


数据库逻辑备份
数据库备份基础
数据库服务备份恢复目的
在企业环境中,无论是安全人员、运维人员、开发人员、数据库管理人员等所有技术人员都有一个共同的职责:
保障数据安全,防止数据库损坏
- 数据库物理损坏:磁盘、文件系统、数据文件(可以利用主从、高可用、备份+日志恢复数据)
- 数据库逻辑损坏:drop、truncate、delete、update(可以利用备份+日志、延时从库)
其中对于数据库服务来说,保障数据库服务的数据安全需要考量两个重要的指标:
- 一定要保障数据不能丢失和泄露;
- 一定要保障数据存储服务的稳定;(业务7*24)
说明:为了保障数据信息不丢失,最好的处理方案就是做备份,甚至是做多副本备份,多区域备份;就算丢失损坏也能快速复原。
数据库服务备份恢复职责
- 设计数据库备份策略:备份数据周期、选择的备份工具、应用的备份方式(全备 增量..);
- 定期数据库备份检查:核实是否存在、确认备份文件大小;
- 安排数据库恢复演练:真实确认备份的数据,是否能够准确的做数据恢复;
- 真实数据库恢复能力:在数据库服务出现异常情况时,可以将数据库服务修复,并恢复丢失的数据信息;
- 关于数据库迁移升级:可以采用Mergeing方式(主从架构)、可以单独备份数据信息到新的数据库节点做恢复(逻辑导出);
数据库服务备份数据方式
# 物理备份方式:冷备/热备(从底层数据页或文件信息进行备份) 采用拷贝物理文件数据进行备份的方式,数据库服务物理数据文件存放路径是:/var/lib/mysql 实现方式: 可以在某个特定时间点停机或停止业务访问,然后利用cp和tar命令将物理数据文件备份或打包; 可以在任意时间节点在不停机不停止业务时,然后利用专业的xtrabackup(Percona Xtrabackup)热备工具进行数据库数据备份; 应用场景: 当企业数据库服务产生的需要备份的数据量在50G以上,可以选择物理备份(xtrabackup); # 逻辑备份方式:热备(将数据库中生成数据的语句进行备份) 可以采用以SQL语句形式把数据库的数据导出保存备份为数据库文件(xxx.sql),文件中会含有大量SQL语句信息; 实现方式: 可以在任意时间节点在不停机不停止业务时,然后利用专业的mysqldump(MDP)逻辑备份工具进行数据备份; 可以在任意时间节点在不停机不停止业务时,然后利用二进制日志binlog文件实现逻辑备份数据操作; 可以在任意时间节点在不停机不停止业务时,然后利用主从数据库架构实现备份数据信息; 应用场景: 当企业数据库服务产生的需要备份的数据量在50G以内,可以选择逻辑备份(mysqldump);
mysqldump⭐⭐⭐⭐⭐
mysqldump命令简述
在进行数据库数据逻辑备份操作过程中,主要会运用mysqldump逻辑备份工具,可以实现本地或远程的数据备份;
利用mysqldump进行逻辑备份数据时,主要的备份逻辑是将建库、建表、数据插入语句信息导出,实现数据的备份操作;
基于mysqldump备份数据的逻辑原理,对于数据量比较小的场景(单表数据行百万以内),mysqldump备份工具做备份会更适合些;
在跨平台或跨版本进行数据库数据信息迁移时,mysqldump备份工具做备份也会比较适合,可以避免物理备份的兼容性问题;
说明:在一般情况下,对数据库进行数据恢复的时间耗费,大约是数据库进行数据备份的时间耗费的3~5倍。
mysqldump:将数据库中的结构和数据以SQL语句的形式导出到文本文件 [root@db01 ~]# mysqldump -u数据库用户 -p数据库密码 -h数据库地址 -P数据库端口号 \ [备份参数] >/路径信息/数据库备份文件.sql 备份参数: -A 表示备份所有库中数据信息 -B 表示备份指定库中数据信息 -F 表示在备份启动前自动刷新日志文件 [root@db01 ~]# mkdir -p /database_backup
数据库全备(-A)
[root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock -A >/database_backup/all_database.sql [root@db01 ~]# ll /database_backup/all_database.sql -rw-r--r-- 1 root root 1667744 Sep 18 21:00 /database_backup/all_database.sql -- 利用mysqldump命令备份的数据文件是纯文本文件 利用-A创建数据库备份数据时,在备份数据中会含有 create建库语句和use切换库语句,可以直接进行恢复操作
数据库单库或多库备份(-B)
- 将数据库中单个/多个数据库进行备份
# 将数据库中单个数据库进行备份 [root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock -B school \ >/database_backup/school.sql [root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock --set-gtid-purged=OFF \ -B school >/database_backup/school_nogtid.sql # 将数据库中多个数据库进行备份 [root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock -B world,school >/database_backup/world_school.sql [root@db01 ~]# ll /database_backup/school* -rw-r--r-- 1 root root 4693 Sep 19 14:50 /database_backup/school_nogtid.sql -rw-r--r-- 1 root root 4968 Sep 19 10:11 /database_backup/school.sql [root@db01 ~]# egrep -vi '^-|*/\*|^lock' /database_backup/all_database.sql
- 数据恢复
不管对应的数据库或者表存不存在,强制执行全部SQL命令,先删除已有表再重建,最终用备份数据完全覆盖当前数据
