


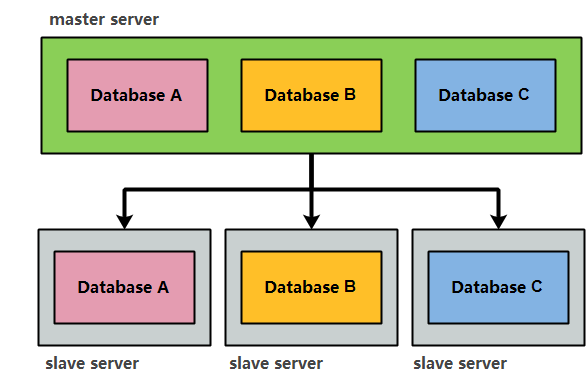
数据库主从基础
数据库服务主从复制概述
复制是将主数据库的DDL和DML操作语句通过二进制日志传到复制服务器上;
然后在从库上(复制服务器)对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步;
MySQL支持一台主库同时向多台从库进行复制,从库同时也可以作为其他服务器的主库,实现链状的复制;
MySQL复制的优点主要包含以下3个方面:
如果主库出现问题,可以快速切换到从库提供服务;
可以在从库上执行查询操作,降低主库的访问压力;
可以在从库上执行备份操作,以避免备份期间影响主库的服务;
由于MySQL实现的是异步的复制,所以主从库之间存在一定的差距,在从库上进行的查询操作需要考虑到这些数据的差异,
一般只有更新不频繁的数据或者对实时性要求不高的数据可以通过从库查询,实时性要求高的数据仍然需要从主数据库获得;
数据库服务主从复制原理⭐⭐⭐⭐⭐
复制原理涉及到的三个线程⭐⭐⭐⭐⭐
| 所在位置 | 线程名称 | 作用说明 |
|---|---|---|
| 主库涉及线程 | binlog dump thread | 用于将主库binlog日志信息进行传输投递的线程 · 可以实现与从库的信息交互 · 可以监控二进制日志的变化 · 可以进行二进制日志的投递 |
| 从库涉及线程 | slave IO thread | · 可以用于连接主数据库服务 · 可以实现与主库线程的交互 · 可以接收和存储二进制日志(接收的二进制日志会存储在中继日志中) |
| slave SQL thread | · 可以解析执行中继日志信息(回放) |


复制原理涉及到的四个文件⭐⭐⭐⭐⭐
| 所在位置 | 文件信息 | 解释说明 |
|---|---|---|
| 主库涉及文件 |
binlog |
可以利用二进制日志信息变化,实现主从数据库的异步方式同步 |
| 从库涉及文件 | relaylog | 可以利用中继日志进行临时存储或接收主库投递的二进制日志信息,日志信息会定期自动清理 |
| master.info | 可以存储主库相关信息(主库地址 端口 用户 密码 二进制位置点-已经获取的 )(和IO线程相关) | |
| relay-log.info | 可以存储SQL线程回放过的日志信息(与SQL线程相关) |
数据库5.7版本后,master/relay-log已经不以文件方式保存在数据目录中,而是以表格形式直接存储在数据库内部
mysql> show variables like '%info%'; master_info_repository TABLE relay_log_info_repository TABLE mysql> use mysql; mysql> show tables; slave_master_info slave_relay_log_info -- 可以获取slave_master_info表中的信息,就是change master to配置指定的相关信息; -- 可以获取 slave_relay_log_info表中的信息,就是SQL线程已经回放过的日志信息
复制原理⭐⭐⭐⭐⭐

在从库上执行change master to命令,将主库连接信息和binlog位置信息写入master.info文件或 slave_master_info表中; 在从库上执行start slave命令,用于启动从库的IO和SQL线程功能; 从库IO线程主要用于读取主库连接信息,实现与主库建立连接,从而使主库派生出binlog dump线程(自动监控binlog); 从库IO线程根据change master to命令所定义的数据位置点,获取最新的binlog日志信息 mysql主库在事务提交时会把数据变更为事件Events记录在二进制日志文件binlog中; mysql主库上的sync_binlog参数控制binlog日志刷新到磁盘; binlog dump线程会截取binlog日志并投递其日志给从库IO线程,此时主库并不关心投递日志信息的结果; 此时从库IO线程接收binlog投递信息(缓存),随之会立即更新master.info文件 或 slave_master_info数据表信息; 从库缓存的binlog日志数据信息会被写入到relaylog中继日志中; 主库推送二进制日志文件binlog中的事件到从库的中继日志relay log,之后从库根据中继日志relay log重做数据变更操作, 从库SQL线程将会读取relaylog.info文件或者slave_relay_log_info数据表中信息,获取上次数据回放同步位置点; 随之继续向后回放同步数据,一旦回放同步数据完成后,再次更新relay.info或slave_relay_log_info数据表信息; 在从库中回放过的relaylog日志信息,会被relay_log_purge线程定期删除处理这些日志; 通过逻辑复制以此来达到主库和从库的数据一致;
MySQL通过3个线程来完成主从库间的数据复制:其中binlog dump线程跑在主库上,I/O线程和SQL线程跑在从库上; 当在从库上启动复制(START SLAVE)时,首先创建I/O线程连接主库,主库随后创建binlog dump线程读取数据库事件; 并发送给I/O线程,I/O线程获取到事件数据后更新到从库的中继日志relay log中去,之后从库上的SQL线程读取中继日志relay log, 根据中继日志中的更新的数据库事件并应用; 简述:在两台以上节点进行复制,通过binlog日志实现同步关系,并且采用异步方式进行数据同步;
数据库服务主从复制实践⭐⭐⭐⭐⭐
复制环境搭建过程⭐⭐⭐⭐⭐
- 步骤01:需要准备两台及以上数据库实例
# 数据库3306节点作物主库、数据库3307节点作为从库 [root@db01 ~]# mysqld_safe --defaults-file=/data/3307/my.cnf & [root@db01 ~]# mysqld_safe --defaults-file=/etc/my.cnf & # 也可以使用systemctel启动 [root@db01 ~]# ss -lntup |grep mysql tcp LISTEN 0 70 [::]:33060 [::]:* users:(("mysqld",pid=1386,fd=32)) tcp LISTEN 0 128 [::]:3306 [::]:* users:(("mysqld",pid=1386,fd=34)) tcp LISTEN 0 128 [::]:3307 [::]:* users:(("mysqld",pid=2708,fd=32)) [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql3307.sock
- 步骤02:主数据库二进制日志功能开启
-- 核实主库binlog日志功能是否开启 mysql> show variables like '%log_bin%'; | log_bin | ON | | log_bin_basename | /data/3306/binlog/mysql-bin | | log_bin_index | /data/3306/binlog/mysql-bin.index | | sql_log_bin | ON |
- 步骤03:核实主从复制主机的信息情况
server_id:在数据库主从复制中用来唯一标识每一台MySQL服务器实例
MySQL实例中都必须都有独一无二的server_id
有了 server_id,MySQL 服务器就能识别并跳过由自己产生的事件,从而防止自己复制循环
server_id 让每台MySQL服务器有了“防丢回旋镖”的能力——它能认出自己扔出去的飞镖并躲开,从而避免被反复击中
server_uuid:MySQL服务器与生俱来的全球唯一“身份证号”,它保证了在任何地方都不会重复,\
是实现 GTID 复制、精准追踪全球事务来源的基石。
-- 确认多个复制节点的服务标识不同(server id/server_uuid) mysql> select @@server_id; -- 6:端口号为3306主机 mysql> select @@server_id; -- 7:端口号为3307主机 mysql> select @@server_uuid; -- 主库:19dd4a42-6d59-11f0-9bb7-000c29e3dc70 MySQL> select @@server_uuid; -- 从库:7f04be27-914a-11f0-92d9-000c29e3dc70 -- 确认多个复制节点的时间信息同步 [root@db01 ~]# date -- Mon Sep 15 11:04:04 CST 2025 [root@db01 ~]# date -- Mon Sep 15 11:04:12 CST 2025 -- 确认多个复制节点的版本信息一致 [root@db01 ~]# mysql -V mysql Ver 8.0.26 for Linux on x86_64 (MySQL Community Server - GPL) -- 部分实际应用场景中可以支持不一致,但是复制源端可以是低版本,复制目标端可以是高版本,反之不行;
- 步骤04:主库创建主从数据同步用户
REPLICATION SLAVE: 允许从库服务器使用此账户连接主库并请求二进制日志进行数据同步 REPLICATION CLIENT: 允许用户查看主库或从库的复制状态信息,但不参与实际的数据同步过程 -- 在主库上创建复制同步数据用户 mysql> create user repl@'10.0.0.%' identified with mysql_native_password by '123456'; mysql> grant replication slave on *.* to repl@'10.0.0.%';
- 步骤05:进行从库部分数据信息的同步(由于进行了克隆操作,该步骤可省略)
# 可以将主库上的部分数据在从库上先进行同步 [root@db01 ~]# mysqldump -uroot -A -S /tmp/mysqlsock --master-data=2 --single-transaction >/tmp/full.sql -- 在3306主库上进行数据的全备(模拟企业环境的历史数据全备) [root@db01 ~]# mysql -S /tmp/mysql3307.sock mysql> source /tmp/full.sql; -- 在3307从库上进行数据的恢复(模拟企业环境的历史数据恢复) -- 将原有主机的数据先备份,然后从库中进行恢复一部分数据,随后再进行数据信息同步追加 -- 可以利用同步方式有很多:mysqldump xtrabackup clone_plugin
- 步骤06:配置主从节点数据复制的信息
# 设置从库连接主库信息,定义从库连接主库同步位置点自动复制 mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_USER='repl', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000021', MASTER_LOG_POS=959, MASTER_CONNECT_RETRY=10; -- 从库和主库连接中断后,每隔多少秒尝试重新连接一次 -- 以上配置主从同步信息在从库进行执行;
- 步骤07:激活主从节点数据复制的线程
-- 利用相应线程实现主从数据库的数据同步复制 mysql> start slave; -- 在从库上激活数据复制同步功能 -- 若此时数据同步失败可以重新开启同步功能(两个步骤都要使用) mysql> stop slave; -- 暂停复制 mysql> reset slave all; -- 彻底删除所有复制配置和信息 (master.info文件、relay-log.info、relylog、内存中的复制配置) -- 在从库上重置数据复制同步功能,重新配置change master to信息,然后重新激活同步复制功能; -- 从库上查看数据同步状态情况,看到上面的两个Yes信息,就表示主从数据同步功能设置成功了 mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for source to send event Master_Host: 10.0.0.51 Master_User: repl Master_Port: 3306 Connect_Retry: 10 Master_Log_File: binlog.000021 Read_Master_Log_Pos: 959 Relay_Log_File: db01-relay-bin.000002 Relay_Log_Pos: 324 Relay_Master_Log_File: binlog.000021 Slave_IO_Running: Yes Slave_SQL_Running: Yes
主从复制数据过程监控⭐⭐⭐⭐⭐
- 方法01:利用数据库自带命令实现监控
# 在从库上可以使用SQL语句,进行主从复制数据情况的监控: mysql> show slave status\G -- 在主库上也可以实现数据复制监控,但是一般情况下更关注的是从库;
| 内容分类 | 输出内容 | 解释说明 |
|---|---|---|
| 主库的复制信息 | Master_Host: 10.0.0.51 | 表示连接主库地址信息 |
