
socket
昨日内容
- 面向对象复习(json序列化类)
# 对象,类,父类的概念
# 三大特性:封装,继承,多态
# 双下开头的方法(达到某个条件自动触发)
__init__:对象实例化自动触发
__str__:对象执行打印操作自动触发
__call__:对象加括号时自动触发
# 反射:利用字符串操作对象的属性或方法
hasattr
getattr
setattr
"""
json序列化非默认的python数据类型
常见操作是手动转换字符串
不常见操作重修cls指向的类
"""
-
软件开发架构(To B----To C)
B:商业化
C:个人化- 本质:b/s架构本质也是c/s架构
-
远程传输数据发展史
所有的前沿技术几乎都诞生于军事
要想实现远程传输需要满足"物理链接介质" -
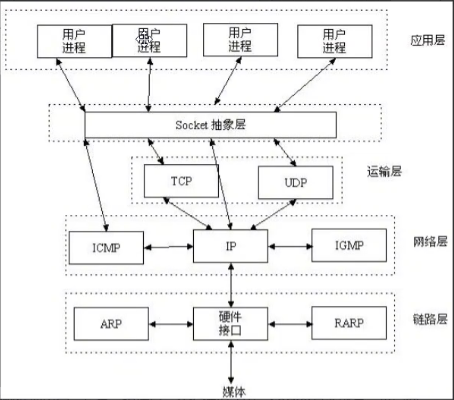
OSI七层协议
应表会传网数物 -
协议及硬件介绍
- 物理链路层
- 网卡,网线
- 数据链路层
- 电信号的分组方式,以太网协议
- mac地址,12位16进制数
mac地址只能在局域网内实现数据交互 - 交换机
- 路由器
- 局域网
- 互联网
- 上网就是顺着网线访问其他计算机上面的资源(网络只有更安全)
- 广播&单播:广播风暴
- 网络层
- IP协议:IP地址用于标识接入互联网的一台计算机
- IPV4&IPV6
- PORT协议
- 用于标识计算机上面某一个应用程序
- 动态分配端口,系统端口(0-1024),常用程序端口(1024-8000)
- IP+PORT:标识唯一一台计算机上面的某一个应用程序
- 传输层
- TCP
- UDP
- 应用层
- HTTP
- FTP
- HTTPS
- 物理链路层
-
TCP&&UDP
- TCP:可靠协议,流式协议
- 三次握手,建连接
- 四次挥手,断连接
- UDP:不可靠协议,数据报协议
- TCP:可靠协议,流式协议
概要
- socket套接字编程
- 掌握基本的客户端与服务端代码编写
- 通信循环,链接循环,代码优化
- TCP粘包现象(流式协议)
- 数据报,报头制作,struct模块,封装形式
内容
1、socket套接字
要求:写一款可以数据交互的程序
只要涉及到远程数据交互必须要操作OSI七层协议,所以有现成的模块直接实现(socket模块)
架构先启动客户端,在启动服务端
1.1、socket套接字程序编写
1.1.1、服务端(最简单)
import socket
server = socket.socket() # 默认基于网络TCP传输协议————>类似于买手机
server.bind(('0.0.0.0', 8080)) # 绑定IP&端口————>类似于插电话卡
server.listen(5) # 半连接池————>类似于开机(注:接入客户端排队等待)
sock,address = server.accept() # 监听————>三次握手的状态
data = sock.recv(1024) # 接收客户端发送的消息(1024bytes)————>类似于电话拨通后听别人讲话
print(data) # 打印出所说的话
sock.send(b'hello my big baby') # 给别人说话
sock.close() # 挂断电话
server.close() # 电话关机
在python中bytes类型可以看成二进制
->:箭头函数,确认返回的类型
函数返回多个值,默认为元祖
养成阅读源代码的习惯
1.1.2、服务端(最简单)
import socket
cilent = socket.socket() # 买手机
client.connect(('127.0.0.1', 8080)) # 拨号
client.send(b'hello') # 讲话
data = client.revc(1024) # 接收
print(data) # 打印出接收的信息
client.close() # 关机
1.2、自定义通讯循环及代码优化
上述代码问题:
- 客户端输入为空就会停住
- 服务端接收为空也会停住,注:mac&linux系统则不会
- 服务端重启频繁报端口错误
- 客户端异常关闭,服务端报错
- 异常捕获解决
- 客户端结束,服务端同时结束
- 链接循环解决
- 半连接池
- 设置可以等待的客户端数量
1.2.1、服务端
import socket
from socket import SOL_SOCKET, SO_REUSEADDR
server = socket.socket()
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('0.0.0.0', 8080))
server.listen(5)
while True:
sock, address = server.accept()
while True:
try:
data = sock.revc(1024)
if len(data) == 0:continue
print(data.decode('utf8'))
sock.send('hello')
except Excepint:
break
1.2.2、客户端
import socket
cilent = socket.socket()
cilent.connect(('127.0.0.1', 8080))
while True:
msg = input('请输入:').strip()
if len(msg) == 0:continue
cilent.send(msg.encode())
data = cilent.recv(1024)
print(data.decode('utf8')) # 注:服务端为win系统是需要gbk解码
2、粘包问题
问题:
- 当接收数据大于设定的recv时,数据传输管道内会剩余数据,下次再次recv时取出的数据还是剩余的数据问题。
- 数据量小且发送间隔短,TCP协议一次性打包发送问题
原因:
- 数据管道内的数据没有被完全取出,下次命令执行之后取出的数据还是上次命令执行结果的剩余数据
- TCP协议自带的特性,当数据量比较小且时间间隔比较短的多次数据,TCP协议会自动打包成一个数据发送
解决:
- 报头:能够标识即将到来的数据具体信息,包含数据量大小
- 报头的长度必须是固定的

- 报头的长度必须是固定的
