


数据库服务语句应用(基础)
mysql默认四张库⭐⭐⭐⭐
| 数据库名称 | 类型 | 主要作用 | 关键特性 |
|---|---|---|---|
| information_schema | 元数据库 | 提供所有数据库对象的元数据视图 (表/列/索引等结构信息) |
• 只读虚拟数据库 • 数据实时从内存生成 • 符合SQL标准 |
| mysql | 权限库 | 存储用户权限、密码、存储过程等核心安全数据 | • 使用MyISAM引擎(8.0+部分表改用InnoDB) • 直接修改高风险 • 密码字段5.7+采用caching_sha2加密 |
| performance_schema | 性能库 | 采集服务器事件和性能指标 (SQL执行/锁/连接等微观数据) |
• 零存储开销设计 • 可配置监控粒度 • 提供500+监控指标 |
| sys | 诊断库 | 基于performance_schema的友好视图 (提供DBA友好的性能诊断报告) |
• 完全由视图和存储过程构成 • 8.0+默认安装 • 支持标准化性能分析 |
SQL( Structured Query Language ):结构化查询语言
SQL语句几种常用的标准:SQL89 / SQL 92 / SQL 99 / SQL 03
DDL Data Definition Language(数据定义语言)
专门用于定义和管理数据库结构及组成:增删库、增删表、增删索引、增删用户
主要涉及语句:CREATE、ALTER、DROP
查看DDL语言负责的操作行为:mysql> ? Data Definition;
DCL Data Control Language(数据控制语言)
主要用来定义访问权限和安全级别
主要涉及语句:GRANT(用户授权)、REVOKE(权限回收)、COMMIT(提交)、ROLLBACK(回滚)
查看DCL语言负责的操作行为:mysql> ? Account Management;
DML Data Manipulation Language(数据操作语言)
主要针对数据库里的表里的数据进行操作
主要涉及语句:SELECT、INSERT、DELETE、UPDATE
查看DML语言负责的操作行为: mysql> ? Data Manipulation;
数据库字符编码设置
常见的字符编码
ASCII码:1个字节(8位⼆进制)来表示⼀个字符,共可以表示2^8=256个字符
GBK:2个字节(16位二进制)来表示一个字符,共可以表示2^16=65536个字符
Unicode编码:4个字节(32位二进制)来表示一个字符(造成空间的极大浪费)
UTF-8(Unicode Transform Format)编码:1~4个字节(8位~32位二进制)来表示一个字符
MySQL服务的字符编码相关系统变量⭐⭐⭐⭐
# 显示mysql服务支持的所有字符集及其描述信息 mysql> show charset; +----------+---------------+---------------------+-----------------------------+ | Charset | Description | Default collation | Maxlen | | 字符集名称 | 字符集描述 | 字符集默认排序规则 | 单个字符占用的最大字节数 | +----------+-------------- -+---------------------+----------------------------+ # 显示当前MySQL服务的字符编码相关系统变量 mysql> show variables like '%character%'; character_set_server: 服务器默认字符集(新建数据库时使用) character_set_database: 当前数据库的默认字符集 character_set_client: 客户端发送SQL语句使用的字符集 character_set_connection: 服务器接收SQL语句后转换的字符集 character_set_results: 服务器返回结果使用的字符集 character_set_filesystem: 文件系统字符集(通常为binary) character_set_system: MySQL内部元数据存储使用的字符集(固定为utf8) # utf8和utf8mb4之间有什么区别 两种字符集的字符存储量不同 utf8:最多存储3字节长度字符(张--3字节) utf8mb4:最多存储4字节长度字符(emoji表情--4字节、张--3字节)
字符集转换流程⭐⭐
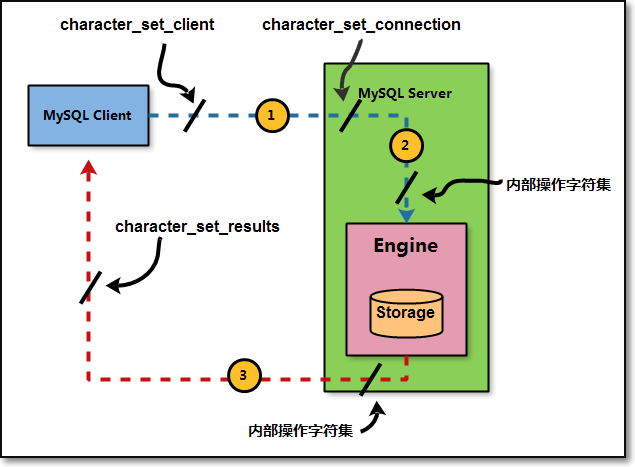
# 01.mysql Server收到请求时将请求数据从 character_set_client 转换为 character_set_connection; # 02.进行内部操作前将请求数据从 character_set_connection 转换为内部操作字符集; 使用每个数据字段的 CHARACTER SET 设定值; 若上述值不存在,则使用对应数据表的字符集设定值; 若上述值不存在,则使用对应数据库的字符集设定值; 若上述值不存在,则使用 character_set_server 设定值; # 03.最后将操作结果从内部操作字符集转换为 character_set_results
数据库字符集永久配置⭐⭐
# 编辑修改服务配置文件参数信息my.cnf(全局设置) [mysqld] character-set-server=utf8mb4 # 服务器默认字符集 collation-server=utf8mb4_unicode_ci # 服务器默认排序规则 [client] default-character-set=utf8mb4 # 所有客户端连接的默认字符集 [mysql] default-character-set=utf8mb4 # mysql命令行客户端字符集
数据已存在的据库服务字符编码信息调整方法⭐⭐⭐⭐
