


docker单机网络类型⭐⭐⭐⭐⭐
--network:指定docker容器使用哪个网络进行通信
docker0:docker守护进程启动时,会自动创建一个名为docker0的虚拟网桥(交换机)
veth pair:当启动一个docker容器时,docker会创建一个虚拟以太网设备对
NAT(网络地址转换):是一种将私有IP地址转换为公有IP地址,以解决IPv4地址短缺的技术
容器默认的五种单机网络类⭐⭐⭐⭐⭐
| 网络模式 | 命令示例 | 描述 | 适用场景 |
|---|---|---|---|
bridge |
--network bridge |
容器连接到 Docker 网桥,有独立 IP,通过 NAT 与外界通信(默认模式) | 通用场景,单机部署 |
host |
--network host |
容器直接使用宿主机的网络,无独立 IP,性能最佳 | 高性能需求,直接使用宿主机端口 |
none |
--network none |
不分配任何网络,只有本地回环网络lo | 离线任务,最高安全隔离 |
container |
--network container:name |
新容器与指定容器共享网络命名空间 | Sidecar 模式,紧密协作的容器组 |
| 自定义网络 | --network my-net |
自定义网络docker网络类型,需要创建网络,该自定义网络支持基于容器名称访问彼此(相当于内置了DNS) | 多容器应用,需要服务发现和网络隔离 |
五种网络模式容器网络访问能力对比表⭐⭐
| 网络类型 | 访问外网 | 访问宿主机IP | 访问docker01IP | 访问容器IP | 容器名解析 |
|---|---|---|---|---|---|
| none | ❌ | ❌ | ❌ | ❌ | ❌ |
| bridge (默认) | ✅ | ✅ | ✅ (同网段) | ✅ | ❌ (需手动配置) |
| host | ✅ | ✅ | ✅ | ✅ | ❌ |
| container | ✅ | ✅ | ✅ | ✅ | ❌ |
| 自定义网络 | ✅ | ✅ | ✅ | ✅ | ✅ (自动DNS) |
bridge-桥接模式(默认模式)⭐⭐
Docker 会为容器创建一个虚拟的、独立的网络命名空间,并将其连接到一个名为 docker0 的虚拟网桥上
容器会从 172.17.0.0/16 网段获得一个独立的 IP 地址(例如 172.17.0.2)
容器之间可以通过这个 IP 地址进行通信
容器可以通过 Docker 内置的 DNS 和 NAT 机制访问外部网络(如互联网)
默认情况下,外部网络无法直接通过 IP 地址访问容器内的服务,除非你使用 -p 参数将容器的端口映射到宿主机端口
host-主机模式⭐⭐
容器不会拥有自己独立的网络命名空间,而是直接使用宿主机的网络栈
容器直接使用宿主机的 IP 地址和端口
容器内监听的端口,会直接在宿主机上被占用
容器与宿主机之间的网络性能最好,几乎没有损耗
测试
# 查看现有的网络类型 [root@docker01 ~]# docker network ls NETWORK ID NAME DRIVER SCOPE cec4324c5481 bridge bridge local de469a193e4d host host local 155c38d45760 none null local [root@docker01 ~]# docker run -d --name c1-none --network none alpine:latest sleep 3600 [root@docker01 ~]# docker exec c1-none hostname -i # 返回值为空
[root@docker01 ~]# docker run -d --name c2-bridge --network bridge alpine:latest sleep 3600 [root@docker01 ~]# docker exec c2-bridge hostname -i # 172.17.0.2 [root@docker01 ~]# docker run -d --name c3 alpine:latest sleep 3600 [root@docker01 ~]# docker exec c3 hostname -i # 172.17.0.3
[root@docker01 ~]# docker run -d --name c4-host --network host alpine:latest sleep 3600 [root@docker01 ~]# docker exec c4-host hostname -i 10.0.0.81 172.16.1.81 172.17.0.1 [root@docker01 ~]# hostname -I 10.0.0.81 172.16.1.81 172.17.0.1
[root@docker01 ~]# docker run -d --name c5-container --network container:c3 alpine:latest sleep 3600 # 由于端口冲突导致容器启动失败 [root@docker01 ~]# docker run -d --name c5-container --network container:c3 alpine:latest sleep 3600 [root@docker01 ~]# docker exec c5-container hostname -i # 172.17.0.3
单机网络环境实现容器通信的三种方法⭐⭐⭐⭐⭐
手动host解析(不推荐)⭐
# 进入容器手动添加(重启后失效) docker exec -it c1 bash echo "172.17.0.3 c2" >> /etc/hosts
--link(已过时)⭐⭐
# 创建第一个容器 docker run -d --name c1 nginx # 创建第二个容器并link到c1 docker run -d --name c2 --link c1 nginx # 在c2中可以直接ping c1,但c1不能ping c2 docker exec c2 ping c1
自定义网络(推荐)⭐⭐⭐⭐⭐
自定义网络无法直接实现不同宿主机间的容器通信