| 利于IO线程工作方面 | Master_User: repl | 表示连接主库用户信息 |
| Master_Port: 3306 | 表示连接主库端口信息 | |
| Connect_Retry: 10 | 表示连接主库重试间隔 | |
| Master_Log_File: binlog.000021 | 表示主从同步日志信息 | |
| Read_Master_Log_Pos: 959 | 表示主从同步位置信息 (从库IO线程读取到的主库binlog的当前位置) |
|
| 从库的回放信息 | Relay_Log_File: db01-relay-bin.000002 | 表示中继日志回放文件信息 |
| 利于SQL线程工作方面 | Relay_Log_Pos: 324 | 表示中继日志回放位置信息 (限一个事件的起始点) |
| Relay_Master_Log_File: binlog.000021 | 表示SQL线程正在执行的中继日志内容所对应的主库binlog文件 | |
| Exec_Master_Log_Pos: 959 | 表示SQL线程已执行完的binlog中的位置 | |
| 从库的线程信息 | Slave_IO_Running: Yes | 表示从库同步数据时-IO线程状态 |
| 利于判断同步线程情况 | Slave_SQL_Running: Yes | 表示从库同步数据时-SQL线程状态 |
| Last_IO_Errno: 0 | 表示从库IO线程异常错误代码 | |
| Last_IO_Error: | 表示从库IO线程异常错误原因 | |
| Last_SQL_Errno: 0 | 表示从库SQL线程异常错误代码 | |
| Last_SQL_Error: | 表示从库SQL线程异常错误原因 | |
| 过滤复制的相关信息 | Replicate_Do_DB: | |
| Replicate_Ignore_DB: | ||
| Replicate_Do_Table: | ||
| Replicate_Ignore_Table: | ||
| Replicate_Wild_Do_Table: | ||
| Replicate_Wild_Ignore_Table: | ||
| 主从复制的延时情况 | Seconds_Behind_Master: 0 | 表示主从之间延时秒数信息 |
| 延时从库的状态情况 | SQL_Delay: 0 | |
| SQL_Remaining_Delay: NULL | 表示最近事件延时剩余时间 | |
| 主从GTID复制状态情况 | Retrieved_Gtid_Set: | 从库已从主库接收到的事务集合 |
| Executed_Gtid_Set: | 从库已在本地执行完成的事务集合 |
- 方法02:利用 Percona Toolkit 专业工具实现监控
pt-table-checksum:用于检测主库和从库之间的数据内容是否完全一致,并pinpoint出具体不一致的表和范围
pt-table-sync:用于修复pt-table-checksum发现的主从数据差异(保障数据一致性的修复工具)
pt-heartbeat:持续监控主从复制延迟,提供比mysql自身更精确、更真实的延迟数据
- 方法03:利用第三方开源平台实现监控
Orchestrator(orch)
Orchestrator 是一个智能的、带Web界面的MySQL高可用管理工具,它不仅能监控复制状态,更能在主库故障时自动完成故障切换,保障业务连续性
复制故障分析 ⭐⭐⭐⭐⭐
当出现略长时间主从数据库数据不同步时,就可以理解为出现了复数据制故障
从库线程异常分析-IO⭐⭐⭐⭐⭐
出现IO线程异常情况
Slave_IO_Running: Yes # 常见异常状态:connecting、no # 根据错误编码和错误信息说明,可以判断产生IO线程异常的原因; Last_IO_Errno: 0 Last_IO_Error: # connecting可能导致异常原因 - 连接地址、端口、用户、密码信息不对可能会导致连接异常; - 防火墙安全策略阻止连接建立、网络通讯配置异常影响连接建立; - 到达数据库服务连接数上限,造成主从连接产生异常;
- 指定的MASTER_LOG_POS点超过你需要设置的点 排查思路:使用主从复制专用用户进行手工连接测试,核实主从复制用户是否可以远程连接登录数据库服务 # no可能导致异常情况 - 主库的二进制日志信息被清理 - 主从配置标识信息冲突(server_id)
connecting异常模拟
-- 在从库上模拟密码错误情况 mysql> stop slave; mysql> reset slave all; CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_USER='repl', MASTER_PASSWORD='123456789', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000021', MASTER_LOG_POS=959, MASTER_CONNECT_RETRY=10; mysql> start slave; -- 在从库上模拟会话上限情况 mysql> select @@max_connections; -- 在主库上进行连接上限配置(修改其值为4) [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock -- 进行多次操作,占有其所有连接 mysql> stop slave; mysql> reset slave all; CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_USER='repl', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000021', MASTER_LOG_POS=959, MASTER_CONNECT_RETRY=10;
mysql> start slave; mysql> show slave status\G Slave_IO_Running: Connecting Last_IO_Errno: 1040 Last_IO_Error: error connecting to master 'repl@10.0.0.51:3306' - retry-time: 10 retries: 3 message: Too many connections
no异常模拟
在进行异常情况模拟前,核实确认好主从同步状态是否正常(一定需要进行的操作)
-- 在主库上模拟日志信息误删情况 mysql> reset master; -- 在主库上清理日志文件信息 mysql> show slave status\G -- 从库上进行查看 Slave_IO_Running: No -- 恢复环境 mysql> stop slave; mysql> reset slave all; CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_USER='repl', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=710, MASTER_CONNECT_RETRY=10; mysql> start slave; -- 模拟主从配置标识信息冲突(server_id) mysql> stop slave; mysql> set global server_id=6; mysql> start slave; mysql> show slave status\G Slave_IO_Running: No
从库线程异常分析-SQL⭐⭐⭐⭐⭐
出现SQL线程异常情况
Slave_SQL_Running: Yes # 常见异常状态:no # 根据错误编码和错误信息说明,判断产生SQL线程异常的原因 Last_SQL_Errno: 0 Last_SQL_Error: # 可能导致异常原因:(从库数据或设置异常导致) - 创建的对象已存在,涉及到的对象可能有库、表、用户、索引...; - 插入(insert)的操作对象有异常、修改(update alter)的操作对象有异常、删除(delete drop)的操作对象有异常; - 由于据库设置的约束信息,与执行的SQL语句产生冲突问题; - 在数据库不同版本之间进行数据同步时,可能出现配置冲突问题(比如:5.6可以识别时间为0字段,5.7不能识别时间为0字段) # 可能造成异常情况: - 在进行主从配置时,指定的位置点出现错误(change master to); - 在进行主从配置前,从库被写入相应的数据信息了,与主库同步数据产生冲突(误连接从库进行操作了); - 在从库工作繁忙状态时,从库宕机了,业务恢复后可能出现异步同步数据错乱(主库操作创建表操作没同步,同步了插入表操作); - 在进行主从切换时(假设进行的是手工切换),没有正确操作锁定源主库和binlog日志信息; 导致切换前主库数据没有完全同步,切换后从库数据(原主库)比主库数据(原从库)信息更全; - 在应用数据库双主结构时,没有正确使用(经常导致相互同步数据,主键或唯一键冲突) 若企业创建必须使用双主架构,实现双写机制,可以使用全局序列机制,实现主键或唯一键的统一分配;
线程异常情况模拟
在进行异常情况模拟前,核实确认好主从同步状态是否正常;
# 模拟主库数据已存在
mysql> create database test; -- 在从库上创建数据信息(模拟误连接从库执行操作情况) mysql> create database test; -- 在主库上创建数据信息(实现主库创建数据与从库一致) -- 主库上模拟后续的操作 mysql> begin; mysql> use test; mysql> create table t1(id int); mysql> insert into t1 value(1),(2),(3); mysql> commit; mysql> create database test10; mysql> show slave status\G *************************** 1. row *************************** Slave_IO_Running: Yes Slave_SQL_Running: No Last_SQL_Errno: 1007 Last_SQL_Error: Error 'Can't create database 'test'; database exists' on query. Default database: 'test'. Query: 'create database test' Retrieved_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:4-15 -- 从库已经接收到的主库事件 Executed_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:1-11, -- 从库已经执行的主库事件 7f04be27-914a-11f0-92d9-000c29e3dc70:1-7 -- 从库上自己操作的事件
将Slave_SQL_Running恢复为Yes
从库的SQL线程只是在“重放”主库二进制日志中的事件,它并不关心自己当前数据库的实际状态(这个数据库存不存在)
# 没有开启GTID模式 -- 使用SQL_SLAVE_SKIP_COUNTER(指定sql线程接下来遇到的N个事件直接跳过,不执行) mysql> STOP SLAVE; -- 停止从库复制 mysql> SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; -- 设置需要跳过几个事件 mysql> START SLAVE; -- 重新启动从库复制 mysql> SHOW SLAVE STATUS\G -- 检查状态,确认是否恢复 # 开启GTID模式(在 GTID 模式下,SQL_SLAVE_SKIP_COUNTER 是无效的) mysql> STOP SLAVE; -- 停止从库复制 mysql> SET GTID_NEXT='19dd4a42-6d59-11f0-9bb7-000c29e3dc70:5'; -- 查找需要跳过的GTID,执行空事务,模拟该事务已执行 mysql> BEGIN; COMMIT; mysql> SET GTID_NEXT='AUTOMATIC'; mysql> START SLAVE; -- 重新启动从库复制 mysql> SHOW SLAVE STATUS\G -- 检查状态,确认是否恢复
复制延时问题分析
- 延时问题出现的原因