# 假设数据库表原有字符集为gbk,并且已经存储数据了,需要将表和数据字符集进行调整转换utf8mb4 # 方法一: mysql > alter table t1 charset utf8mb4; 不严谨的方法,只会影响之后存储的数据,不会修改之前存储的数据 # 方法二: 锁表逻辑导出数据(例如:mysqldump) 重新创建数据空表(设置目标字符集) 导入备份数据信息 -- 严谨的方法,可以影响之后存储的数据,也会修改之前存储的数据 -- 字符集转换是可以的,但是必须保证修改后的字符集是修改前的严格超集(包含)
字符编码校对规则(排序规则)⭐⭐
在查询数据信息时,影响数据信息的查询输出和排序效果(字符比较是按照字符编码还是对应的二进制数进行比较);
utf8mb4字符集中常用的排序规则:utf8mb4_unicode_ci、utf8mb4_general_ci、utf8mb4_bin
| 排序规则后缀 | 解释说明 |
|---|---|
| _ci | 不区分大小写,Case-insensitive的缩写 |
| _cs | 区分大小写,Case-sensitive的缩写 |
| _ai | 不区分重音,Accent-insensitive的缩写 |
| _as | 区分重音,Accent-sensitive的缩写 |
| _bin | 采用二进制方式存储数据信息 |
数据库/表 字符集/校验规则 的创建和修改⭐⭐
-- 创建新数据库/表时指定字符集、校验规则 create database 库名 charset 字符集 collate 校验规则; create table 表名(字段名 类型) charset 字符集 collate 校验规则; -- 修改数据库或表的字符集、校验规则 alter database 库名 charset 新的字符集 collate 新的校验规则 alter table 表名 charset 新的字符集 collate 新的校验规则名;
数据类型、约束条件、属性
数据类型
| 数字类型 | 整型(数字/整数) |
int:普通整型数字(1字节) tinyint:微小整型数字(4字节) bigint:超大整型数字(8字节) |
| 浮点(数字/小数) |
float:单精度浮点数 double:双精度浮点数 decimal:定点数 |
|
| 字符串类型 | 字符(字符/符号/整数) |
char(0~255):定长字符类型 varchar(0~65535):变长字符类型 enum:枚举类型 set:集合类型 text:大文本类型 |
| 时间类型 | 时间类型 |
date:日期类型 time:时间类型 datetime:日期时间类型(1000~9999)占8字节 timestamp:时间戳类型(1970~2038)格林威治时间 占4字节 |
| 二进制类型 | 二进制类型 | |
| json类型 | json类型 |
详细的数据类型知识参考链接:https://m.php.cn/article/460317.html
常见的约束定义⭐⭐⭐
| 约束方法 | 解释说明 |
|---|---|
| PK(primary key) | 表示主键约束,非空且唯一(表中只能有一个主键) |
| UK(unique key) | 表示唯一约束 |
| NN(not null) | 表示非空约束 |
| FK(foreign key) | 表示外键约束,多表之间关联使用 |
常见的属性定义⭐⭐⭐
| 属性信息 | 解释说明 |
|---|---|
| default | 设定默认数据信息,可以实现自动填充 |
| auto_increment | 设定数值信息自增,可以实现数值编号自增填充(一般配合主键使用) |
| comment | 设定数据注释信息 |
| unsigned | 设定数值信息非负,可以实现数值信息列不能出现负数信息 |
外键foreign key⭐⭐⭐⭐⭐
外键字段必须与引用表(父表主键)的数据类型严格保持一致
外键不能被修改,只能先删除再新增
创建外键⭐⭐⭐
方法一:在创建表的时候就增加外键: 在表字段之后使用foreign key
foreign key(外键字段) references 主表(主键); -- 创建外键关联的父表 create table class( id int primary key auto_increment, name varchar(10) not null comment "班级名字,不能为空", room varchar(10) comment '教室:允许为空' ) charset utf8; -- 创建子表使用外键 create table student( id int primary key auto_increment, number char(10) not null unique comment "学号:不能重复", name varchar(10) not null comment "姓名", c_id int, foreign key(c_id) references class(id) ) charset utf8; -- 查看外键是否配置成功 show create table class; show create table student;
方法二:在创建表之后添加外键
alter table 表名 add constraint 外键名 foreign key(外键字段) references 父表(主键字段); -- 创建没有外键信息的表 create table t_foreign( id int primary key auto_increment, c_id int )charset utf8; -- 在没有外键的表中添加字段 alter table t_foreign add constraint class_foreign foreign key(c_id) references class(id);
设置删除外键⭐⭐
-- 删除外键语法格式 alter table 表名 drop foreign key 外键名; -- 删除表(t_foreign)中外键信息 alter table t_foreign drop foreign key class_foreign;
外键约束说明
约束01:外键对子表的数据写操作约束(增加和更新)
如果子表中插入的数据所对应的外键在父表不存在,创建不能成功.