-- 模拟删除数据库中数据表信息,造成数据库中数据损坏 mysql> drop table sc; mysql> show tables; +------------------+ | course | | student | | teacher | +------------------+ -- 进行数据库数据复原操作: 方式一:在数据库中加载数据库备份文件 mysql> source /database_backup/school.sql -- 此操作哪怕school数据库不存在也不会报错 方式二:在操作系统命令行执行数据恢复命令(该方式如果school数据库不存在则报错) [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock school </database_backup/school.sql ERROR 3546 (HY000) at line 24: @@GLOBAL.GTID_PURGED cannot be changed: the added gtid set must not overlap with @@GLOBAL.GTID_EXECUTED [root@db01 ~]# mysql -uroot -proot -S /tmp/mysql.sock school </database_backup/school_nogtid.sql 为什么同一个包含GTID信息的SQL备份文件,在MySQL客户端内用source命令导入能成功,\
但通过命令行重定向<导入却会报GTID冲突错误? source 命令逐行执行时会因权限不足自动跳过 GTID 设置语句,\
而命令行重定向会整体解析文件并严格执行 GTID 一致性检查,故后者报错
说明:利用-B创建数据库备份数据时,在备份数据中会含有 create建库语句和use切换库语句,可以直接进行恢复操作即可;
数据库单表或多表备份
-- 单表备份 [root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock school sc>/database_backup/school_sc.sql -- 多表备份 [root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock school student teacher>/database_backup/school_student_and_teacher.sql
说明:数据库单表或多表进行数据备份时,在备份数据中不含有create建库语句和use切换库语句,需要建库并指定库再恢复数据;
--single-transaction
参数理解:比如在某个时刻班主任希望统计班级同学的数量情况,那么该如何统计准确呢?
方法一:
形象说明:锁门封闭统计,禁止人员在教室内外随意走动,取班级人数变化的静止状态的学生数量;
真实应用:锁表封闭备份,禁止数据库程序进行数据更新操作,实现静止锁表状态进行数据备份;(一般选择半夜操作)
方法二:
形象说明:瞬时拍照统计,允许人员在教室内外随意走动,但是会根据拍照时刻人员数量进行统计;
真实应用:瞬时节点备份,允许数据库程序进行数据更新操作,只将备份操作瞬间已有数据进行备份;
利用--single-transaction参数进行数据备份,就等价于在备份的时候给数据库的数据拍了照,备份时候数据库可以继续更新
-- 对于InnoDB存储引擎的表,将会利用MVCC中的一致性快照进行备份(只适用于多版本控制的存储引擎中的表)
-- 在备份期间不要出现DDL操作语句,如果出现DDL语句,将会导致备份数据不一致
--master-data=2(只在全备才有意义)
数据备份痛点:在进行数据库全备+binlog恢复数据时,如何进行binlog的临界点(起点)截取操作? 在备份数据的时候会记录binlog日志位置点到备份文件中,这个位置点是上一次全备之后新增数据的临界点; 在未来数据库服务出现异常时,会先恢复全备的数据信息,然后恢复binlog日志临界点之后的数据信息; 在指定日志位置点进行备份的时候,生成的操作日志语句如下: -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000013', MASTER_LOG_POS=11812; 命令参数官方信息详细解读: 利用此参数功能,可以实现自动记录位置点信息; 利用此参数功能,可以实现自动添加全局读锁(GRL)功能(在配合--single-transaction参数使用时,可以减少锁时间);
gzip--压缩备份
-- 压缩备份 [root@db01 ~]# mysqldump -uroot -proot -S /tmp/mysql.sock -A \
--master-data=2|gzip >/database_backup/all_master_data.sql
-R -E --triggers
某周周二晚零点,企业数据库管理员进行一次数据库服务数据全备操作
| 参数信息 | 解释说明 |
|---|---|
| -R | 表示进行数据库存储过程备份 |
| -E | 表示进行数据库事件信息备份 |
| --triggers | 表示进行触发器信息备份 |
-- max_allowed_packet=64M
此参数表示允许进行传输的数据包大小,在某些时候如果备份的数据为大表数据,需要调整此参数信息;
如果没有正确的设置此参数信息,可能会导致备份大表数据时,会出现数据备份失败的情况;
数据库逻辑备份应用案例⭐⭐⭐⭐⭐
项目实战背景:
在某某小型企业工作环境时,企业数据库服务数据存储量小于50G,每天会在23点进行前一天数据的全备操作,并已开启binlog功能;
项目故障说明:
在某周周三下午14点左右,由于开发人员连接数据库实例错误,导致企业数据库服务生产数据被误删除了,亟待相关人员解决;
故障处理思路:
需要在网站首页或者应用程序首页显示业务端维护页;
检查利用mysqldump命令全备的数据文件、以及查看binlog日志功能是否已经开启;
利用部分全备数据和增量数据完成数据库所有数据复原恢复工作;
数据库数据完整复原恢复进行数据信息核验工作,一般此类工作可以交由相关业务部门进行核验测试;
数据信息核验工作完毕后,可以在此时业务中断状态下,进行一次停机冷备操作,彻底完成一次数据物理备份;
所有相关线上业务进行恢复运行,并进行业务恢复后的功能性测试,一般交由测试人员进行完成;
撤销维护页面通知消息,实现用户可以正常访问。
项目实战模拟
- 01 模拟某周周一~周二,网站正常时用户访问网站进行数据库信息录入
