
实验三:朴素贝叶斯算法实验
【实验目的】
理解朴素贝叶斯算法原理,掌握朴素贝叶斯算法框架。
【实验内容】
针对下表中的数据,编写python程序实现朴素贝叶斯算法(不使用sklearn包),对输入数据进行预测;
熟悉sklearn库中的朴素贝叶斯算法,使用sklearn包编写朴素贝叶斯算法程序,对输入数据进行预测;
【实验报告要求】
对照实验内容,撰写实验过程、算法及测试结果;
代码规范化:命名规则、注释;
查阅文献,讨论朴素贝叶斯算法的应用场景。
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 碍滑 | 是 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 碍滑 | 是 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
【实验代码及结果截图】
一、编写python程序实现朴素贝叶斯算法(不使用sklearn包)
#导入包
import pandas as pd
import numpy as np
#数据预处理
data=pd.read_csv("西瓜数据集3.0.txt",delimiter=',',header=None,names=['色泽','根蒂','敲声','纹理','脐部','触感','好瓜'])
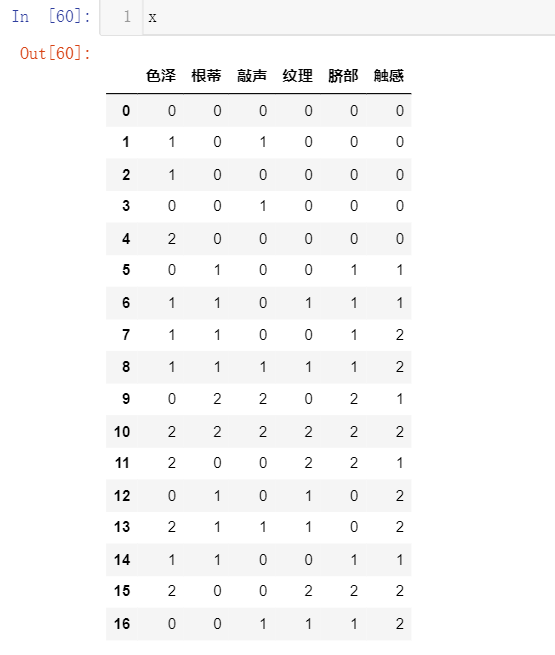
x=data.drop(['好瓜'],axis=1)
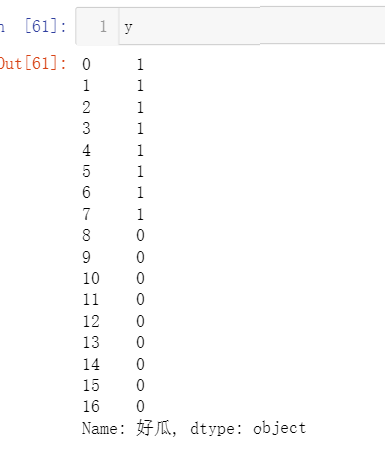
y=data['好瓜']
x

y

#朴素贝叶斯算法
def nb_fit(x,y):
classes=y.unique()
class_count=y.value_counts()
class_prior=(class_count+1)/(len(y)+2)#拉普拉斯平滑
prior=dict()
for col in x.columns:
a=x[col].value_counts()
for j in classes:
p_x_y=x[(y==j).values][col].value_counts()
for i in a.index:
if(i in p_x_y.index):
prior[(col,i,j)]=(p_x_y[i]+1)/(class_count[j]+3)#拉普拉斯平滑
else:
prior[(col,i,j)]=1/(class_count[j]+3)
return classes,class_prior,prior
#预测函数
def predict(X_test):
classes=y.unique()
class_count=y.value_counts()
class_prior=(class_count+1)/(len(y)+2)
prior=dict()
for col in x.columns:
a=x[col].value_counts()
for j in classes:
p_x_y=x[(y==j).values][col].value_counts()
for i in a.index:
if(i in p_x_y.index):````
prior[(col,i,j)]=(p_x_y[i]+1)/(class_count[j]+3)#拉普拉斯平滑
else:
prior[(col,i,j)]=1/(class_count[j]+3)
result=dict()
for c in classes:
p_y=class_prior[c]
p_x_y=1
for i in X_test.items():
p_x_y*=prior[tuple(list(i)+[c])]
result[c]=p_y*p_x_y
return result
print(nb_fit(x,y))
X_test={"色泽":"乌黑","根蒂":"蜷缩","敲声":"沉闷","纹理":"清晰","脐部":"凹陷","触感":"碍滑"}
X_test.items()
result=predict(X_test)
print('\n')
print(result)
print('测试数据预测类别为:',max(result,key=result.get))
输出实验结果