[root@docker01 ~]# docker network create mynet [root@docker01 ~]# docker run -it --name c1 --network mynet alpine:latest [root@docker01 ~]# docker run -it --name c2 --network mynet alpine:latest 两者之间可以通过容器名互相通信 / # cat /etc/hosts 172.18.0.2 5164c9931aff # 容器id映射:容器ip地址 容器id 实现了容器名和容器ID到IP地址的自动解析,让容器间可以通过名称直接通信,无需记忆IP地址
将多个网络加入到同一个容器⭐⭐⭐⭐⭐
| 参数 | 全称 | 作用 | 示例值 | 说明 |
|---|---|---|---|---|
-d |
--driver |
指定网络驱动类型 | bridge |
桥接网络,容器间可通信,与主机网络隔离 |
--subnet |
--subnet |
定义网络子网范围 | 172.21.0.0/16 |
整个网络地址空间:172.21.0.1 - 172.21.255.254 |
--gateway |
--gateway |
指定网络网关地址 | 172.21.0.254 |
容器与外部通信的出口,必须在子网范围内 |
--ip-range |
--ip-range |
限制容器IP分配范围 | 172.21.100.0/24 |
实际分配给容器的IP:172.21.100.1 - 172.21.100.254 |
| 网络名 | - | 自定义网络名称 | linux92 |
用户定义的网络标识符,用于容器连接 |
# 创建多个网络 [root@docker01 ~]# docker network create -d bridge --gateway 172.21.0.254 --ip-range 172.21.100.0/24 --subnet 172.21.0.0/16 customize_network21 [root@docker01 ~]# docker network create -d bridge --gateway 172.22.0.254 --ip-range 172.22.100.0/24 --subnet 172.22.0.0/16 customize_network22 # 启动容器加入customize_network21/customize_network22网络 [root@docker01 ~]# docker run -d --name c1 --network customize_network21 nginx:latest [root@docker01 ~]# docker exec c1 hostname -I # 172.21.100.0 [root@docker01 ~]# docker run -d --name c2 --network customize_network22 nginx:latest [root@docker01 ~]# docker exec c2 hostname -I # 172.22.100.0 # 将c1的容器添加一个C2容器相同的网络 [root@docker01 ~]# docker exec c1 hostname -I 172.21.100.0 [root@docker01 ~]# docker network connect customize_network22 c1 [root@docker01 ~]# docker exec c1 hostname -I 172.21.100.0 172.22.100.1 # 将c1的容器去除一个C2容器相同的网络 [root@docker01 ~]# docker network disconnect customize_network22 c1 [root@docker01 ~]# docker exec c1 hostname -I 172.21.100.0
docker容器端口转发底层原理图⭐⭐⭐⭐⭐
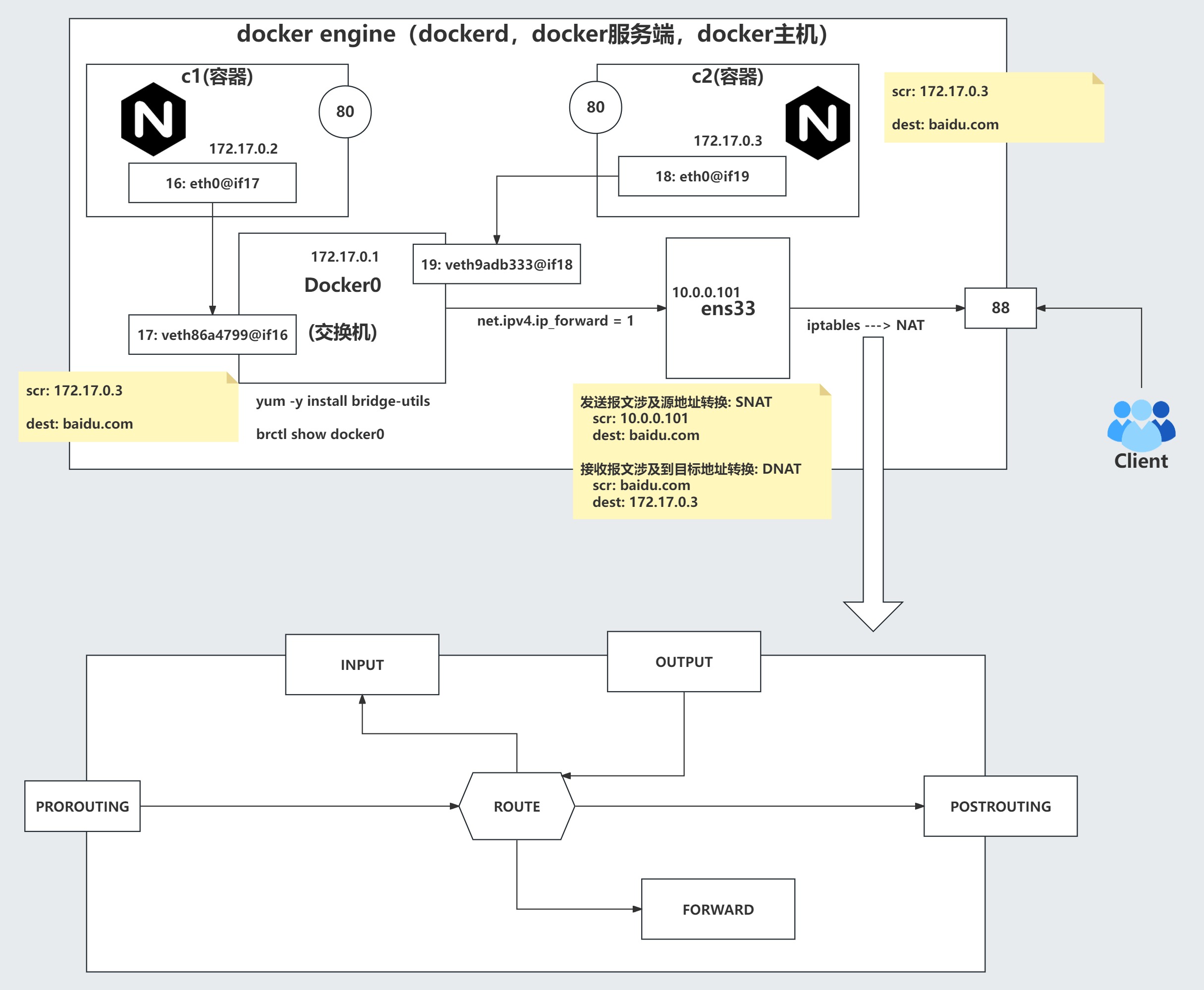
跨主机网络解决方案⭐⭐⭐⭐⭐
Macvlan实现容器跨主机网络互联⭐⭐⭐
macvlan 技术的核心就是将一块物理网卡虚拟成多块虚拟网卡,每块虚拟网卡都有自己独立的 MAC 地址,使得容器或虚拟机能够直接连接到物理网络
Macvlan实现容器跨主机网络互联
# 1.两个节点都需要加载Macvlan内核模块 [root@docker01/docker02 ~]# modprobe macvlan # 动态加载Macvlan内核模块 [root@docker01/docker02 ~]# lsmod | grep macvlan # 检查Macvlan内核模块是否加载 macvlan 19239 0 modprobe:modprobe 是 Linux 中用于动态加载和卸载内核模块的命令 lsmod:列出所有已加载的内核模块 # 2.两个节点创建同网段的自定义网络类型 [root@docker01/docker02 ~]# docker network create -d macvlan --subnet 172.29.0.0/16 \ --gateway 172.29.0.254 -o parent=eth0 mynet_macvlan -o:指定驱动选项 parent:指定父接口网卡(物理网卡) eth0:Linux系统中的物理网卡名称
告诉 Docker 使用宿主机的 eth0 物理网卡 作为 macvlan 网络的底层物理接口 # 3.两个节点基于自定义网络启动容器并手动分配IP地址 [root@docker01 ~]# docker run -d -it --name c1 --network mynet_macvlan --ip 172.29.0.81 alpine:latest [root@docker01 ~]# docker exec c1 hostname -i 172.29.0.81 [root@docker02 ~]# docker run -d -it --name c1 --network mynet_macvlan --ip 172.29.0.82 alpine:latest [root@docker02 ~]# docker exec c1 hostname -i 172.29.0.82 # 4.