-- 将binlog日志文件进行刷新,创建一个新的日志文件 mysql> flush logs; -- 模拟创建用户存储数据的数据库信息 mysql> create database mdb; mysql> use mdb; -- 模拟创建用户存储数据的数据表信息 mysql> create table t1 (id int); mysql> create table t2 (id int); -- 模拟用户向数据表中添加新的数据 mysql> insert into t1 values(1),(2),(3); mysql> insert into t2 values(1),(2),(3);
- 02 模拟某周周二晚零点,企业数据库管理员进行一次数据库服务数据全备操作
[root@db01 ~]# mysqldump -uroot -p -S /tmp/mysql.sock -A --master-data=2 \
--single-transaction -R -E --triggers --max_allowed_packet=64M \
>/database_backup/full_`date +%F`.sql
- 03 模拟某周周二晚零点之后,模拟用户继续访问网站业务产生了增量的数据信息
mysql> use mdb; mysql> create table t3 (id int); mysql> insert into t3 values(1),(2),(3); mysql> insert into t2 values(4),(5),(6); mysql> commit;
- 04 模拟某周周三下午14点,系统相关技术人员误删除了数据库,并且已紧急跑路
drop database mdb; -- 后续数据操作别的库的操作 mysql> usee test; mysql> drop table t1; mysql> drop table t2;
项目实战复原
- 01 查寻数据库服务全备数据,并进行全备数据恢复
[root@db01 ~]# ll /database_backup/full_2025-09-19.sql -rw-r--r-- 1 root root 1671712 Sep 19 16:36 /database_backup/full_2025-09-19.sql mysql> source /database_backup/full_2025-09-19.sql mysql> use mdb; mysql> show tables; -- 查看全备的数据是否恢复 +---------------+ | Tables_in_mdb | +---------------+ | t1 | | t2 | +---------------+
- 02 查询数据库服务增量数据,并进行增量数据恢复
# 检索恢复binlog临界位置 [root@db01 ~]# vim /database_backup/full_2025-09-19.sql SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '19dd4a42-6d59-11f0-9bb7-000c29e3dc70:1-108'; -- 表示在进行数据恢复操作时,会将gtid1-6的事件信息删除掉,因为在之前备份数据中已经有了1-108的事件数据信息; -- 因此,从GTID的编号来看,可以从编号7事件开始进行数据增量恢复; CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000014', MASTER_LOG_POS=1314; -- 输出信息表示增量数据的临界点在binlog.000013日志文件的1312位置,同时是备份结束时的位置点; # 检索查看binlog日志文件获取误删除操作前的GTID mysql> show binlog events in 'mysql-bin.000014'; +------------------+------+----------------+-----------+-------------+---------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +------------------+------+----------------+-----------+-------------+---------------------------------------------------------------------+ | mysql-bin.000014 | 2063 | Gtid | 6 | 2140 | SET @@SESSION.GTID_NEXT= '19dd4a42-6d59-11f0-9bb7-000c29e3dc70:112' | | mysql-bin.000014 | 2140 | Query | 6 | 2241 | drop database mdb /* xid=4358 */ | +------------------+------+----------------+-----------+-------------+---------------------------------------------------------------------+ -- 需要将GTID编号为112(positions=2063-2241)的事件忽略,然后在进行数据的恢复 # 操作截取binlog日志 [root@db01 ~]# mysqlbinlog --skip-gtids --include-gtids='19dd4a42-6d59-11f0-9bb7-000c29e3dc70:108-111' /data/3306/binlog/mysql-bin.000014 >/database_backup/add_bin108-111.sql [root@db01 ~]# mysqlbinlog --skip-gtids --include-gtids=\ '19dd4a42-6d59-11f0-9bb7-000c29e3dc70:113-' \ /data/3306/binlog/mysql-bin.000014 >/database_backup/add_bin113-.sql
# 增量恢复binlog数据信息 mysql> set sql_log_bin=0; -- 建议在进行数据日志恢复数据时,将数据恢复时执行的SQL语句信息,不做binlog日志记录;恢复后别忘在改为1; mysql> source /database_backup/add_bin108-111.sql mysql> source /database_backup/add_bin113-.sql -- 完成数据信息的增量恢复
- 03 检验