二、使用sklearn包编写朴素贝叶斯算法程序
#导入包
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB # 高斯分布
from sklearn.naive_bayes import MultinomialNB # 多项式分布
from sklearn.naive_bayes import BernoulliNB #伯努利分布
#数据预处理
data=[['0','0','0','0','0','0','1'],
['1','0','1','0','0','0','1'],
['1','0','0','0','0','0','1'],
['0','0','1','0','0','0','1'],
['2','0','0','0','0','0','1'],
['0','1','0','0','1','1','1'],
['1','1','0','1','1','1','1'],
['1','1','0','0','1','2','1'],
['1','1','1','1','1','2','0'],
['0','2','2','0','2','1','0'],
['2','2','2','2','2','2','0'],
['2','0','0','2','2','1','0'],
['0','1','0','1','0','2','0'],
['2','1','1','1','0','2','0'],
['1','1','0','0','1','1','0'],
['2','0','0','2','2','2','0'],
['0','0','1','1','1','2','0']]
"""
设置数据: 青绿:0 乌黑:1 浅白:2
蜷缩:0 稍蜷:1 硬挺:2
浊响:0 沉闷:1 清脆:2
清晰:0 稍糊:1 模糊:2
凹陷:0 稍凹:1 平坦:2
碍滑:0 软粘:1 硬滑:2
是:1 否:0
"""
labels=['色泽','根蒂','敲声','纹理','脐部','触感','好瓜']
data2=pd.DataFrame(data,columns=labels)
x=data2.drop(['好瓜'],axis=1)
y=data2['好瓜']
#划分数据集为训练集和测试集
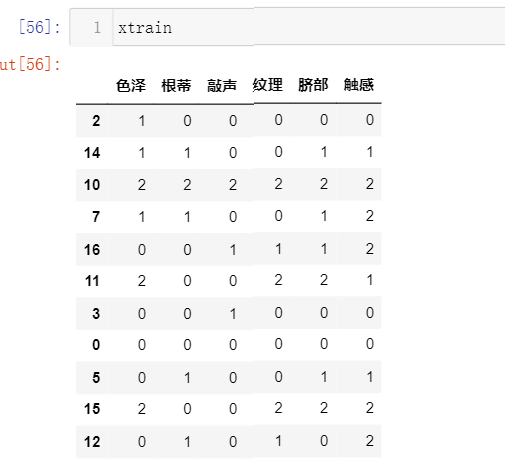
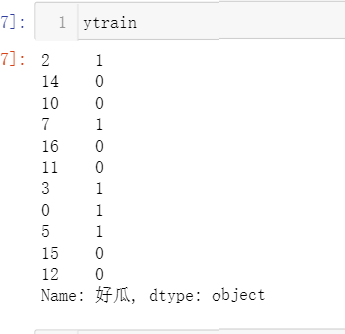
xtrain,xtest,ytrain,ytest=train_test_split(x,y,test_size=0.3,random_state=0)
#高斯朴素贝叶斯
Gc=GaussianNB()
Gc.fit(xtrain,ytrain)
result=Gc.predict(xtest)
print(result)
print("预测的准确率为:",Gc.score(xtest,ytest))
#多项式朴素贝叶斯
mc=MultinomialNB()
mc.fit(xtrain,ytrain)
result=mc.predict(xtest)
print(result)
print("预测的准确率为:",mc.score(xtest,ytest))
#伯努利朴素贝叶斯
bc=BernoulliNB()
bc.fit(xtrain,ytrain)
result=bc.predict(xtest)
print(result)
print("预测的准确率为:",bc.score(xtest,ytest))
#预测数据,以乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑样本属性为例
a=['1','1','1','1','1','2']
a=pd.DataFrame(a)
b=a.T
print("\n预测值为:")
print(b)
print("高斯分布预测结果为:", Gc.predict(b))
print("多项式分布预测结果为:",mc.predict(b))
print("伯努利分布预测结果为:",bc.predict(b))
输出实验结果

【实验总结】
朴素贝叶斯算法的应用场景:
需要一个比较容易解释,而且不同维度之间相关性较小的模型的时候;
可以高效处理高维数据,虽然结果可能不尽如意;
主要运用于文本分类,垃圾邮件分类,信用评估,钓鱼网站检测等领域。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号