测试两台主机上的容器的连通信、是否可以访问外网 [root@docker01 ~]# docker exec c1 ping 172.29.0.82 -c 3 [root@docker02 ~]# docker exec c1 ping 172.29.0.81 -c 3 # 两台节点使用了该网络模式无法访问外网 [root@docker02/docker02 ~]# docker exec c1 ping www.baidu.com -c 3 # 5.解决macvlan无法访问外网问题 给容器添加一个能访问外网的网络类型 [root@docker01 ~]# docker network connect bridge c1 [root@docker01 ~]# docker exec c1 ping www.baidu.com -c 3 # 访问成功
macvlan优缺点
优点: - 1.docker原生支持,无需安装额外插件,配置起来相对简单 - 2.适合小规模docker环境,例如只有1-3台,如果服务器过多,手动分配IP地址可能会无形之间增加工作量 缺点: - 1.需要手动分配IP地址,如果让其自动分配IP地址可能会存在多个主机自动分配的IP地址冲突的情况,到时候还需要人工介入维护 - 2.相同网络的容器之间相互通信没问题,跨主机之间的容器进行通信也没问题,但容器无法与宿主机之间进行通信,也无法连接到外网; - 3.macvlan需要绑定一块物理网卡,若网卡已经被绑定,则无法创建; 温馨提示: 如果非要使用macvlan,我们需要手动分配IP地址,无法联网的问题,只需要使用"docker network connect"\
重新分配一块能够访问外网的网卡即可解决。
overlay实现容器跨主机网络互联⭐⭐⭐⭐⭐
- Consul:自动管理微服务网络并确保它们能相互发现和通信的分布式网络平台
- 让不同节点上的docker容器能够自动发现彼此,并组成一个跨主机的虚拟大二层网络
- 虚拟大二层网络:给不同物理服务器搭建虚拟交换机,让其服务器上面的容器感觉在一个局域网里工作
- 可以将consul理解为共享文件夹
- cluster-store:通过一个中央数据库地址,确保集群内所有 Docker 主机间的元数据保持一致(共享元数据:网络信息、节点信息、端口信息等)
- cluster-advertise:声明本机在集群中的“身份名片”,告知其他节点通过哪个地址和端口来访问本机的 Docker 守护进程
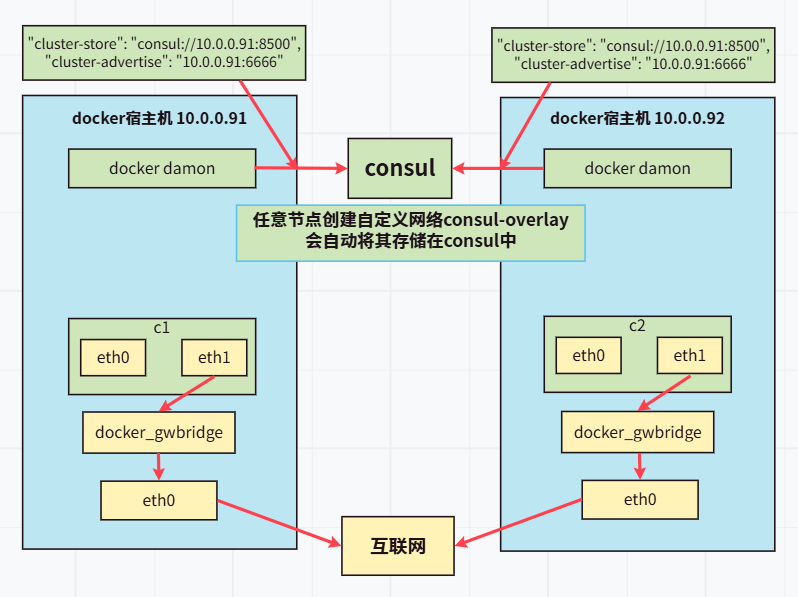
环境准备
# 分别在91节点和92节点二进制安装docker-20.10.8 [root@elk91/elk92 ~]# tar xf docker-20.10.8.tgz [root@elk91/elk92 ~]# cp /root/docker/* /usr/bin/ [root@elk91/elk92 ~]# dockerd # 拉取consul:1.15.4镜像 [root@elk91 ~]# docker load -i consul_1.15.4.tar [root@elk91 ~]# docker run -d --network host --restart always --name dev-consul \ -e CONSUL_BIND_INTERFACE=eth0 consul:1.15.4 [root@elk91 ~]# ss -lntup |grep 8500
部署
# 修改/etc/docker/daemon.json文件
[root@elk91 ~]# cat > /etc/docker/daemon.json << EOF { "cluster-store": "consul://10.0.0.91:8500", "cluster-advertise": "10.0.0.91:6666" } EOF [root@elk91 ~]# dockerd # 重新启动docker容器
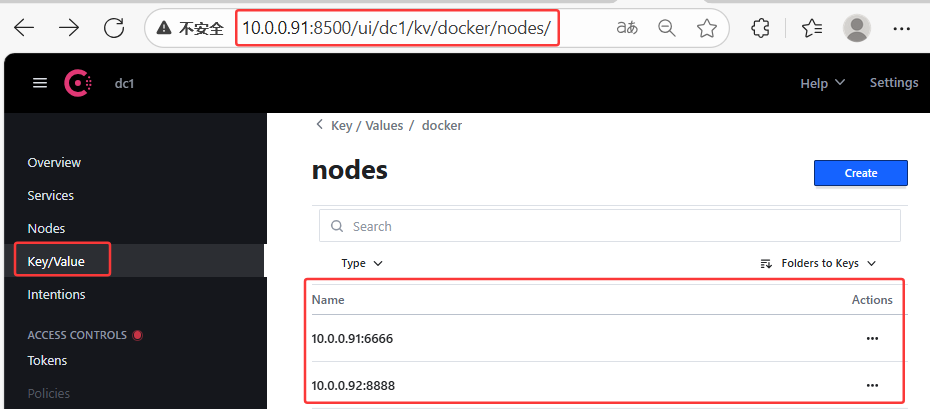
[root@elk92 ~]# cat > /etc/docker/daemon.json << EOF { "cluster-store": "consul://10.0.0.91:8500", "cluster-advertise": "10.0.0.92:8888" } EOF [root@elk92 ~]# dockerd # 重新启动docker容器 # 任意一个客户端节点创建网络,其他客户端都会通过consul来实现同步功能 docker network create -d overlay --subnet 172.30.0.0/16 --gateway 172.30.0.254 consul-overlay # 分别在91和92节点基于自定义网络启动容器 [root@elk91 ~]# docker run -d --name c1 --network consul-overlay alpine:latest sleep 3600 [root@elk92 ~]# docker run -d --name c2 --network consul-overlay alpine:latest sleep 3600 [root@elk91 ~]# docker exec c1 hostname -i # 172.30.0.1 [root@elk92 ~]# docker exec c2 hostname -i # 172.30.0.2
测试
# 测试(以下都能ping通) [root@elk91 ~]# docker exec c1 ping 172.30.0.2 [root@elk91 ~]# docker exec c1 ping 10.0.0.91 [root@elk91 ~]# docker exec c1 ping www.baidu.com
docker底层原理⭐⭐⭐⭐⭐
chroot技术(容器底层使用了chroot技术)⭐⭐⭐
chroot是一种通过改变进程的根目录来创建隔离文件系统环境的技术