主从复制的延时问题主要描述的是:(在出现主从数据同步延时问题时,从库的线程还是能够正常工作运行的) 主从复制的延时问题造成的影响是: 对于读写分离架构是依赖于主从同步数据环境的,主库作为写节点,从库作为读节点,延时严重会影响从库的读操作体验; 对于高可用架构也是依赖于主从同步数据环境的,主库作为主节点,从库作为备节点,延时严重会影响主备的切换一致性; 主从复制的延时问题出现的原因是: 1、外部因素导致的延时问题: - 网络通讯不稳定,有带宽阻塞等情况,造成主从数据传输同步延时; - 主从硬件差异大,从库磁盘性能较低,内存和CPU资源都不够充足; - 主从配置区别大,从库配置没有优化,导致并发处理能力低于主库;(参考了解) 2、主库因素导致的延时问题: - 主要涉及Dump thread工作效率缓慢,可能是由于主库并发压力比较大; - 主要涉及Dump thread工作效率缓慢,可能是由于从库数量比较多导致; - 主要涉及Dump thread工作效率缓慢,主要由于线程本身串型工作方式;(利用组提交缓解此类问题-5.6开始 group commit) 主库本身可以并发多个事务运行,默认情况下主从同步Dump thread只有一个,只能采用串型方式传输事务日志信息; 3、从库因素导致的延时问题: - 从库产生延迟受SQL线程影响较大,由于线程本身串型工作方式导致; 利用不同数据库并行执行事务操作,但是一个库有多张表情况,产生大量并发事务操作,依旧是串型的(5.6开始 多SQL线程回放) 利用logical_clock机制进行并发回放,由于组提交事务是没有冲突的,从库并行执行也不会产生冲突(5.7开始 多SQL线程回放) 4、其他因素导致的延时问题: - 由于数据库大事务产生的数据同步延时问题;(尽量切割事务) - 由于数据库锁冲突机制的数据同步延时问题;(资源被锁无法同步/隔离级别配置RR-锁冲突严重,可调整RC降低延时 索引主从一致) - 由于数据库过度追求安全配置也会导致同步延时问题(从库关闭双一参数);
- 获取logical_clock机制的组提交标记信息:
(事务级别并发)
sequence_number:这是事务的唯一提交序号,单调递增,标志着事务在主库上的提交顺序 last_committed:这是事务的依赖序号,标识了当前事务依赖于哪个序号之前的所有事务,相同值的事务意味没有冲突 [root@db01 ~]# mysqlbinlog /data/3306/binlog/mysql-bin.000005 #250916 8:35:28 server id 6 end_log_pos 1110 last_committed=4 sequence_number=5 #250916 8:39:20 server id 6 end_log_pos 1352 last_committed=5 sequence_number=6 ...省略部分信息... -- 可以看到日志文件中,有大量last_commited信息,用于标记相同组提交的同步事件信息,并发执行是以事务为单位 -- 可以看到日志文件中,会利用sequence_number信息,表示一个事务内执行操作顺序
- 主从复制的延时问题监控方式
mysql> show slave status\G *************************** 1. row *************************** Seconds_Behind_Master: 0 -- 表示主从之间延时秒数时间信息 Relay_Master_Log_File: mysql-bin.000005 Exec_Master_Log_Pos: 156 -- 在从库上利用 show slave status\G 获取binlog日志同步执行位置点 -- 在主库上利用 show master status 获取binlog日志同步生成位置点,与从库进行对比,即可判定是否出现主从延迟问题;
数据库服务主从复制扩展⭐⭐⭐⭐⭐
延时从库⭐⭐⭐⭐⭐
# 概念介绍 表示人为主动将一个从库进行配置,使从库可以按照指定的时间延时后,在进行数据同步 # 功能说明 通常对于数据库服务中的数据信息产生损坏,可能有两方面因素造成: 物理损坏:主机故障、磁盘异常、数据文件损坏...,可以利用传统主从复制方式,规避此类问题,利用从库替代主库工作任务; 逻辑损坏:误删除操作(drop truncate delete),可以利用备份数据+binlog日志方式,可以实现数据信息的修复,但是代价比较高; 利用延时从库同步功能,主要是对逻辑原因造成的数据损坏进行弥补修复,从而避免全备数据恢复业务产生的代价较高问题; 当出现逻辑损坏操作时,可以利用延时从库的延时同步特性,将异常操作不做同步,将从库未做破坏的数据信息恢复到主库中; # 延时从库的应用思路分析: 延时的根本效果是主库执行操作完成后,会经过指定的时间后,从库在执行主库曾经执行的操作; 延时同步效果是在SQL线程上进行控制实现的,并非在IO线程上进行控制实现的; SQL线程的延时控制机制,主要是需要识别同步操作任务的时间戳信息,根据时间戳和延时时间信息结合,判断相关任务是否同步执行; 基于主从同步原理,IO线程同步主库操作事件是持续同步的,只是SQL线程在进行事件信息回放时,进行了延时控制;
从库环境配置
# 将33008设置为从库 [root@db01 3308]# mysqld_safe --defaults-file=/data/3308/my.cnf & [root@db01 3308]# mysql -S /tmp/mysql3308.sock mysql> select @@server_id; -- 调整从库的server_id信息,避免和主库产生冲突 -- 如果主库开启了GTID功能,则从库需要开启 # 将主库上的部分数据再从库上先进行同步(在3306主库上进行数据的全备) [root@db01 ~]# mysqldump -uroot -proot -A -S /tmp/mysql.sock --master-data=2 \ --single-transaction >/tmp/full.sql [root@db01 3308]# mysql -S /tmp/mysql3308.sock mysql> source /tmp/full.sql -- 在3308从库上进行数据的恢复 # 实现主从同步(同时实现了增量数据的同步) # 通过备份文件获取同步位置点信息 [root@db01 ~]# grep -o "MASTER_LOG_FILE='[^']*', MASTER_LOG_POS=[0-9]*" /tmp/full.sql | tail -n 1 MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=1224 # 从库执行change master to操作 mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_USER='repl', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000009', MASTER_LOG_POS=203, MASTER_CONNECT_RETRY=10; # 在从库上激活数据复制同步功能 mysql> start slave; # 延时从库功能设置 mysql> stop slave; mysql> change master to master_delay=300; # 设置延迟时间为300秒后同步数据 mysql> start slave; mysql> show slave status\G SQL_Delay: 300 # 从库故意延迟时间 SQL_Remaining_Delay: NULL # 从库还需多长时间延迟
企业应用延时从库事件模拟
| 操作语句 | 解释说明 |
|---|---|
| 插入语句 insert | 假设在09:59时,持续有插入操作行为,需要进行同步 |
| 删除语句 drop | 假设在10:00时,产生了删除操作行为,需要避免同步 |
企业异常情况处理过程说明: 1)网站页面需要挂维护页面进行说明 2)从库服务立即关闭SQL线程,停止事件任务回放(千万不要停止IO线程) 3)将从库出现故障前的数据信息,即由于延时配置没有执行的操作回放,到出现故障点的时刻停止回放;
- 延时从库应用效果环境模拟
mysql> create database test; mysql> use test; mysql> create table t1(id int); mysql> insert into t1 values(1),(2),(3); mysql> drop table t1; mysql> create table t2(id int); mysql> insert into t1 values(4),(5); -- 突然发现自己的表误删了 ERROR 1146 (42S02): Table 'test.t1' doesn't exist mysql> show master status; +------------------+----------+--------------+------------------+-------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------------------------------+ | mysql-bin.000009 | 1425 | | | 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:1-48 | +------------------+----------+--------------+------------------+-------------------------------------------+ mysql> show slave status\G Master_Log_File: mysql-bin.000009 Read_Master_Log_Pos: 1425 Exec_Master_Log_Pos: 377 SQL_Delay: 300 SQL_Remaining_Delay: 150 Retrieved_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:44-48 Executed_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:1-43
- 数据信息修复方式一:手工截取日志信息进行回放数据,恢复业务
-- 停止从库SQL线程回放日志事件 mysql > stop slave sql_thread; -- 停止从库SQL线程,终止持续同步操作,使从库不再回放同步数据; mysql> show slave status\G Master_Log_File: mysql-bin.000009 Read_Master_Log_Pos: 1425 Relay_Log_File: db01-relay-bin.000002 Relay_Log_Pos: 324 -- 根据relaylog起点信息以及异常操作位置点信息,截取日志内容信息 mysql> show relaylog events in 'db01-relay-bin.000002'; +-----------------------+------+------------+-----------+-------------+----------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +-----------------------+------+------------+-----------+-------------+----------------------------------------------------------------------+ | db01-relay-bin.000002 | 949 | Xid | 6 | 1033 | COMMIT /* xid=43 */ | | db01-relay-bin.000002 | 980 | Gtid | 6 | 1110 | SET @@SESSION.GTID_NEXT= '19dd4a42-6d59-11f0-9bb7-000c29e3dc70:47' | | db01-relay-bin.000002 | 1057 | Query | 6 | 1237 | use `test`; DROP TABLE `t1` /* generated by server */ /* xid=44 */ | +-----------------------+------+------------+-----------+-------------+----------------------------------------------------------------------+ -- 在从库服务器上完成日志信息的截取操作 [root@db01 data]# mysqlbinlog --start-position=324 --stop-position=980 /data/3308/data/db01-relay-bin.000002 >/tmp/relay.sql -- 在从库中恢复截取日志信息数据 mysql> set sql_log_bin=0; mysql> source /tmp/relay.sql; mysql> set sql_log_bin=1; mysql> show slave status\G Retrieved_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:44-48 Executed_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:1-46