# 核验检查恢复后的数据信息 mysql> use mdb; Database changed mysql> show tables; +---------------+ | Tables_in_mdb | +---------------+ | t1 | | t2 | | t3 | +---------------+ # 完成核验之后数据完整备份 [root@db01 ~]# mysqldump -uroot -p -S /tmp/mysql.sock -A --master-data=2 \ --single-transaction -R -E --triggers --max_allowed_packet=64M \ >/database_backup/full_`date +%F`.sql
数据库逻辑备份痛点分析⭐⭐⭐⭐⭐
假设某个企业进行数据库服务的数据备份,将会采用数据库全备方案,每次全备会生成大约50G的数据信息; 并且每次数据库服务进行全备耗时大约15~30分钟,因此如果有需要进行数据恢复时,耗费时间大约3~5小时左右(备份时间的3-5倍); 但是,在实际生产环境中,只是误删除(误修改)了一个10M大小的数据表,如何进行部分数据信息的快速恢复; 此时需要实现部分单表数据信息恢复时,在实际企业生产环境中,并没有做指定的单表数据信息备份操作;
痛点解决思路
只能通过已有的全备数据信息,配合已有binlog日志信息,进行指定表数据信息的恢复操作;
- 基于全备数据信息,可以将指定数据表的建表语句和插入语句提取出来,进行单表数据信息恢复(恢复全备前的数据);
- 基于增量日志信息,可以将指定数据表的所有相关事件信息进行截取,进行单表数据信息增量恢复;
处理方法参考
- 基于全备数据信息,获取指定数据表的建表语句和插入语句信息
# 获取指定表的建表语句信息;
[root@db01 ~]# sed -n '/CREATE TABLE.*teacher/,/;/p' /database_backup/full_2025-09-19.sql >/database_backup/createtable.sql
# 获取指定表的插入语句信息; [root@db01 ~]# grep -i 'insert into `student`' /database_backup/full_2025-09-19.sql >/database_backup/data_insert.sql # 获取指定表的修改语句信息; [root@db01 ~]# grep -i 'update `city`' /database_backup/full_2025-09-19.sql >/database_backup/data_update.sql # 获取指定表的删除语句信息; [root@db01 ~]# grep -i 'delete from `city`' /database_backup/full_2025-09-19.sql >/database_backup/data_delete.sql
- 基于增量日志信息,获取指定数据表的增量变化的日志数据信息:
[root@db01 binlog2sql]# pwd /root/binlog2sql/binlog2sql [root@db01 binlog2sql]# python3 binlog2sql.py -h10.0.0.51 -P3306 -uroot -proot -d school -t student --start-file='mysql-bin.000014' RuntimeError: cryptography is required for sha256_password or caching_sha2_password mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root'; mysql> FLUSH PRIVILEGES;
数据库物理备份⭐⭐⭐⭐⭐
与逻辑备份相比,物理备份最大的优点是备份和恢复的速度更快(因为物理备份的原理都是基于文件的copy)
物理冷备份
冷备份其实就是停掉数据库服务,cp数据文件的方法;
物理冷备份方法对MyISAM和InnoDB存储引擎都合适,但是一般很少使用,因为很多应用是不允许长时间停机
进行备份的操作过程:
停掉MySQL服务,在操作系统级别备份MySQL的数据文件和日志文件到备份目录;
进行恢复的操作过程:
停掉MySQL服务,在操作系统级别恢复MySQL的数据文件,然后重启MySQL服务,\
使用mysqlbinlog工具恢复增量数据日志;
物理热备份
物理热备份是在数据库正常运行、不中断业务的情况下,直接拷贝数据库的物理文件来创建完整数据副本的过程
MyISAM存储引擎应用热备份
MyISAM存储引擎的热备份有很多方法,本质其实就是将要备份的表加读锁,然后再cp数据文件到备份目录
使用mysqlhotcopy工具
mysqlhotcopy是MySQL自带的一个热备份工具
[root@xiaoQ ~]# mysqlhotcopy db_name [/path/to/new_directory] -- mysqlhotcopy有很多选项,具体可以使用--help查看帮助信息
参考官方链接说明:https://dev.mysql.com/doc/refman/5.6/en/mysqlhotcopy.html
手工锁表copy
在mysqlhotcopy使用不熟悉的情况下,可以手工来做热备份,操作步骤如下:
# 对数据库中所有表加读锁: mysql> flush tables for read; -- 然后cp数据文件到备份目录即可
InnoDB存储引擎应用热备份⭐⭐⭐⭐⭐
ibbackup(收费)
ibbackup是Innobase公司的一个热备份工具,专门对InnoDB存储引擎进行物理热备份
- 步骤一:编辑用于启动的配置文件my.cnf和用于备份的配置backup-my.cnf