ldd命令用于显示二进制可执行文件或共享库所依赖的所有动态链接库 # 1.创建工作目录 [root@docker02 ~]# mkdir -p /root/yuanxiaojiang # 2.拷贝bash程序 [root@docker02 ~]# mkdir -p /root/yuanxiaojiang/bin [root@docker02 ~]# cp /bin/bash /root/yuanxiaojiang/bin/ # 3.拷贝bash程序的依赖环境 [root@docker02 ~]# ldd /bin/bash linux-vdso.so.1 => (0x00007ffc655cf000) libtinfo.so.5 => /lib64/libtinfo.so.5 (0x00007f99feae0000) libdl.so.2 => /lib64/libdl.so.2 (0x00007f99fe8dc000) libc.so.6 => /lib64/libc.so.6 (0x00007f99fe50e000) /lib64/ld-linux-x86-64.so.2 (0x00007f99fed0a000) [root@docker02 ~]# mkdir -p /root/yuanxiaojiang/lib64 cp /lib64/libtinfo.so.5 /root/yuanxiaojiang/lib64/ cp /lib64/libdl.so.2 /root/yuanxiaojiang/lib64/ cp /lib64/libc.so.6 /root/yuanxiaojiang/lib64/ cp /lib64/ld-linux-x86-64.so.2 /root/yuanxiaojiang/lib64/ # 4.拷贝ls程序及其依赖环境 [root@docker02 ~]# which ls /usr/bin/ls [root@docker02 ~]# cp /usr/bin/ls /root/yuanxiaojiang/bin/ [root@docker02 ~]# ldd /root/yuanxiaojiang/bin/ls cp /lib64/libselinux.so.1 /root/yuanxiaojiang/lib64/ cp /lib64/libcap.so.2 /root/yuanxiaojiang/lib64/ cp /lib64/libacl.so.1 /root/yuanxiaojiang/lib64/ cp /lib64/libc.so.6 /root/yuanxiaojiang/lib64/ cp /lib64/libpcre.so.1 /root/yuanxiaojiang/lib64/ cp /lib64/libdl.so.2 /root/yuanxiaojiang/lib64/ cp /lib64/ld-linux-x86-64.so.2 /root/yuanxiaojiang/lib64/ cp /lib64/libattr.so.1 /root/yuanxiaojiang/lib64/ cp /lib64/libpthread.so.0 /root/yuanxiaojiang/lib64/ # 5.改变根目录 [root@docker02 ~]# chroot /root/yuanxiaojiang/ bash-4.2# export PATH=/bin:/usr/bin bash-4.2# ls -l # 6.启动一个新的容器 [root@docker02 ~]# cp -r /root/yuanxiaojiang /root/yuanxiaojun # 启动一个新容器(终端一) [root@docker02 ~]# chroot /root/yuanxiaojiang/ bash-4.2# echo "xixi" >/xixi.log bash-4.2# ls -l -rw-r--r-- 1 0 0 5 Oct 27 13:37 xixi.log # 启动一个新容器(终端二) [root@docker02 ~]# chroot /root/yuanxiaojun/ bash-4.2# echo "haha" >/haha.log bash-4.2# ls -l -rw-r--r-- 1 0 0 5 Oct 27 13:40 haha.log # 两个容器数据存放位置(宿主机位置) [root@docker02 ~]# ls /root/yuanxiaojiang/ bin lib lib64 xixi.log [root@docker02 ~]# ls /root/yuanxiaojun/ bin haha.log lib lib64
overlayFS(堆叠文件系统)⭐⭐⭐
overlayFS概述
- OverlayFS是一种堆叠文件系统,建立在其他文件系统(如ext4、xfs)之上,通过联合挂载技术将多个目录“合并”展示为同一级目录。
- Linux内核为Docker提供的OverlayFS驱动有两种:Overlay和Overlay2。而Overlay2是相对于Overlay的一种改进,在Inode利用率方面比Overlay更有效。
- Overlay环境需求:
- Docker版本17.06.02+
- 宿主机文件系统需要是EXT4或XFS格式
OverlayFS实现方式⭐⭐⭐
OverlayFS通过三个目录:lower目录、upper目录、以及work目录实现
lower:可以进行只读操作的目录(一般存放的是只读数据)
upper:可以进行读写操作的目录
work:
目录为工作基础目录,挂载后会自动创建一个work子目录(实际测试手动卸载后该目录并不会被删除)
该目录主要是存储一些临时存放的结果或中间数据的工作目录
OverlayFS三层结构⭐⭐⭐