-- 从库跳过drop事务 mysql> SET GTID_NEXT='19dd4a42-6d59-11f0-9bb7-000c29e3dc70:47'; -- 查找需要跳过的GTID,执行空事务,模拟该事务已执行 mysql> BEGIN; COMMIT; mysql> SET GTID_NEXT='AUTOMATIC'; mysql> START SLAVE; -- 重新启动从库复制 mysql> show slave status\G Retrieved_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:44-48 Executed_Gtid_Set: 19dd4a42-6d59-11f0-9bb7-000c29e3dc70:1-47
此时进行start slave sql_thread,则sql线程接着进行回放 如果想要进行主库的修复,则将从库设置为主库,再进行增量恢复,然后去修复主库
- 数据信息修复方式二:持续延时从库数据回放同步过程,但同步过程停止在异常操作前
# 操作过程01:停止从库SQL线程回放日志事件 mysql > stop slave sql_thread; mysql > show slave status\G *************************** 1. row *************************** Master_Log_File: mysql-bin.000009 Read_Master_Log_Pos: 1425 Relay_Log_File: db01-relay-bin.000002 Relay_Log_Pos: 324 Slave_IO_Running: Yes Slave_SQL_Running: No SQL_Delay: 300 SQL_Remaining_Delay: NULL -- 核实从库SQL线程状态是否为NO,以及获取读取的relay_log日志文件信息 # 操作过程02:回放日志事件在异常操作位置点前(位置点信息以Pos列显示的为准,并且是提前一个事务位置点) mysql> show relaylog events in 'db01-relay-bin.000002'; -- Pos:当前事件在中继日志文件中的开始位置 -- Server_id:产生这个原始事件的数据库服务器的ID -- End_log_pos:该事件在主库的二进制日志中的结束位置 +-----------------------+-----+------------+-----------+-------------+--------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +-----------------------+-----+------------+-----------+-------------+--------------------------------------------------------------------+ | db01-relay-bin.000002 | 949 | Xid | 6 | 1033 | COMMIT /* xid=43 */ | | db01-relay-bin.000002 | 980 | Gtid | 6 | 1110 | SET @@SESSION.GTID_NEXT= '19dd4a42-6d59-11f0-9bb7-000c29e3dc70:47' | | db01-relay-bin.000002 | 1057| Query | 6 | 1237 | use `test`; DROP TABLE `t1` /* generated by server */ /* xid=44 */ | +-----------------------+-----+------------+-----------+-------------+--------------------------------------------------------------------+ mysql > change master to master_delay=0; -- 在从库重启进行日志回放操作前,关闭从库延迟回放的功能
start slave until -- 在从库上启动复制,但只执行到指定的日志位置或GTID条件后便自动停止 start slave until relay_log_file="log_name", relay_log_pos=log_pos; start slave until sql_before_gtids="gtid号";(如果开启了GTID功能,也可以按照GTID号进行回放) mysql > start slave until relay_log_file='db01-relay-bin.000002', relay_log_pos=980; mysql> show slave status\G *************************** 1. row *************************** Slave_IO_Running: Yes Slave_SQL_Running: No Until_Log_File: db01-relay-bin.000002 Until_Log_Pos: 980 Relay_Log_Pos: 324 # 操作过程03:核实异常数据信息是否恢复,并重构主从关系(或者跳过删除操作,让其接着自动回放) -- 核实数据库以及数据表信息已恢复,并且原有主从关系已经彻底奔溃,需要进行主从关系重构 mysql> stop slave; mysql> reset slave all; -- 从库身份解除 -- 参考官方资料:https://dev.mysql.com/doc/refman/8.0/en/start-replica.html
过滤复制
如果主库上有多个数据库业务,希望将不同的数据库业务同步到不同的从库上,实现数据库业务分离,就可以使用数据库过滤复制功能
一般数据库中,临时和永久的内容都配置
将10.0.0.51:3306主库和10.0.0.51:3308从库恢复主从并正常运行
# 查看从库复制过滤限制参数信息
mysql> show slave status\G
*************************** 1. row ***************************
Replicate_Do_DB: school
Replicate_Ignore_DB: school
-- 表示库级别的过滤操作,白名单设置表示回放库级别操作,黑名单设置表示忽略库级别操作
Replicate_Do_Table: school.student
Replicate_Ignore_Table: school.student
-- 表示表级别的过滤操作,白名单设置表示回放表级别操作,黑名单设置表示忽略表级别操作
Replicate_Wild_Do_Table: school.stu*
Replicate_Wild_Ignore_Table: school.stu*
-- 表示模糊级别的过滤操作,主要是可以针对多表信息,配置白名单或黑名单;
[root@db01 ~]# cat /data/3308/my.cnf [mysql] socket=/tmp/mysql3308.sock [mysqld] user=mysql port=3308 basedir=/usr/local/mysql datadir=/data/3308/data socket=/tmp/mysql3308.sock server_id=8 gtid_mode=on enforce_gtid_consistency=1 log_slave_updates=on replicate_do_db=school replicate_do_db=world mysql> stop slave sql_thread; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> change replication filter replicate_do_db=(world,school); Query OK, 0 rows affected (0.00 sec) mysql> start slave sql_thread; Query OK, 0 rows affected, 1 warning (0.01 sec) mysql> show slave status\G Replicate_Do_DB: world,school Replicate_Ignore_DB:
半同步复制
概念介绍说明:
在MySQL5.5版本之前,数据库的复制是异步操作,主库和从库的数据之间存在一定的延迟,这样就存在数据存储不一致的隐患;
假设当主库上写入一个事务并提交成功, 而从库尚未得到主库推送的binlog日志时,主库宕机了;
例如主库可能因磁盘损坏、内存故障等造成主库上该事务binlog丢失,此时从库就可能损失这个事务,从而造成主从不一致;
为了解决这个问题,数据库服务引入了半同步复制机制。
当采用异步方式同步数据,由于从库异常宕机情况出现,造成主从数据不一致情况出现,还会有以下影响情况:
会造成从库可能创建语句没有执行,后续的插入语句也必然失败,形成SQL线程运行故障;
由于主从数据信息不一致,在架构设计上在读取从库数据信息时,就会读取数据信息异常;
说明:利用半同步复制机制,主要是用于解决主从数据复制不一致的问题,即解决主从数据一致性问题,也可以避免SQL线程故障;
实现工作机制:
在MySQL5.5之前的异步复制时,主库执行完commit提交操作后,在主库写入binlog日志后即可成功返回客户端,无需等待binlog日志传送给从库;
半同步复制时,为了保证主库上的每个binlog事务能够被可靠的复制到从库上,主库在每次事务成功提交时,并不及时反馈给前端用户;
而是等待其中一个从库也接收到binlog事务并成功写入中继日志后,主库才返回commit操作成功给客户端。
半同步复制保证了事务成功提交后,至少有两份日志记录,一份在主库的binlog日志上,\
另一份在至少一个从库的中继日志relaylog上从而更进一步保证了数据的完整性。
简单说明:半同步复制技术应用,主要是阻塞主库事务提交的执行过程,从而实现数据最终一致性目的;
半同步复制技术与传统主从复制技术不同之处:
在主库提交操作时候会受到阻塞,等待从库IO线程返回ack确认信号后,才能使主库提交操作成功;
从库IO线程接收到binlog日志信息,当日志信息写入到磁盘上的relaylog文件时,会给主库返回ack信号;
在主库上会利用ack_receiver线程接收返回的ack信号;
当主库上的ack_receiver线程接收到ack信号信息时,会产生事件触发机制,告诉主库事务提交操作成功了;
如果在接收ack信号时,等待信号时间超过了预设值的超时时间,半同步复制会切换为原始的异步复制方式;
预设的等待超时时间的数值,由参数rpl_semi_sync_master_timeout设置的毫秒数决定;
功能应用实践:
- 主从数据库安装半同步功能插件
# 确保10.0.0.51:3306主库和10.0.0.51:3308从库恢复主从并正常运行 # 主库安装半同步插件(3306) mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; -- 主库利用插件控制ack_receiver线程接收ack确认信息,并且会控制commit阻塞,实现半同步复制功能 mysql> show plugins; +----------------------+--------+-------------+--------------------+---------+ | Name | Status | Type | Library | License | +----------------------+--------+-------------+--------------------+---------+ | rpl_semi_sync_master | ACTIVE | REPLICATION | semisync_master.so | GPL | +----------------------+--------+-------------+--------------------+---------+ # 从库安装半同步插件(3308) mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; -- 从库利用插件控制IO线程发送ack确认信息; mysql> show plugins; +---------------------+--------+-------------+-------------------+---------+ | Name | Status | Type | Library | License | +---------------------+--------+-------------+-------------------+---------+ | rpl_semi_sync_slave | ACTIVE | REPLICATION | semisync_slave.so | GPL | +---------------------+--------+-------------+-------------------+---------+
说明:一般在高可用数据库架构环境中,可以在高可用的两台主机上均安装好主库插件和从库插件;
- 主从数据库启动半同步插件功能