# 配置文件配置参考:my.cnf [mysqld] datadir=/data/3306/data innodb_data_home_dir=/data/3306/data innodb_data_file_path=ibdata1:100M;ibdata2:200M;ibdata3:500M:autoextend innodb_log_group_home_dir=/data/3306/data/ set-variable=innodb_log_files_in_group=2 set-variable=innodb_log_file_size=20M # 配置文件配置参考:backup-my.cnf [mysqld] datadir=/data/3306/backup innodb_data_home_dir=/data/3306/backup innodb_data_file_path=ibdata1:100M;ibdata2:200M;ibdata3:500M:autoextend innodb_log_group_home_dir=/data/3306/backup set-variable=innodb_log_files_in_group=2 set-variable=innodb_log_file_size=20M
- 步骤二:实现数据文件信息热备过程
[root@db01 ~]# ibbackup /data/3306/my.cnf /data/3306/backup-my.cnf ... 省略部分信息... -- ibbackup工具不会覆盖任何重名的文件,因此在新的备份开始之前,需要确保备份目录中没有重名文件,否则备份可能会失败 [root@db01 ~]# ll /data/3306/backup -- 备份成功后,备份目录下包含有数据文件和日志文件等相关数据信息;
Xtrabackup(PXB)
Xtrabackup(PXB)是Percona公司CTO Vadim参与开发的一款基于InnoDB的在线热备工具,属于物理备份数据工具; 具有开源、免费、支持在线热备、备份恢复速度快、占用磁盘空间小等特点,并且支持不同情况下的多种备份形式。 官方软件下载链接:https://www.percona.com/downloads/ 对于数据库8.0.20版本,需要使用PXB 8.0.12+以上版本,对于数据库8.0.11~8.0.19,可以使用PXB 8.0正式版本; PXB 8.0只能备份MySQL 8.0版本数据,不能备份低版本数据信息;如果想备份数据库服务低版本程序数据,需要下载使用PXB 2.4版本; xtrabackup包含两个主要的工具:xtrabackup和innobackupex xtrabackup 只能备份InnoDB和XtraDB两种类型的数据表,而不能备份MyISAM类型数据表; innobackupex 是一个封装了xtrabackup的perl脚本,支持同时备份InnoDB和MyISAM,但对MyISAM备份时需要加全局读锁; 由于PXB属于第三方软件工具程序,因此需要单独下载安装 [root@db01 ~]# ll -rw-r--r-- 1 root root 14642720 Sep 20 09:31 percona-xtrabackup-80-8.0.26-18.1.el7.x86_64.rpm [root@db01 ~]# yum install -y percona-xtrabackup-80-8.0.26-18.1.el7.x86_64.rpm -- 利用yum方式安装本地rpm包程序,可以有效解决软件依赖问题 Xtrabackup(PXB)属于物理备份工具,具体备份逻辑如下:(支持增量备份数据) 在数据库服务运行期间,通过拷贝数据文件(实质拷贝的是数据页),进而实现数据备份目的; 在进行数据文件拷贝的同时,会将备份期间的变化redo日志信息同时进行备份(拷贝);
Xtrabackup(PXB)属于物理备份工具,具体恢复逻辑如下: 在进行数据恢复时,模拟了InnoDB Crash recovery(CR)的运行过程,redo log中的内容进行回放 在进行数据恢复时,对于备份进行处理操作,特指的就是前滚操作(redo)和回滚操作(undo),从而解决数据恢复一致性问题;
Xtrabackup数据全量备份和恢复
- 全量备份操作
[root@db01 ~]# mkdir -p /data/backup/full -- 进行物理备份的目标目录不能存在数据信息,需要指定一个空目录进行备份 [root@db01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=10.0.0.51 --user=root --password=root --port=3306 --backup --target-dir=/data/backup/full -- 或者使用参数--datadir替换掉参数--defaults-file [root@db01 ~]# xtrabackup --datadir=/data/3306/data --host=10.0.0.51 --user=root --password=root --port=3306 --backup --target-dir=/data/backup/full -- backup参数表示进行全备操作 xtrabackup在线物理热备份过程 -- 进行相关数据文件、日志文件、共享表空间文件、数据表空间文件等文件的拷贝,并且拷贝过程是不会进行锁表操作的; -- 数据表空间信息备份完毕后,会有提示字段信息,并且此时会锁定binlog日志文件,并将binlog日志文件复制到备份目录; -- 在进行binlog日志文件备份时,会生成xtrabackup_binlog_info文件信息,用于记录物理备份后的二进制日志位置点; -- 二进制日志文件备份完毕后,会释放binlog日志文件锁定状态,最后验证redo日志的检查点LSN,确认备份期间所有数据也以安全刷新
[root@xiaoQ-01 backup]# ll /data/backup/full/ -- 可以看到将原有数据库的数据目录信息,已经基本迁移到指定的物理备份目录中
- Xtrabackup数据备份工具在热备操作后产生的特殊数据文件说明
| 文件名称 | 解释说明 |
|---|---|
| xtrabackup_binlog_info | 表示用于存储备份时的binlog位置点信息 |
| xtrabackup_checkpoints | 表示用于记录备份时的数据页LSN信息,主要用于接下一次备份,需要保证连续性; |
| xtrabackup_info | 表示整体物理备份信息的总览 |
| xtrabackup_logfile | 表示存储在备份数据期间产生的新的的redo日志的信息; |
| xtrabackup_tablespaces | 表示用于存储表空间的其余信息 |
- 全量备份恢复