# LowerDir (只读) docker镜像的只读层,也就是容器rootfs(根文件系统)的基础部分 Lowerdir的数量直接等于你构建的Docker镜像所拥有的只读层数 Lower 包括两个层: (1)系统的init 1)容器在启动以后, 默认情况下lower层是不能够修改内容的, 但是用户有需求需要修改主机名与域名\ 地址, 那么就需要添加init层中的文件(hostname, resolv.conf,hosts,mtab等文件),\ 用于解决此类问题; 2)修改的内容只对当前的容器生效, 而在docker commit提交为镜像时候,并不会将init层提交。 3)init文件存放的目录为/var/lib/docker/overlay2/<init_id>/diff 2)容器的镜像层 不可修改的数据 # Upperdir (读写) upperdir则是在lowerdir之上的一层, 为读写层。容器在启动的时候会创建, 所有对容器的修改, \ 都是在这层。比如容器启动写入的日志文件,或者是应用程序写入的临时文件。 # MergedDir (展示) merged目录是容器的挂载点,在用户视角能够看到的所有文件,都是从这层展示的。
overlayFS案例
| 组件 | 说明 |
|---|---|
mount -t overlay |
挂载一个 overlay 类型的文件系统 |
overlay |
设备名称(overlayfs 通常就用 overlay) |
-o |
开始指定挂载选项 |
lowerdir=/path/lower0:/path/lower1:/path/lower2 |
只读层:多个基础层,用冒号分隔。 优先级: lower2 → lower1 → lower0(从右到左,最右边层级最高) |
upperdir=/yuanxiaojiang/upper |
可写层:所有修改都会记录在此处 |
workdir=/yuanxiaojiang/work |
工作目录:overlayfs 内部使用,需与 upperdir 在同一文件系统 |
/yuanxiaojiang/merged/ |
挂载点:最终呈现的统一视图 |
[root@docker02 ~]# mkdir -p /yuanxiaojiang/lower{0..2} /yuanxiaojiang/{upper,work,merged} [root@docker02 ~]# mount -t overlay overlay -o \
lowerdir=/yuanxiaojiang/lower0:/yuanxiaojiang/lower1:/yuanxiaojiang/lower2,\
upperdir=/yuanxiaojiang/upper,\
workdir=/yuanxiaojiang/work \
/yuanxiaojiang/merged/ [root@docker02 ~]# df -h -t overlay Filesystem Size Used Avail Use% Mounted on overlay 27G 6.5G 21G 24% /yuanxiaojiang/merged # 尝试在lower层写入准备初始数据 [root@docker02 ~]# cp /etc/hosts /yuanxiaojiang/lower0/ [root@docker02 ~]# cp /etc/issue /yuanxiaojiang/lower1/ [root@docker02 ~]# cp /etc/resolv.conf /yuanxiaojiang/lower2/ # 尝试在upper层写入准备初始数据 [root@docker02 ~]# cp /etc/hostname /yuanxiaojiang/upper/ # 尝试在merged目录写入数据,观察数据实际写入的应该是upper层 [root@docker02 ~]# cp /etc/fstab /yuanxiaojiang/merged/ [root@docker02 ~]# ll /yuanxiaojiang/lower0 -rw-r--r-- 1 root root 435 Oct 28 11:05 hosts [root@docker02 ~]# ll /yuanxiaojiang/lower1 -rw-r--r-- 1 root root 23 Oct 28 11:10 issue [root@docker02 ~]# ll /yuanxiaojiang/lower2 -rw-r--r-- 1 root root 72 Oct 28 11:10 resolv.conf [root@docker02 ~]# ll /yuanxiaojiang/upper/ -rw-r--r-- 1 root root 483 Oct 28 11:12 fstab -rw-r--r-- 1 root root 9 Oct 28 11:11 hostname [root@docker02 ~]# ll /yuanxiaojiang/merged/ -rw-r--r-- 1 root root 483 Oct 28 11:12 fstab -rw-r--r-- 1 root root 9 Oct 28 11:11 hostname -rw-r--r-- 1 root root 435 Oct 28 11:05 hosts -rw-r--r-- 1 root root 23 Oct 28 11:10 issue -rw-r--r-- 1 root root 72 Oct 28 11:10 resolv.conf # 重新挂载(不挂载upperdir层) [root@docker02 ~]# umount /yuanxiaojiang/merged [root@docker02 ~]# mount -t overlay overlay \ -o lowerdir=/yuanxiaojiang/lower0:/yuanxiaojiang/lower1:/yuanxiaojiang/lower2,\ workdir=/yuanxiaojiang/work \ /yuanxiaojiang/merged/ [root@docker02 ~]# ll /yuanxiaojiang/merged/ -rw-r--r-- 1 root root 435 Oct 28 11:05 hosts -rw-r--r-- 1 root root 23 Oct 28 11:10 issue -rw-r--r-- 1 root root 72 Oct 28 11:10 resolv.conf [root@docker02 ~]# cp /etc/os-release /yuanxiaojiang/merged/(写入数据失败) cp: cannot create regular file ‘/yuanxiaojiang/merged/os-release’: Read-only file systm