mysql> set global rpl_semi_sync_master_enabled=1; -- 主库启动半同步功能 mysql> set global rpl_semi_sync_slave_enabled=1; -- 从库启动半同步功能 -- 从库上重启IO线程 mysql> stop slave IO_THREAD; mysql> stop slave IO_THREAD;
主从数据库半同步功能永久配置:
# 在主库配置文件中编写以下参数 rpl_semi_sync_master_enabled=on -- 主库半同步功能启停设置,on为激活设置 rpl_semi_sync_master_timeout=1000 -- 主库接收从库确认信息的超时时间设置(单位毫秒) rpl_semi_sync_master_trace_level=32 -- 主库半同步插件的调试日志级别(32一般为信息级别) rpl_semi_sync_master_wait_for_slave_count=1 -- 必须收到至少一个从库的确认,半同步机制才会继续 rpl_semi_sync_master_wait_no_slave=on -- 当没有从库时,是否允许主库继续处理事务 rpl_semi_sync_master_wait_point=after_sync -- 控制主库在哪个时间点等待从库确认 -- after_sync:先将事务写入binlog,同步给从库等待ACK,最后再提交事(落盘)务并返回客户端 (如果没接收到ACK确认信号,则不会在主库中落盘) binlog_group_commit_sync_delay=1 -- 通过引入一个微小的延迟窗口,将多个并发事务的二进制日志落盘操作合并执行,\ 以大幅减少磁盘I/O次数,从而提升高并发下的数据库吞吐性能。 binlog_group_commit_sync_no_delay_count=1000 -- 最大等待事务数,达到这个数量则立即提交 -- 实现事务组提交方式,将多个事务合并成组推送到从库上,避免dump线程采用串型方式提交事务,造成主从同步延时; rpl_semi_sync_slave_enabled=on -- 从库半同步功能启停设置,on为激活设置 rpl_semi_sync_slave_trace_level=32
GTID复制
GTID(global transaction id)是对于一个已提交事务的全局唯一编号
复制原理机制
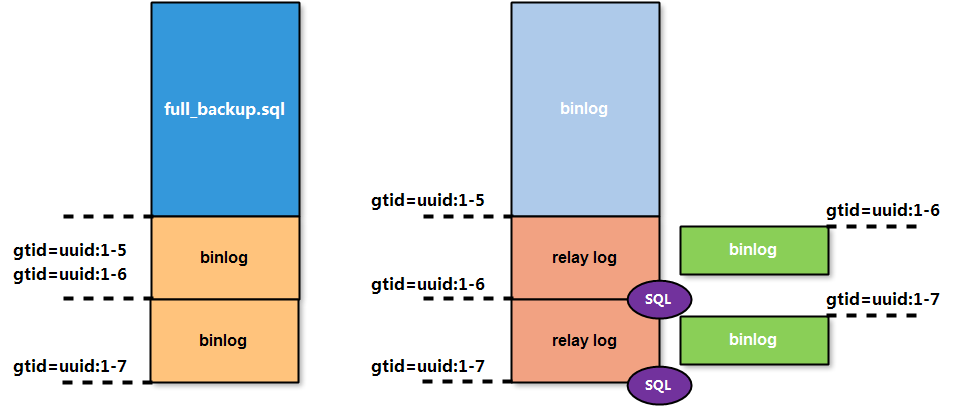
- master节点在更新数据的时候,会在事务前产生GTID信息,一同记录到binlog日志中;
- slave节点的io线程将主库推送的binlog写入到本地relay log中;
- 然后SQL线程从relay log中读取GTID,设置gtid_next的值为该gtid,然后对比slave端的binlog是否有记录;
- 如果有记录的话,说明该GTID的事务已经运行,slave会忽略;
- 如果没有记录的话,slave就会执行该GTID对应的事务,并记录到binlog中。
功能应用实践
- 环境准备
| 主机角色 | 主机名称 | 地址信息 |
|---|---|---|
| 主库服务器 | db-01 | 10.0.0.51 |
| 从库服务器 | db-02 | 10.0.0.52 |
对原有的数据库服务环境清理
# 在所有的主从节点上均进行清理操作 [root@db01 ~]# pkill mysqld [root@db01 ~]# rm -rf /data/3306/data/* [root@db01 ~]# rm -rf /data/3306/binlog/* [root@db01 ~]# chown -R mysql.mysql /data/3306/*
主从配置文件
[root@db01 ~]# cat /data/3306/my.cnf
[mysql]
prompt=db01 [\\d]>
[mysqld]
user=mysql
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=51
port=3306
autocommit=0
log_bin=/data/3306/binlog/mysql-bin
log_bin_index=/data/3306/binlog/mysql-bin.index
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[root@db02 ~]# cat /data/3306/my.cnf
[mysql]
prompt=db02 [\\d]>
[mysqld]
user=mysql
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=52
port=3306
log_bin=/data/3306/binlog/mysql-bin
log_bin_index=/data/3306/binlog/mysql-bin.index
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[root@db01 ~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
[root@db02 ~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
[root@db01 ~]# /usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf &
[root@db02 ~]# /usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf &
主从复制GTID配置重构主从
[root@db01 ~]# mysql --defaults-file=/data/3306/my.cnf -uroot -p
db01 [(none)]>create user repl@'10.0.0.%' identified with mysql_native_password by '123456';
db01 [(none)]>grant replication slave on *.* to repl@'10.0.0.%';
change master to master_host='10.0.0.51', master_user='repl', master_password='123456', master_auto_position=3; -- 表示让从库自己找寻复制同步数据的起点; -- 在第一次启动gtid功能时,会读取从库中的binlog日志信息,根据主库uuid信息,获取从库中执行过的主库gtid信息 -- 从从库中没有执行过的主库gtid信息之后进行进行数据同步操作 db02 [(none)]> start slave;
进行数据库全备恢复数据时不要加set-gtid-purged参数
如果是已经运行很久的数据库,需要构建主从,都是需要备份恢复主库数据后,再开启实现主从功能的;
在mysqldump进行备份数据时,不要加set-gtid-purged参数,否则会造成从库依旧从第一个gtid信息开始同步数据;
造成主从同步数据信息冲突,影响主从构建过程,导致主从同步过程失败;
# 未加set-gtid-purged参数实现的数据备份效果 [root@db01 ~]# mysqldump -A --master-data=2 --single-transaction >/tmp/full.sql Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events. [root@xiaoQ-01 ~]# vim /tmp/full.sql SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '3cfa5898-771a-11ed-b8d7-000c2996c4f5:1-2'; -- 表示让从库删除1-2的集合信息,即通过备份文件已经恢复了1-2的数据,可以从1-2之后进行数据信息同步; # 已加set-gtid-purged参数实现的数据备份效果 [root@db01 ~]# mysqldump -A --master-data=2 --single-transaction --set-gtid-purged=OFF >/tmp/full02.sql [root@db01 ~]# vim /tmp/full.sql SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '3cfa5898-771a-11ed-b8d7-000c2996c4f5:1-2'; SET SQL_LOG_BIN=0; -- 以上信息不会出现在备份文件中 -- 表示会让从库把备份文件中的操作语句,再次根据gtid请求执行一遍,容易产生异常冲突问题;
clone复制
利用克隆插件可实现数据迁移、备份恢复及主从同步,快速构建从库。该技术尤其适用于运行中的数据库建立主从架构,能显著提升数据备份与恢复的效率
- 环境准备
| 主机角色 | 主机名称 | 地址信息 |
|---|---|---|
| 主库服务器 | db-01 | 10.0.0.51 |
| 从库服务器 | db-03 | 10.0.0.53 |
[root@db03 ~]# rm -rf /data/3306/data/*
[root@db03 ~]# rm -rf /data/3306/binlog/*
cat >/data/3306/my.cnf<<EOF [mysqld] basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=53 port=3306 gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 [mysql] prompt=db03 [\\d]>
EOF
[root@db03 ~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
[root@db03 ~]# /usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf &
主从复制克隆环境功能配置
# 实现免交互方式安装插件和创建用户(主库操作)
[root@db01 ~]# mysql -e "INSTALL PLUGIN clone SONAME 'mysql_clone.so';create user clone_user@'%' identified by '123456';grant backup_admin on *.* to 'clone_user'@'%';"
# 实现免交互方式安装插件和创建用户(从库操作)
[root@db03 ~]# mysql -e "INSTALL PLUGIN clone SONAME 'mysql_clone.so';create user clone_user@'%' identified by '123456';grant clone_admin on *.* to 'clone_user'@'%';set global clone_valid_donor_list='10.0.0.51:3306';"
# 从库上启动克隆功能 [root@db03 ~]# mysql -uclone_user -p123456 -h10.0.0.53 -P3306 mysql> clone instance from clone_user@'10.0.0.51':3306 identified by '123456'; -- 在从库在执行,用于发起一次主库到从库的完整数据克隆 # 实现克隆状态情况监控 [root@db03 ~]# mysql -e 'select stage,state,end_time from performance_schema.clone_progress;' +-----------+-----------+----------------------------+ | stage | state | end_time | +-----------+-----------+----------------------------+ | DROP DATA | Completed | 2025-09-21 18:35:36.100428 | | FILE COPY | Completed | 2025-09-21 18:35:36.687392 | | PAGE COPY | Completed | 2025-09-21 18:35:36.728275 | | REDO COPY | Completed | 2025-09-21 18:35:36.732173 | | FILE SYNC | Completed | 2025-09-21 18:35:37.126976 | | RESTART | Completed | 2025-09-21 18:35:41.049421 | | RECOVERY | Completed | 2025-09-21 18:35:42.363507 | +-----------+-----------+----------------------------+
主从克隆复制完毕后实现主从
[root@db03 ~]# mysql -e 'select binlog_file,binlog_position,@@GLOBAL.gtid_executed \