2.1、解决粘包问题之struct模块
可以把一定量的数据编译成固定的数据大小(根据模式)

根据上述推理可以将即将发送的数据实际大小先发送过去
服务端:
import struct # 导入可以转为固定字节的模块
import socket # 导入网络传输模块
import json # 导入json序列化模块
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUDEADDR, 1) # 解决服务端端口回收慢的问题
server.bind((0.0.0.0), 8080) # 所有ip都可以访问
server.listen(5) # 半连接池数量
while True:
sock, address = server.accept() # 监听
while True:
try:
data = sock.recv(1024) # 接收
if len(data) == 0 :continue # 如果接收为0
print(data.encode()) # 打印接收并转码
file_txt = 数据
file_txt_size = len(ifle_txt)
dic = {
'file_name': '数据',
'file_size':file_txt_size
}
data_json = json.dunps(dic) # 因为不能发送字典,所以序列化为json字符串
user_data = len(data_json) # 计算序列化字典的长度
header = struct.pack('i',user_data) # 将序列化的字典转为固定的字节
sock.send(header) # 现将序列化的字典发送过去
sock.send(dic) # 在发送字典
sock.send(file_txt) # 发送真实的数据
客户端:
import json
import socket
import struct
cilent = socket.socket()
cilent.connect((127.0.0.1), 8080)
while True:
msg = input('请输入要下载的信息').strip()
if len(msg) == 0 :continue
cilent.send(msg.encode)
data = cilent.recv(4) # 因为第一次传过来的数据为4,所以设置接收四个字节
dic_size = struct.unpack('i', data)[0] # 解析出字典的大小
dic = cilent.recv(dic_size) # 接收字典
dic_json = json.loads(dic_size) # 将字典反序列化
file_dic = dic_json,get('file_size') # 取出字典内的数据
file_size = cilent.recv(file_dic) # 设置数据实际大小,并接收
上传文件代码
import json
import socket
import struct
import os
client = socket.socket() # 买手机
client.connect(('127.0.0.1', 8080)) # 拨号
while True:
data_path = r'D:\金牌班级相关资料\网络并发day01\视频'
# print(os.listdir(data_path)) # [文件名称1 文件名称2 ]
movie_name_list = os.listdir(data_path)
for i, j in enumerate(movie_name_list, 1):
print(i, j)
choice = input('请选择您想要上传的电影编号>>>:').strip()
if choice.isdigit():
choice = int(choice)
if choice in range(1, len(movie_name_list) + 1):
# 获取文件名称
movie_name = movie_name_list[choice - 1]
# 拼接文件绝对路径
movie_path = os.path.join(data_path, movie_name)
# 1.定义一个字典数据
data_dict = {
'file_name': 'XXX老师合集.mp4',
'desc': '这是非常重要的数据',
'size': os.path.getsize(movie_path),
'info': '下午挺困的,可以提神醒脑'
}
data_json = json.dumps(data_dict)
# 2.制作字典报头
data_first = struct.pack('i', len(data_json))
# 3.发送字典报头
client.send(data_first)
# 4.发送字典
client.send(data_json.encode('utf8'))
# 5.发送真实数据
with open(movie_path,'rb') as f:
for line in f:
client.send(line)
# 1.先接收固定长度为4的字典报头数据
recv_first = sock.recv(4)
# 2.解析字典报头
dict_length = struct.unpack('i', recv_first)[0]
# 3.接收字典数据
real_data = sock.recv(dict_length)
# 4.解析字典(json格式的bytes数据 loads方法会自动先解码 后反序列化)
real_dict = json.loads(real_data)
# 5.获取字典中的各项数据
data_length = real_dict.get('size')
file_name = real_dict.get("file_name")
recv_size = 0
with open(file_name,'wb') as f:
while recv_size < data_length:
data = sock.recv(1024)
recv_size += len(data)
f.write(data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号