测试docker底层使用了overlayFS
[root@docker02 ~]# docker run -d --name c1 nginx:latest [root@docker02 ~]# df -h -t overlay Filesystem Size Used Avail Use% Mounted on overlay 27G 6.6G 21G 25% /var/lib/docker/overlay2/27ff...e9d4/merged [root@docker02 ~]# docker inspect -f "{{.GraphDriver.Data.MergedDir}}" c1 /var/lib/docker/overlay2/27ff...e9d4/merged [root@docker02 ~]# docker inspect -f "{{.GraphDriver.Data.UpperDir}}" c1 /var/lib/docker/overlay2/27ff...e9d4/diff [root@docker02 ~]# docker exec c1 touch /haha.log # 在容器中创建一个文件 [root@docker02 ~]# ls /var/lib/docker/overlay2/27ff...e9d4/merged haha.log [root@docker02 ~]# ls /var/lib/docker/overlay2/27ff...e9d4/diff/ # 数据被写入到读写层 haha.log
macvlan和overlay的区别⭐⭐⭐
macvlan和overlay的区别: 相同点: 都可以实现网络的互相通信 不同点: - 1.macvlan是内核支持模块,无需安装第三方插件,只需加载模块即可,overlay需要安装第三方插件consul; - 2.macvlan需要手动分配IP地址,而overlay网络无需手动分配IP地址; - 3.macvlan默认无法访问外网,需要手动配置桥接网络,而overlay默认可以访问外网; docker网络不足的总结: - 1.docker在网络互联上存在缺陷,比如overlay网络各节点实现IP地址通信,\ 当容器挂掉时,会自动为该容器分配IP地址。若容器重启后,IP地址可能发生变化; - 2.若配置文件写的都是IP地址,则容器重启后IP地址发生变化,可能导致服务不可用;
namespace-名称空间⭐⭐⭐
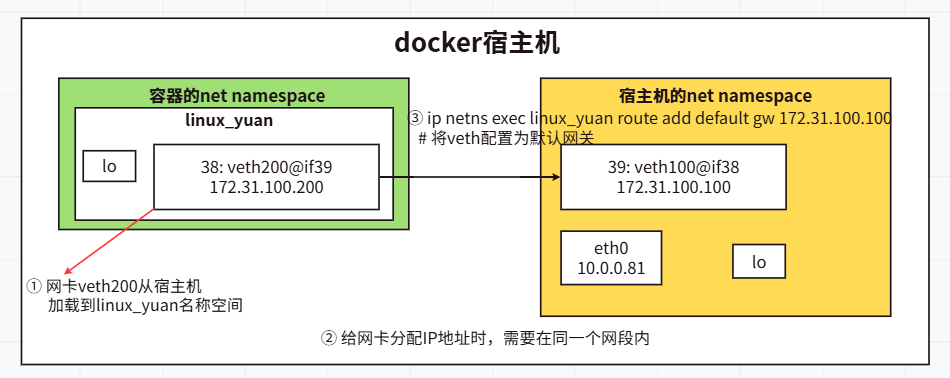
namespace介绍⭐⭐⭐
docker底层用到了namespace做资源隔离
Linux Namespace是Linux系统提供的一种 资源隔离机制
可实现系统资源隔离的列表如下:
IPC: 用于隔离进程间通信
MNT: 用于隔离文件系统和提供硬盘挂载点
NET: 用于隔离网络
PID: 用于隔离进程ID
User: 用于隔离用户和用户组
UTS: 用于隔离HostName(主机名)和DomianName(域名)
NET网络名称空间测试案例⭐
# 1.创建一个名称为"linux_yuan"的网络名称空间 [root@docker01 ~]# ip netns add linux_yuan [root@docker01 ~]# ll /var/run/netns/ -r--r--r-- 1 root root 0 Oct 30 13:36 linux_yuan # 2.启动"linux_yuan"的网络名称空间的lo网卡 [root@docker01 ~]# ip netns exec linux_yuan ping 127.0.0.1 # 未启动网卡,不饿能ping通 [root@docker01 ~]# ip netns exec linux_yuan ifconfig lo up # 启动lo网卡 [root@docker01 ~]# ip netns exec linux_yuan ping 127.0.0.1 # 可以ping通 # 3.宿主机创建网络设备对 [root@docker01 ~]# ip link add veth100 type veth peer name veth200 [root@docker01 ~]# ip address # 会多出来2块网卡,即veth100,veth200 # 4.将"veth200"设备关联到咱们自定义的"linux_yuan"网络名称空间 [root@docker01 ~]# ip link set veth200 netns linux_yuan [root@docker01 ~]# ip address # 发现宿主机的veth200网卡不见了 # 5.将"veth200"设备配置IP地址 [root@docker01 ~]# ip netns exec linux_yuan ip address [root@docker01 ~]# ip netns exec linux_yuan ifconfig veth200 172.31.100.200/24 up [root@docker01 ~]# ip netns exec linux_yuan ip address # 6.宿主机veth100也配置IP地址 [root@docker01 ~]# ifconfig veth100 172.31.100.100/24 up [root@docker01 ~]# ifconfig veth100 [root@docker01 ~]# ping 173.31.100.200 # 能ping通 # 7.