as donor_gtid_executed from performance_schema.clone_status;' +------------------+-----------------+-------------------------------------------+ | binlog_file | binlog_position | donor_gtid_executed | +------------------+-----------------+-------------------------------------------+ | mysql-bin.000002 | 736604 | 1dae5cc0-969b-11f0-83e4-000c29e3dc70:1-16 | +------------------+-----------------+-------------------------------------------+
-- 克隆操作完成后,主库二进制的精确位置及其对应的gtid号,从库只需从这个点/gtid开始实现主从同步
多源复制(MSR)

在业务架构设计上进行了垂直拆分,但是当需要进行数据信息统一查询分析时,会出现数据库孤岛问题
数据库中台技术(将多个业务数据库数据实时汇总到一个统一平台,形成企业级数据资源池),便于进行数据节点统一管理,便于进行数据信息统一分析
为实现数据中台构建,可将多业务主库通过多源复制(5.7+)汇总至只读从库,专用于数据分析
| 主机角色 | 主机名称 | 地址信息 |
|---|---|---|
| 主库服务器 | 10.0.0.51 | 3306 |
| 主库服务器 | 10.0.0.52 | 3306 |
| 从库服务器 | 10.0.0.53 | 3306 |
对原有的数据环境清理(基于GTID环境构建)
pkill mysqld rm -rf /data/3306/data/* rm -rf /data/3306/binlog/*
cat >/data/3306/my.cnf <<EOF [client] socket=/tmp/mysql.sock [mysql] prompt=db01 [\\d]> socket=/tmp/mysql.sock [mysqld] user=mysql basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=51 port=3306 log_bin=/data/3306/binlog/mysql-bin log_bin_index=/data/3306/binlog/mysql-bin.index binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 -- 生成慢日志信息功能配置参数 slow_query_log=ON slow_query_log_file=/data/3306/data/db01-slow.log long_query_time=0.1 log_queries_not_using_indexes master_info_repository=TABLE -- 将master_info信息以表方式记录 relay_log_info_repository=TABLE -- 将relay_log_info信息以表方式记录 innodb_flush_method=O_DIRECT 让 InnoDB 绕过操作系统缓存直接读写磁盘数据文件,以避免双缓冲,提升内存使用效率和 I/O 性能 EOF 双缓冲是指同一份数据既在 InnoDB 的缓冲池(Buffer Pool)中缓存了一次,又在操作系统的页缓存(Page Cache)中缓存了第二次 页缓存是操作系统用空闲内存来缓存磁盘数据的一种机制,目的是加速磁盘读写


[client] socket=/tmp/mysql.sock [mysql] prompt=db02 [\\d]> socket=/tmp/mysql.sock [mysqld] user=mysql basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=52 port=3306 log_bin=/data/3306/binlog/mysql-bin log_bin_index=/data/3306/binlog/mysql-bin.index binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 slow_query_log=ON slow_query_log_file=/data/3306/data/db01-slow.log long_query_time=0.1 log_queries_not_using_indexes master_info_repository=TABLE relay_log_info_repository=TABLE innodb_flush_method=O_DIRECT
[client] socket=/tmp/mysql.sock [mysql] prompt=db03 [\\d]> socket=/tmp/mysql.sock [mysqld] user=mysql basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=53 port=3306 log_bin=/data/3306/binlog/mysql-bin log_bin_index=/data/3306/binlog/mysql-bin.index binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 slow_query_log=ON slow_query_log_file=/data/3306/data/db01-slow.log long_query_time=0.1 log_queries_not_using_indexes master_info_repository=TABLE relay_log_info_repository=TABLE innodb_flush_method=O_DIRECT
mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data /usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf &
主从多源复制重构主从环境
-- 两个主库上创建主从复制用户信息,并且不要产生创建用户日志信息,因为多个主节点可能用户信息不一致,会导致同步异常 db01 [(none)]>set sql_log_bin=0; db01 [(none)]>create user repl@'10.0.0.%' identified with mysql_native_password by '123456'; db01 [(none)]>grant replication slave on *.* to repl@'10.0.0.%'; db01 [(none)]>set sql_log_bin=1; db02 [(none)]>set sql_log_bin=0; db02 [(none)]>create user repl@'10.0.0.%' identified with mysql_native_password by '123456'; db02 [(none)]>grant replication slave on *.* to repl@'10.0.0.%'; db02 [(none)]>set sql_log_bin=1; db03 [(none)]>change master to -> master_host='10.0.0.51', -> master_user='repl', -> master_password='123456', -> master_auto_position=1 for channel 'Master_1'; Query OK, 0 rows affected, 7 warnings (0.01 sec) db03 [(none)]>change master to -> master_host='10.0.0.52', -> master_user='repl', -> master_password='123456', -> master_auto_position=1 for channel 'Master_2'; Query OK, 0 rows affected, 7 warnings (0.01 sec) 复制通道(Replication Channel)是一个逻辑概念,用于让一个从库能够通过多个独立的、并行的连接(每个连接就是一个通道)同时从多个主库复制数据
db03 [(none)]> show slave status for channel 'Master_1'\G db03 [(none)]> show slave status for channel 'Master_2'\G -- 多源主从状态监控信息分别查看,重点关注Channel_Name信息和IO SQL线程状态 db03 [(none)]> use performance_schema; db03 [(none)]> select * from replication_connection_configuration\G db03 [(none)]> select * from replication_connection_status where channel_name='master_1'\G db03 [(none)]> select * from replication_connection_status where channel_name='master_2'\G -- 多源主从状态监控信息汇总查看,或进行单独查看 db03 [(none)]> select * from performance_schema.replication_applier_status_by_worker\G; -- 多源主从复制线程工作情况查看,了解即可
主从多源复制数据信息过滤
如果多个主库之间存在相同的数据表信息,在进行多源复制时,需要进行过滤处理,避免汇总在从库中产生数据不一致的情况;
STOP SLAVE SQL_THREAD FOR CHANNEL 'Master_2';
CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE = ('world.%') FOR CHANNEL 'Master_2';
告诉名为 Master_2 的复制通道,只复制 world 这个数据库里所有表的数据,其他数据库的数据全部忽略
START SLAVE SQL_THREAD FOR CHANNEL 'Master_2';
数据组复制(MGR)
概念介绍
MGR(MySQL Group Replication MySQL组复制)提供了高可用、高扩展、高可靠的MySQL集群服务 在MGR出现之前,用户常见的MySQL高可用方式,无论怎么变化架构,本质就是Master-Slave架构 MySQL 5.7.17版本开始支持无损半同步复制,从而进一步提升数据复制的强一致性 MGR是MySQL官方在5.7.17版本引进的一个数据库高可用与高扩展的解决方案,以插件形式提供 MGR基于分布式paxos协议,实现组复制,保证数据一致性 MGR采用多副本,在2N+1个节点集群中,集群只要N+1个节点还存活着,数据库就能稳定的对外提供服务 主要涉及的功能应用包含: 具有多节点之间互相通过投票的方式进行监控功能;(基于paxos协议) 具有内置故障检测和自动选主功能,只要不是集群中的大多数节点都宕机,就可以继续正常工作; - 如果主节点异常,会自动选举新节点实现故障转移 - 如何从节点异常,会自动将从节点从复制节点踢除 提供单主模式与多主模式,多主模式支持多点写入;
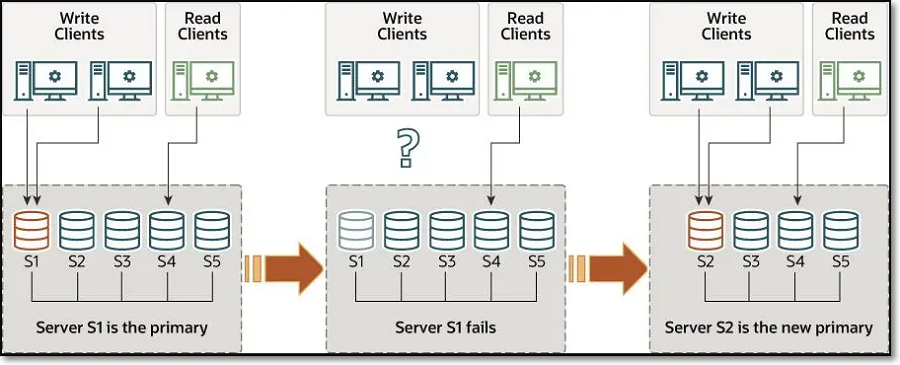
MGR单主模式(single-primary mode)
在MGR单主模式下,引导组的第一台服务器将自动成为唯一的读写模式主服务器,其后加入的所有其他成员则会自动被设置为只读模式
MGR单主模式选举原理:在MGR单主模式下,当主节点发生故障后,集群会自动发起选举,优先选择配置权重(member_weight)最高的在线成员作为新主,若权重相同或未配置,则选举server_uuid最小的成员为新主
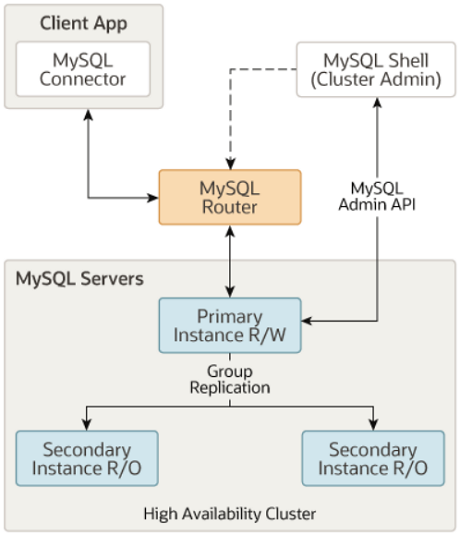
MySQL Router(数据库路由器),是一个轻量级的中间件,能自动将应用程序的请求路由到最合适的MySQL服务器上
利用MGR工作模式可以实现业务架构的读写分离需求,当MGR中主节点出现异常下线后,会选举出现的主节点,原生态router技术可以自动识别新的主节点,做读写分离的写库;
MySQL MGR + MySQL Router + MySQL Shell = InnoDB Cluster
InnoDB Cluster:https://dev.mysql.com/doc/mysql-shell/8.0/en/mysql-innodb-cluster.html
MGR多主模式(multi-primary mode)
