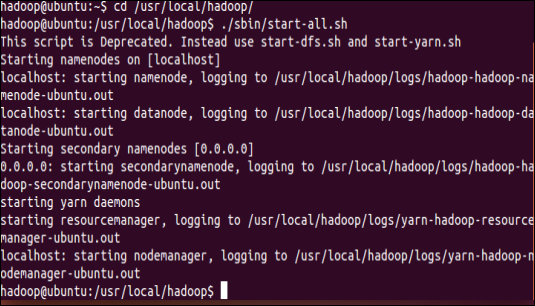
图3.3 启动Hadoop
启动后,通过jps来判断是否启动成功,若启动成功,则有DataNode,NameNode,secondaryNameNode,否则不成功,如下图为成功例子,效果截图所示:
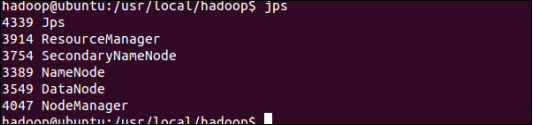
图3.4 启动成功后的各种参数
通过浏览器输入192.168.5.60(伪分布式IP地址):50070进行查看相应的文件:
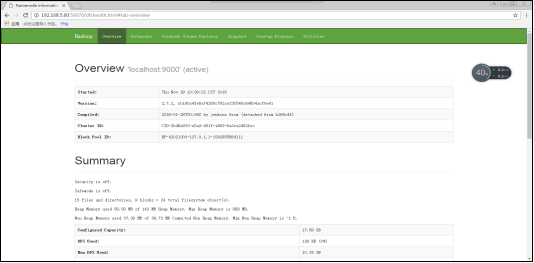
图3.5 伪分布式Hadoop文件信息
3.3 分布式 Hadoop 搭建
1.选定一台为master,另一台为slave,两台都以ubantu为操作系统,
2.分别配置IP地址为192.168.5.70,192.168.5.71
3.在master节点上配置Hadoop用户并安装ssh server,安装java环境
4.将master节点的/usr/local/hadoop 目录复制到其他节点上
5.最后在master节点上,开启Hadoop
需要在master节点上启动Hadoop,输入如下命令start-dfs.sh,
start-yarn.sh,mr-jobhisory-daemon.sh start historyserver并截图查看效果:

图3.6启动Hadoop截图效果
查看启动进程,通过jps命令可以看出各个节点启动的进程,若在slave节点上看看到nodemanager和DataNode,则是成功,否则却少任意一个进程都表示失败,如下图以成功例子效果:

图3.7slave节点下的各个进程
通过web浏览器输入192.168.5.70(分布式IP地址):50070进行查看NameNode和DataNode的状态:

图3.8 分布式Hadoop进程状态
通过web浏览器输入192.168.5.70:8088/clusterd,点击一系列的history连接,可以看到任务的运行信息
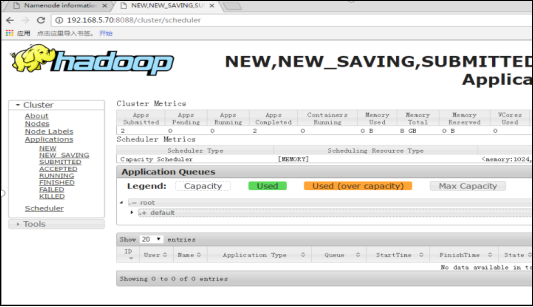
图3.9 通过web查看作业的信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号