测试 [root@docker01 ~]# ip netns exec linux_yuan ping 172.31.100.100 # 能ping通 [root@docker01 ~]# ip netns exec linux_yuan ping 10.0.0.81 # 未添加网关,无法ping通 [root@docker01 ~]# ip netns exec linux_yuan route add default gw 172.31.100.100 # 将veth100配置为默认网关 [root@docker01 ~]# ip netns exec linux_yuan ping 10.0.0.81 # 添加网关后,可能ping通 # ping外网无法ping通 [root@docker01 ~]# ip netns exec linux_yuan www.baidu.com # 不能ping通 [root@docker01 ~]# ip netns exec linux_yuan 10.0.0.82 # 不能ping通 [root@docker01 ~]# ip netns exec linux_yuan 110.242.68.4 # 不能ping通 # 8.测试完成后,删除名称空间 ll /var/run/netns/ # 可以先查看挂载点文件是否存在 ip netns del linux_yuan # 删除名称空间 ip link del veth100 # 删除宿主机的虚拟网卡
测试docker使用net namespace⭐
[root@docker01 ~]# docker run -d --name c1 alpine:latest sleep 3600 [root@docker01 ~]# ip address 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast 4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue 40: vethfe02329@if39: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 [root@docker01 ~]# docker exec c1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN 39: eth0@if40: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 [root@docker01 ~]# docker run -d --name c2 alpine:latest sleep 3600 [root@docker01 ~]# ip address 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast 4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue 40: vethfe02329@if39: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 42: veth7083571@if41: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 [root@docker01 ~]# docker exec c2 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN 41: eth0@if42: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500
两个容器共享网络名称空间案例⭐
# 1. 启动两个容器 [root@docker01 ~]# docker run -d --name c1 alpine:latest sleep 3600 [root@docker01 ~]# docker run -d --name c2 --network container:c1 alpine:latest sleep 3600 # 2.查看c1和c2的进程ID对应的网络名称空间 [root@docker01 ~]# docker inspect -f "{{.State.Pid}}" c1 # 12239 [root@docker01 ~]# docker inspect -f "{{.State.Pid}}" c2 # 12609 [root@docker01 ~]# ll /proc/12239/ns lrwxrwxrwx 1 root root 0 Oct 30 16:40 net -> net:[4026532503] [root@docker01 ~]# ll /proc/12609/ns/ lrwxrwxrwx 1 root root 0 Oct 30 16:46 net -> net:[4026532503] # 两个进程(12239 和 12609)共享同一个网络命名空间(net:[4026532503]) [root@docker01 ~]# docker exec c1 ifconfig [root@docker01 ~]# docker exec c2 ifconfig # 两个容器显示的网络信息相同 # c1和c2对应的net的存储地址是相同的,因此c1和c2能够看到相同的网络信息
cgoups⭐⭐⭐
cgoups介绍
Linux CGroup全称Linux Control Group,是Linux内核的一个功能
用于限制、控制、分离进程组所使用的物理资源
cgroups在Linux系统中能够控制的资源列表
cpu: 主要限制进程的cpu使用率
cpuacct: 可以统计cgroups中的进程的cpu使用报告
cpuset: 可以为cgroups中的进程分配单独的cpu节点或者内存节点
memory: 可以限制进程的memory使用量
blkio: 可以限制进程的块设备io
devices: 可以控制进程能够访问某些设备
net_cls: 可以标记cgroups中进程的网络数据包,然后可以使用tc模块对数据包进行控制
net_prio: 这个子系统用来设计网络流量的优先级
freezer: 可以挂起或者恢复cgroups中的进程
ns: 可以使不同cgroups下面的进程使用不同的namespace
hugetlb: 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统
CPU资源限制案例