# 模拟进行数据库数据破坏性操作 [root@db01 ~]# pkill mysqld [root@db01 ~]# cp /data/3306/data/* /data/3306/data_bak/ [root@db01 ~]# cp /data/3306/binlog/* /data/3306/binlog_bak/ [root@db01 ~]# rm -rf /data/3306/data/* [root@db01 ~]# rm -rf /data/3306/binlog/* # 进行数据库数据恢复操作 [root@db01 data]# xtrabackup --prepare --target-dir=/data/backup/full - 表示模拟CR过程,将redo日志进行前滚,undo日志进行回滚,让恢复数据信息保持一致性状态 [root@db01 data]# xtrabackup --copy-back --target-dir=/data/backup/full -- 将进行物理备份后的数据,再次进行还原恢复到备份前的目录中(拷贝回数据) [root@db01 data]# chown -R mysql.mysql /data/3306 [root@db01 ~]# /etc/init.d/mysqld start -- 重新设置数据目录权限,并重新启动恢复数据库业务
Xtrabackup数据增量备份和恢复
xtrabackup物理备份数据时,实现增量备份原理分析:
- 增量备份的实质是,基于上一次备份LSN变化过的数据页,进行相应的备份操作,从而可以不断实现增量备份操作;
- 在备份同时产生的新的变更,会将redo日志信息备份;
- 第一次增量备份时依赖于全量备份的,将来的恢复操作也要合并到全备中,再进行统一恢复;
说明:利用XPK增量备份数据,主要目的是减少频繁全备数据的时间开销,可以将每天增量的数据进行更快速的备份
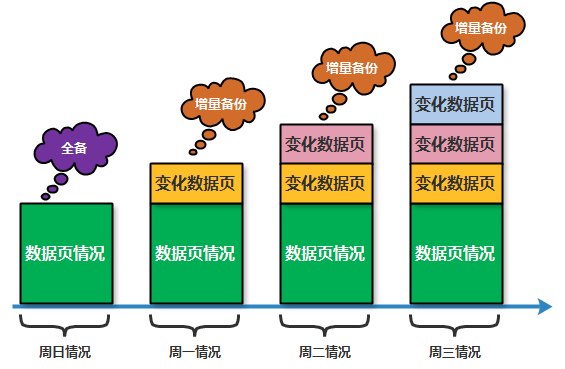
- 增量备份
# 增量备份准备: [root@db01 ~]# mkdir /data/backup/full -p -- 提前准备好全量备份的目录; [root@db01 ~]# mkdir /data/backup/inc -p -- 提前准备好增量备份的目录; # 进行备份操作: [root@db01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=10.0.0.51 \
--user=root --password=root --port=3306 --backup \
--parallel=4 --target-dir=/data/backup/full -- 进行全量备份操作,并且开启并发线程备份功能(--parallel=4),从而提高备份效率(建议4~8个)
# 模拟增量数据 mysql> create database pxb; mysql> use pxb mysql> create table t1(id int); mysql> insert into t1 values(1),(2),(3); mysql> commit;
# 进行增量备份操作 [root@db01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=10.0.0.51 \
--user=root --password=root --port=3306 --backup --parallel=4 \
--target-dir=/data/backup/inc --incremental-basedir=/data/backup/full # 进行增量备份的下一次增量备份(了解) [rootdb01 ~]# mkdir /data/backup/inc02 -p -- 提前准备好增量备份的增量备份目录; mysql> create database pxb02; mysql> use pxb02 mysql> create table t1(id int); mysql> insert into t1 values(1),(2),(3); mysql> commit;[root@db01 ~]# xtrabackup --defaults-file=/etc/my.cnf --host=10.0.0.51 \
--user=root --password=root --port=3306 --backup --parallel=4 \
--target-dir=/data/backup/inc02 --incremental-basedir=/data/backup/inc
- 增量备份恢复
# 模拟进行数据库数据破坏性操作 [root@db01 ~]# pkill mysqld [root@db01 ~]# cp /data/3306/data/* /data/3306/data_bak/ [root@db01 ~]# cp /data/3306/binlog/* /data/3306/binlog_bak/ [root@db01 ~]# rm -rf /data/3306/data/* [root@db01 ~]# rm -rf /data/3306/binlog/* # 准备相关备份日志信息 -- 准备全量备份的日志 [root@db01 ~]# xtrabackup --prepare --apply-log-only --target-dir=/data/backup/full -- 准备增量备份的日志,并且将增量备份的日志合并到全量备份的日志中 [root@db01 ~]# xtrabackup --prepare --apply-log-only \ --target-dir=/data/backup/full --incremental-dir=/data/backup/inc -- 在全量和增量数据合并后,对备份数据执行最终的事务恢复与回滚,使其达到一致性状态 [root@db01 ~]# xtrabackup --prepare --target-dir=/data/backup/full # 进行数据备份拷回操作 [root@db01 ~]# xtrabackup --datadir=/data/3306/data --copy-back --target-dir=/data/backup/full 或者 [root@db01 ~]# xtrabackup --copy-back --target-dir=/data/backup/full -- 将进行物理备份后的数据,再次进行还原恢复到备份前的目录中(拷贝回数据) # 重新启动恢复业务功能 [root@db01 ~]# chown -R mysql.mysql /data/* [root@db01 ~]# /etc/init.d/mysqld start -- 重新设置数据目录权限,并重新启动恢复数据库业务
克隆⭐⭐⭐⭐⭐