MGR多主模式下无单一主节点概念,无主从之分,所有成员均为读写模式,故无需选举
在多主模式下,组内所有成员均对外提供读写服务,实现真正意义上的并发

MGR工作机制原理

1.当客户端发起一个更新事务时,该事务先在本地执行,执行完成之后就要发起对事务的提交操作
2.在还没有真正提交之前,需要将产生的复制写集广播出去,复制到其它所有成员节点
主库事务提交时,会将事务修改行的主键、新数据的写集、全局事务id发送给所有系欸但
3.如果冲突检测成功,组内决定该事务可以提交,其它成员可以应用,否则就回滚;
冲突检测成功的标准是:至少半数以上个节点投票通过才能事务提交成功;
4.最终,所有组内成员以相同的顺序接收同一组事务;
| 主机角色 | 主机名称 | 地址信息 |
|---|---|---|
| 主库服务器 | 10.0.0.51 | 3306 |
| 从库服务器 | 10.0.0.52 | 3306 |
| 从库服务器 | 10.0.0.53 | 3306 |
对原有数据库服务环境清理(基于GTID环境构建)
# 对所有主从节点均进行清理操作 pkill mysqld rm -rf /data/3306/data/* rm -rf /data/3306/binlog/* # 获取随机数信息充当uuid信息 [root@db01 ~]# cat /proc/sys/kernel/random/uuid 23b8bd68-81f4-4c7b-9558-83964c31f91a
skip_name_resolve=ON 禁止将ySQL服务器将客户端连接的主机名解析为ip地址(显著加快连接速度)
report_host=10.0.0.51
告诉组中的其他成员,应当用这个ip和端口连接本节点
binlog_checksum=NONE 禁止为二进制事件生成校验和(组复制使用了自己的故障检测和一致性机制,二进制的校验功能会与之冲突,导致复制中断)
group_replication变量使用的loose-前缀是指server启用时尚未加载复制插件也将继续启动
| binlog_transaction_dependency_tracking |
binlog_transaction_dependency_tracking=WRITESET |
| transaction_write_set_extraction | transaction_write_set_extraction=XXHASH64 使用指定的哈希算法计算事务修改的每一行数据 (用于精确识别不同事务之间是否存在修改同一行数据的冲突) |
| loose-group_replication_group_name | loose-group_replication_group_name="40c90eac-34ee-41e8-b892-fd0eb8c1b884" 表示将加入或创建的复制组命名为40c90eac-34ee-41e8-b892-fd0eb8c1b884 可以自定义或者通过cat /proc/sys/kernel/random/uuid获取 |
| loose-group_replication_start_on_boot=OFF | loose-group_replication_start_on_boot=OFF 表示服务启动时启动时不自动启动组复制 |
| loose-group_replication_local_address | loose-group_replication_local_address="10.0.0.51:33061" 表示等一本地主机数据库服务的内部通讯地址和端口 |
| loose-group_replication_group_seeds | loose-group_replication_group_seeds="10.0.0.51:33061,10.0.0.52:33062,10.0.0.53:33063" 表示定义所有集群主机的内部通讯地址和端口 |
| loose-group_replication_bootstrap_group=OFF | 表示是否将此节点设置为引导节点 |
-- 以上参数信息中loose,表示在没有组复制插件时,进行初始化操作只会报警告信息,而不会报错误提示
[client] socket=/tmp/mysql.sock [mysql] prompt=db01 [\\d]> socket=/tmp/mysql.sock [mysqld] user=mysql basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=51 port=3306 mysqlx=OFF default_authentication_plugin=mysql_native_password log_bin=/data/3306/binlog/mysql-bin log_bin_index=/data/3306/binlog/mysql-bin.index binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 master_info_repository=TABLE relay_log_info_repository=TABLE skip_name_resolve=ON report_host=10.0.0.51 report_port=3306 binlog_checksum=NONE binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="40c90eac-34ee-41e8-b892-fd0eb8c1b884" loose-group_replication_start_on_boot=OFF loose-group_replication_local_address="10.0.0.51:33061" loose-group_replication_group_seeds="10.0.0.51:33061,10.0.0.52:33062,10.0.0.53:33063" loose-group_replication_bootstrap_group=OFF
[client] socket=/tmp/mysql.sock [mysql] prompt=db02 [\\d]> socket=/tmp/mysql.sock [mysqld] user=mysql basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=52 port=3306 mysqlx=OFF default_authentication_plugin=mysql_native_password log_bin=/data/3306/binlog/mysql-bin log_bin_index=/data/3306/binlog/mysql-bin.index binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 master_info_repository=TABLE relay_log_info_repository=TABLE skip_name_resolve=ON report_host=10.0.0.52 report_port=3306 binlog_checksum=NONE binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="40c90eac-34ee-41e8-b892-fd0eb8c1b884" loose-group_replication_start_on_boot=OFF loose-group_replication_local_address="10.0.0.52:33062" loose-group_replication_group_seeds="10.0.0.51:33061,10.0.0.52:33062,10.0.0.53:33063" loose-group_replication_bootstrap_group=OFF
[client] socket=/tmp/mysql.sock [mysql] prompt=db03 [\\d]> socket=/tmp/mysql.sock [mysqld] user=mysql basedir=/usr/local/mysql datadir=/data/3306/data socket=/tmp/mysql.sock server_id=53 port=3306 mysqlx=OFF default_authentication_plugin=mysql_native_password log_bin=/data/3306/binlog/mysql-bin log_bin_index=/data/3306/binlog/mysql-bin.index binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 master_info_repository=TABLE relay_log_info_repository=TABLE skip_name_resolve=ON report_host=10.0.0.53 report_port=3306 binlog_checksum=NONE binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="40c90eac-34ee-41e8-b892-fd0eb8c1b884" loose-group_replication_start_on_boot=OFF loose-group_replication_local_address="10.0.0.53:33063" loose-group_replication_group_seeds="10.0.0.51:33061,10.0.0.52:33062,10.0.0.53:33063" loose-group_replication_bootstrap_group=OFF
mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
/usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf &
MGR单主模式配置
# 设置本地root用户密码和密码插件(所有节点) mysql -S /tmp/mysql.sock -e "alter user 'root'@'localhost' identified with mysql_native_password by '123456'" # 安装部署MGR组复制功能插件(所有节点) mysql -uroot -p123456 -S /tmp/mysql.sock -e "install plugin group_replication SONAME 'group_replication.so';" # 设置创建MGR组复制功能账号(所有节点) mysql> set sql_log_bin=0; mysql> create user repl@'%' identified by '123'; mysql> grant replication slave,replication client on *.* to repl@'%'; mysql> flush privileges; mysql> set sql_log_bin=1; # 启动MGR单主模式:启动MGR引导节点(在主库上执行) db01 [(none)]> change master to master_user='repl',master_password='123' for channel 'group_replication_recovery';
为组复制的数据恢复通道配置认证信息,以便节点在加入集群时能用此账户从其他节点恢复数据
db01 [(none)]> set global group_replication_bootstrap_group=ON;
指示当前节点引导初始化一个全新的组复制集群(此命令仅在首次启动整个集群时在一个节点上执行)
db01 [(none)]> start group_replication;
启动当前MySQL实例的组复制引擎,使其尝试加入组
db01 [(none)]> set global group_replication_bootstrap_group=OFF;
关闭引导模式,防止后续节点错误地初始化一个已存在的集群
# 查看集群节点状态信息,以及集群成员信息
db01 [(none)]> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | d55b70d5-979c-11f0-9e0a-000c29e3dc70 | 10.0.0.51 | 3306 | ONLINE | PRIMARY | 8.0.26 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
# 其他几点加入MGR(在所有从库上执行)
reset master;
如果不清理从库上面的日志的话,执行 start group_replication;
ERROR 3092 (HY000): The server is not configured properly to be an active member of the group. Please see more details on error log.