# 1.挂载cgroup文件系统,以便通过文件接口管理控制组 [root@docker01 ~]# mount -t cgroup cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu # 2.进入到CPU的挂载路径,并创建自定义的资源限制组 [root@docker01 ~]# cd /sys/fs/cgroup/cpu && mkdir linux_yuan && ls linux_yuan cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us 系统会默认在linux_yuan目录下创建文件 # 3.使用stree进行压力测试 [root@docker01 ~]# yum install -y stress [root@docker01 ~]# stree -c 4 -v -t 20m # 4.限制CPU的使用率在30% [root@docker01 ~]# cd /sys/fs/cgroup/cpu/linux_yuan/ && echo 30000 > cpu.cfs_quota_us # 5.将任务的ID加入自定义限制组 [root@docker01 ~]# ps -ef |grep stress |grep -v grep root 13607 2223 0 17:14 pts/0 00:00:00 stress -c 4 -v -t 20m root 13608 13607 17 17:14 pts/0 00:02:03 stress -c 4 -v -t 20m root 13609 13607 17 17:14 pts/0 00:02:01 stress -c 4 -v -t 20m root 13610 13607 17 17:14 pts/0 00:02:06 stress -c 4 -v -t 20m root 13611 13607 17 17:14 pts/0 00:02:07 stress -c 4 -v -t 20m [root@docker01 ~]# cd /sys/fs/cgroup/cpu/linux_yuan/ [root@docker01 linux_yuan]# echo 13608 >> tasks [root@docker01 linux_yuan]# echo 13609 >> tasks [root@docker01 linux_yuan]# echo 13610 >> tasks [root@docker01 linux_yuan]# echo 13611 >> tasks # 6.删除自定义限制组 [root@docker01 ~]# rmdir /sys/fs/cgroup/cpu/linux_yuan/
docker使用cgroup实现资源限制⭐⭐⭐⭐⭐
# 1.部署测试容器 [root@docker02 ~]# docker load -i /root/stress-image.tar [root@docker02 ~]# docker run -d --cpu-quota 30000 --memory 200m --name c1 polinux/stress:1.0.4 sleep 3600 [root@docker02 ~]# docker run -d --name c2 polinux/stress:1.0.4 sleep 3600 # 2.压测CPU和内存 [root@docker02 ~]# docker exec c1 stress -c 4 -v -t 20m [root@docker02 ~]# docker stats c1 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS cfddae493235 c1 30.03% 160KiB / 200MiB 0.08% 656B / 0B 0B / 0B 6 [root@docker02 ~]# docker exec c2 stress -c 4 -v -t 20m [root@docker02 ~]# docker stats c2 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 31cd95ff5382 c2 69.60% 160KiB / 972.3MiB 0.02% 656B / 0B 0B / 0B 6
对已运行的容器实现资源限制⭐⭐⭐⭐⭐
# 1.容器实例准备 [root@docker02 ~]# docker run -d --name c1 polinux/stress:1.0.4 sleep 3600 # 2.压力测试 [root@docker02 ~]# docker exec c1 stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10m --vm-keep --cpu 8: 生成8个CPU密集型工作进程 --io 4: 生成4个I/O密集型工作进程 --vm 2: 生成2个内存工作进程 --vm-bytes 128M: 每个内存工作进程分配128MB内存 --timeout 10m: 测试持续10分钟 --vm-keep: 关键参数 - 保持内存分配,不重复释放和重新分配 # 3.限制前的状态 [root@docker02 ~]# docker stats c1 --no-stream CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS dff33327d3b5 c1 99.51% 256.2MiB / 972.3MiB 26.35% 656B / 0B 0B / 54.3kB 16 # 4.限制容器的资源使用 [root@docker02 ~]# docker container update --cpu-quota 20000 --memory 300m --memory-swap 300m c1 # 5.限制之后的状态 [root@docker02 ~]# docker stats c1 --no-stream CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS dff33327d3b5 c1 19.80% 225.2MiB / 300MiB 75.07% 656B / 0B 4.59GB / 2.36GB 16

 浙公网安备 33010602011771号
浙公网安备 33010602011771号