数据库克隆基础知识
克隆概念介绍
在数据库MySQL 8.0(8.0.17+)版本中,引入了数据库的克隆功能,主要是借助clone-plugin实现的,是对数据页底层克隆
(克隆插件直接复制InnoDB存储引擎最底层的物理数据文件块(页),而不是像逻辑备份那样通过SQL语句逐层导出和重建数据); 克隆的数据是InnoDB存储引擎中的物理快照信息(所有数据库、所有表和数据、表空间文件、数据字典元数据、日志、用户权限) # 数据库服务克隆作用: 在实现大量数据迁移时,克隆效率最高 实现云主机与物理主机之间数据迁移
本地克隆(Local Cloning)
本地克隆即将本机MySQL实例的数据,原地快速生成一份完整的物理副本到同节点的一个目录里
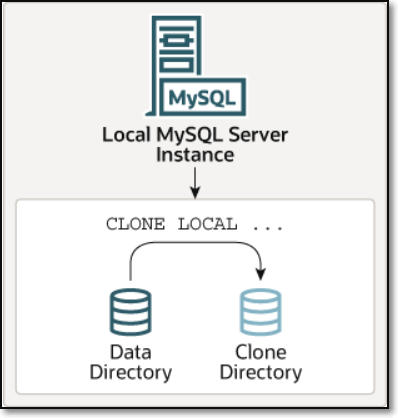
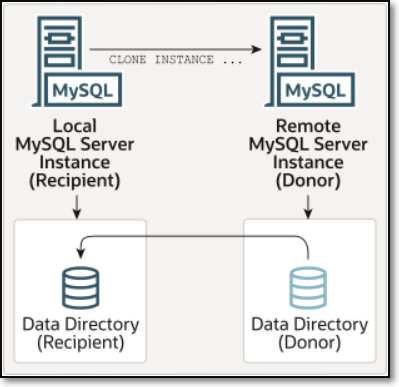
远程克隆(Remote Cloning)
- 默认的远程克隆会覆盖接受者数据目录,也可选择克隆到其他目录以避免数据丢失
- 远程克隆用于实现数据的快速热迁移。在迁移过程中,捐献者实例仅在开始时获取一个短暂的备份锁以防止DDL操作导致元数据不一致,此阶段会短暂阻塞DDL,但不会阻塞DML操作
- 远程克隆技术的作用:
- 实现快速构建数据库的主从架构环境
- 实现主从数据信息快速复制同步
数据库克隆原理⭐⭐⭐⭐⭐
- Page copy:
Page Tracking(页跟踪)的核心用途是:通过只记录和备份自上次备份后修改过的数据页,来大幅提升增量备份的速度和效率。
备份工具利用page tracking功能,获取自上次备份LSN点到本次备份开始的LSN点之间所有被修改过的数据页的列表
日志归档是将不再经常使用的历史日志数据从主存储系统迁移到更经济、安全的次级存储系统进行长期保留的过程
在进行数据页复制操作时,会涉及到两个操作动作:
开启redo archiving功能,从当前点开始存储新增的redo_log,这样从当前位置点开始所有的增量数据都不会丢失;
同时上一步在page track的page被发送到目标端,确保当前位置点之前所有做的变更一定发送到目标端;
在开始克隆前会做一次checkpoint;
对于redo archiving功能应用,会开启一个后台线程log_archiver_thread()来做日志归档;
当有新的写入时(notify_about_advanced_write_lsn),也会通知线程去进行归档,
当arch_log_sys(日志归档系统)处于活跃状态时,
线程会控制日志写入以避免未归档的日志被覆盖(log_write_wait_on_archiver),
注意如果log_write等待时间过长的话,archive任务会被中断掉;
- Redo copy:
停止redo archiving功能,所有归档的日志被发送到目标端,这些日志包含了从page copy阶段开始到现在的所有日志;
另外可能还需要记下当前的复制点,例如:最后一个事务提交时的binlog位置点或者gtid信息,在系统页中可以找到;
- Done:
目标端重启实例,通过crash recovery将redo log应用上去;
克隆原理过程分析参考链接:https://zhuanlan.zhihu.com/p/437760913
说明:整个克隆过程都会以事件信息记录,可以很清晰的看到克隆的流程,如果克隆过程中断,也会以追加方式进行继续克隆;
在进行克隆功能应用时,也是存在一些限制性操作的:(结合官方列出的限制)
-
对于MySQL 8.0.27之前版本,在进行克隆操作期间,是不允许在捐赠者和接受者上进行DDL操作,包括:truncate table操作;
对于MySQL 8.0.27之后版本,在捐赠者上默认允许并发DDL操作,对于捐赠者上并发DDL的支持由clone_block_DDL变量控制;
-
对于不同版本的MySQL数据库实例之间,是不能进行克隆操作的。对于捐赠者和接受者必须是确切相同数据库服务版本;
例如:你不能克隆数据在between MySQL 5.7 and MySQL 8.0, or between MySQL 8.0.19 and MySQL 8.0.20;
这个克隆功能只支持在数据库8.0.17版本或之后的版本
参考官方链接说明:https://dev.mysql.com/doc/refman/8.0/en/clone-plugin-limitations.html
数据库克隆功能实战⭐⭐⭐⭐⭐
加载克隆插件
-- 进行克隆插件加载配置 -- 临时加载 mysql> INSTALL PLUGIN clone SONAME 'mysql_clone.so'; install plugin:动态安装一个服务器插件 clone:给这个插件起的内部名称,mysql将通过这个名字来识别和管理这个插件 SONAME 'mysql_clone.so':指定MySQL克隆插件在服务器磁盘上对应的动态链接库文件名 -- 永久加载 [mysqld] plugin-load-add=mysql_clone.so clone=FORCE_PLUS_PERMANENT -- 查看克隆插件加载情况 mysql> select plugin_name,plugin_status from \
information_schema.plugins where plugin_name='clone'; +-------------+---------------+ | plugin_name | plugin_status | +-------------+---------------+ | clone | ACTIVE | +-------------+---------------+ -- 创建克隆专用用户 mysql> create user clone_user@'%' identified by 'password'; mysql> grant backup_admin on *.* to 'clone_user'; backup_admin权限是mysql8.0才有的备份导出的权限
本地克隆操作
克隆需求:实现快速创建和源数据库服务一模一样的多实例服务程序
- 步骤一:进行本地克隆操作