change master to master_user='repl',master_password='123' for channel 'group_replication_recovery';
start group_replication;
show variables like '%only%';
+----------------------------------------+-------+
| Variable_name | Value |
+----------------------------------------+-------+
| read_only | ON |
| super_read_only | ON |
+----------------------------------------+-------+
-- 此时所有从库节点只能实现只读操作,只有主库可以进行写操作
# 遇到集群构建异常,可以进行重置操作
stop group_replication;
reset master;
set sql_log_bin=0;
change master to master_user='repl',master_password='123' for channel 'group_replication_recovery';
start group_replication;

MRG多主模式配置(从单主模式切换到多主模式)
- group_replication_single_primary_mode=0 表示关闭单主模式
- group_replication_enforce_update_everywhere_checks=1 表示多主模式下各节点进行严格一致性检查
- MGR切换模式流程
- 关闭所有节点的组复制功能
- 设置所有节点的group_replication_single_primary_mode、group_replication_enforce_update_everywhere_checks参数
- 重启所有节点的组复制功能
MGR切换模式需要重新启动组复制,因此需要在所有节点上先关闭组复制,设置group_replication_single_primary_mode=OFF参数,再重新启动组复制功能
# 多主模式功能配置(在所有节点上执行) stop group_replication; set global group_replication_single_primary_mode=OFF; set global group_replication_enforce_update_everywhere_checks=1; select @@group_replication_single_primary_mode,@@group_replication_enforce_update_everywhere_checks;
-- 查询并确认当前MySQL Group Replication (MGR)集群的运行模式是单主模式还是多主模式group_replication_single_primary_mode -- 是否启用单主模式group_replication_enforce_update_everywhere_checks -- 是否启用多主模式下的严格冲突检查
set global group_replication_bootstrap_group=ON;
start group_replication;
set global group_replication_bootstrap_group=OFF;
-- 重新启动MGR组复制功能,是多主模式生效(主节点操作)
start group_replication;
-- 重新启动MGR组复制功能,是多主模式生效(从节点操作)

多主模式切换到单主模式
MGR切换模式需要重新启动组复制,因此需要在所有节点上先关闭组复制,设置group_replication_single_primary_mode=OFF参数,再重新启动组复制功能
# 所有节点执行以下操作 stop group_replication; set global group_replication_enforce_update_everywhere_checks=OFF; set global group_replication_single_primary_mode=ON; # 在主节点执行以下操作 set global group_replication_bootstrap_group=ON; start group_replication; set global group_replication_bootstrap_group=OFF; # 在从节点执行以下操作 start group_replication; # 查看MGR组信息: select * from performance_schema.replication_group_members;
MGR复制同步功能运维管理
当宕机的节点修复并重新加入MGR组时,他会自动从当前主节点同步数据,追平宕机期间错过的所有变更的数据,如果宕机时间较长/数据变更数量较多,则先克隆再加入MGR组
# MGR日常管理监控操作(根据命令信息输出,获取各个节点主机的状态情况) select * from performance_schema.replication_group_members; # MGR故障模拟操作过程: [root@db01 ~]# pkill mysqld -- 模拟主节点宕机,会自动选举新的主节点 mysql> select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ | group_replication_applier | 0a09b03e-7b95-11ed-9af8-000c29f5669f | 10.0.0.53 | 3306 | ONLINE | PRIMARY | 8.0.26 | | group_replication_applier | fe73f0b4-7b94-11ed-96ea-000c2961cd06 | 10.0.0.52 | 3306 | ONLINE | SECONDARY | 8.0.26 | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ [root@db01 ~]# /usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf & db01 [(none)]>start group_replication; -- 立即回复宕机节点,被恢复的节点自动变成从节点 db02 [(none)]>select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ | group_replication_applier | 0a09b03e-7b95-11ed-9af8-000c29f5669f | 10.0.0.53 | 3306 | ONLINE | PRIMARY | 8.0.26 | | group_replication_applier | f90d44f9-7b94-11ed-ab2d-000c2996c4f5 | 10.0.0.51 | 3306 | ONLINE | SECONDARY | 8.0.26 | | group_replication_applier | fe73f0b4-7b94-11ed-96ea-000c2961cd06 | 10.0.0.52 | 3306 | ONLINE | SECONDARY | 8.0.26 | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+ # 通过克隆功能添加新的节点 [root@db01 ~]# pkill mysqld [root@db01 ~]# rm -rf /data/3306/data/* [root@db01 ~]# rm -rf /data/3306/binlog/* [root@db01 ~]# vim /data/3306/my.cnf [root@db01 ~]# mysqld --initialize-insecure --user=mysql \
--basedir=/usr/local/mysql --datadir=/data/3306/data [root@db01 ~]# /usr/local/mysql/bin/mysqld_safe --defaults-file=/data/3306/my.cnf & [root@db01 ~]# mysql -S /tmp/mysql.sock -e "alter user 'root'@'localhost' \
identified with mysql_native_password by 'root';" [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock -e \
"install plugin group_replication SONAME 'group_replication.so';"
-- 安装部署MGR组复制功能插件 # 在数据库服务正常节点上(随机一台正常的服务器),创建克隆捐赠者用户信息 [root@db03 ~]# mysql -uroot -proot -S /tmp/mysql.sock -e \ "INSTALL PLUGIN clone SONAME 'mysql_clone.so';\ create user clone_jz@'%' identified by '123456';\ grant backup_admin on *.* to 'clone_jz'@'%';" # 在新节点上创建一个克隆专用用户 [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock -e \ "INSTALL PLUGIN clone SONAME 'mysql_clone.so';\ create user clone_js@'%' identified by '123456';\ grant clone_admin on *.* to 'clone_js'@'%';\ set global clone_valid_donor_list='10.0.0.53:3306';" [root@db01 ~]# mysql -uclone_js -p123456 -h10.0.0.51 -P3306 \
-e "clone instance from clone_jz@'10.0.0.53':3306 identified by '123456';"
-- 在新节点上进行克隆 [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock -e \
"select stage,state,end_time from performance_schema.clone_progress;"
-- 检查克隆是否完毕 # 将新节点加入到组复制集群中
reset master;
change master to master_user='repl',master_password='123' for channel 'group_replication_recovery';
change master to master_user='repl',master_password='123' for channel 'group_replication_recovery';
-- 查看组复制成员状态信息
应用限制说明
在应用MGR组复制功能时,也存在一些应用的限制条件:
-
仅支持innodb存储引擎应用组复制功能;
MGR集群中只支持innodb存储引擎,能够创建非innodb引擎的表,但是无法写入数据,向非innodb表写入数据直接报错;
-
数据表中必须有主键,或者非null的唯一键;
MGR集群中只支持innodb存储引擎,并且该表必须有显示的主键,或者非null的唯一键,否则即使能够创建表,也无法向表中写数据
-
组复制存在网络限制,MGR组通信引擎目前仅支持IPv4网络,并且对节点间的网络性能要求较高;
对于低延迟、高带宽的网络是部署MGR集群的基础;
-
组复制功能会自动忽略表锁和命名锁,在MGR中lock tables、unlock tables、get_lock、release_lock等这些表锁和命名锁将忽略
-
MGR多主模式中,默认不支持 SERIALIZABLE 隔离级别,建议使用RC隔离级别;
-
组复制多主模式中,对同一个对象进行并发是有冲突的,ddl和dml操作导致这种冲突在部分成员节点中无法检测到;
最终可能导致数据不一致
-
组复制多主模式中,不支持级联约束的外键,可能造成有冲突的操作无法检查;
-
组复制功能不支持超大事务同步;
-
组复制多主模式下可能导致死锁,比如select ... for update在不同节点执行,由于多节点锁无法共享,很容易导致死锁;
-
组复制是不支持复制过滤的,如果有节点设置了复制过滤功能,将影响节点间决议的达成;
-
组复制功能最多支持9个节点,当大于9个节点,将拒绝新节点的加入;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号