[root@db01 ~]# mkdir -p /mysql_clone/ [root@db01 ~]# chown -R mysql:mysql /mysql_clone/ [root@db01 ~]# mysql -uclone_user -ppassword mysql> clone local data directory='/mysql_clone/local';
- 步骤二:观测本地克隆状态(另开窗口使用管理员用户查看)
mysql> select stage,state,end_time from performance_schema.clone_progress; +-----------+-------------+----------------------------+ | stage | state | end_time | +-----------+-------------+----------------------------+ | DROP DATA | Completed | 2025-09-14 14:57:35.861065 | | FILE COPY | Completed | 2025-09-14 14:57:38.288616 | | PAGE COPY | Completed | 2025-09-14 14:57:38.290706 | | REDO COPY | Completed | 2025-09-14 14:57:38.291421 | | FILE SYNC | Completed | 2025-09-14 14:57:39.450835 | | RESTART | Not Started | NULL | | RECOVERY | Not Started | NULL | +-----------+-------------+----------------------------+
远程克隆操作
- 步骤一:克隆操作环境准备
# 在克隆接受者主机上清理数据库服务环境 [root@db01 ~]# pkill mysqld [root@db01 ~]# rm -rf /data/3307/data/* # 在克隆接收者主机上进行实例初始化操作: [root@db01 ~]# mysqld --initialize-insecure --user=mysql \ --basedir=/usr/local/mysql --datadir=/data/3307/data # 将捐赠者主机的配置文件进行复制并修改 [root@db01 ~]# cat my.cnf [mysql] socket=/tmp/mysql3307.sock [mysqld] user=mysql port=3307 basedir=/usr/local/mysql datadir=/data/3307/data socket=/tmp/mysql3307.sock innodb_data_file_path=ibdata1:12M;ibdata2:10M:autoextend server_id=6 log_bin=/data/3307/binlog/mysql-bin -- 切记创建binlog目录并设置权限 gtid_mode=on enforce_gtid_consistency=1 log_slave_updates=on # 在克隆接收者主机上进行实例的运行操作 mysqld_safe --defaults-file=/data/3307/my.cnf &
- 步骤二:加载克隆插件信息
# 捐赠者和接收者上都进行安装 mysql> INSTALL PLUGIN clone SONAME 'mysql_clone.so'; 或者 [mysqld] plugin-load-add=mysql_clone.so clone=FORCE_PLUS_PERMANENT # 查看克隆加载情况 mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME = 'clone';
- 步骤三:创建克隆专用用户
backup_admin:授予用户执行物理备份相关操作的权限
clone_admin:授予用户在其所在的mysql实例上执行和管理克隆操作的权限
-- 给捐赠者主机授权 mysql> create user clone_jz@'%' identified by 'password'; mysql> grant backup_admin on *.* to clone_jz@'%'; 因为捐赠者的核心工作是生成一份底层数据快照并提供给接收者,\
这本质是一个物理备份过程,因此需要授予其 backup_admin 权限来执行相关的备份操作 -- 给接收者主机授权 mysql> create user clone_js@'%' identified by 'password'; mysql> grant clone_admin on *.* to clone_js@'%';
说明:可以在克隆捐赠者主机上和接收者主机上均创建两个用户信息,防止克隆同步数据后,接收者主机上不再含有接收用户信息;
- 步骤四:进行远程克隆操作
clone_valid_donor_list 是一个用于配置克隆“信任白名单”的安全参数,它指定了接收者(Recipient)可以从哪些捐赠者(Donor)实例克隆数据
# 在接收者主机上设置信任白名单参数 mysql> set global clone_valid_donor_list='10.0.0.51:3306'; # 在接收者主机上进行远程克隆 [root@db01 ~]# mysql -uclone_js -ppassword -h10.0.0.51 -P3307 mysql> clone instance from clone_jz@'10.0.0.51':3306 identified by 'password'; # 观测本地克隆状态(切换到root用户进行查看) mysql> select stage,state,end_time from performance_schema.clone_progress; -- 当克隆数据量比较大的时候,可以使用此SQL语句进行克隆状态查看,在克隆接收者主机上进行查看 mysql> show databases; -- 此时克隆接收者主机上查看到的数据信息,与克隆捐赠者主机上查看到的数据信息一致,即远程克隆操作完成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号