约束02:外键对父表也有数据约束
当父表操作一个记录,但是该记录被子表所引用的时候,那么父表的操作将会被限制(更新: 主键和删除)

数据库数据模式(SQL_mode)⭐⭐
SQL_mode用于设置MySQL服务器的工作模式,控制SQL语法校验规则和数据校验的严格程度,确保SQL语句的执行符合预期标准
例如:日期信息不能出现 0000-00-00 信息,月份只能是1-12,日期只能是1-31,一旦违反常识便会报错;
例如:在进行数据运算时,除法运算时,除数不能为0;
例如:当定义数据类型为char(10),不能超过字符长度,超过长度就报错;
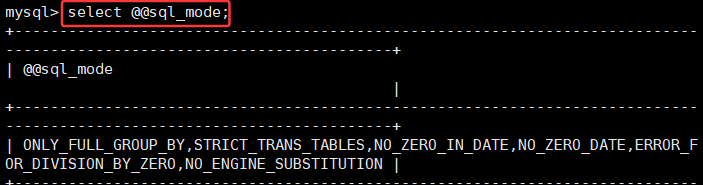
当进行数据库服务版本升级时,可能之前版本数据信息不能满足新版本数据库服务的SQL_mode信息设定,需要暂时设置SQLmode为空 mysql> set global sql_mode=''; -- 配置完毕后,可以重新登录数据库服务进行检查确认
SQL_mode配置参数信息
| 模式参数配置 | 解释说明 |
|---|---|
ONLY_FULL_GROUP_BY |
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中。 |
| STRICT_TRANS_TABLES | 在该模式下,如果一个值不能插入到一个事物表中,则中断当前的操作,对非事物表不做限制 |
NO_ZERO_IN_DATE |
在严格模式下,不允许日期和月份为零 |
NO_ZERO_DATE |
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告 |
ERROR_FOR_DIVISION_BY_ZERO |
在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时MySQL返回NULL |
| NO_ENGINE_SUBSTITUTION | 如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常 |
| NO_AUTO_VALUE_ON_ZERO | 该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户希望插入的值为0,该列又是自增长的,那么这个选项就有用了。 |
| NO_AUTO_CREATE_USER | 禁止GRANT创建密码为空的用户 |
| PIPES_AS_CONCAT | 将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样的,也和字符串的拼接函数Concat相类似 |
| ANSI_QUOTES | 启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符 |
数据库服务语句应用(实践)
数据库帮助标签
-- 基本帮助标签 mysql > \h mysql > help -- 分类帮助标签 mysql > help contents mysql > ? contents -- 语句级帮助标签 mysql > help create database mysql > ? create database
DDL:数据定义语言⭐⭐⭐⭐⭐
数据库相关操作⭐⭐⭐⭐
-- 创建数据库 create <database/schema> 数据库名 <character set/charset> 字符编码 collate 字符编码校验规则; -- 修改数据库信息 alter database 数据库名 charset 字符编码 collate 字符编码校验规则; -- 查看数据库信息 show databases; -- 查看所有数据库信息 show databases like '%yuan%'; -- 检索查看指定的数据库信息 show create database 数据库名; -- 查看数据库语句信息 -- 删除数据库信息 drop <database/schema> 数据库名; -- 切换数据库 use 数据库名; select database(); -- 查看当前所在数据库信息
定义数据库规范说明:
- 创建数据库名称规范:要和业务有关,不要有大写字母(为了多平台兼容),不要数字开头,不要含有系统关键字信息;
- 创建数据库明确字符:创建数据库时明确(显示)的设置字符集信息,为了避免跨平台兼容性与不同版本兼容性问题;
- 删除数据库操作慎用:在对数据库进行删除操作时,一定要经过严格审计后再进行操作,并且数据库普通用户不能有drop权限;
数据表相关操作⭐⭐⭐⭐
- 创建表
create table <表名> (<字段名1> <类型1> ,<字段名n> <类型n>);
- 查看表
show tables; -- 查看数据库所有的表信息 desc 表名; -- 查看数据库中指定表数据结构信息 show create table 表名; -- 查看数据库中指定表创建语句信息
- 修改表
-- 修改表属性信息 -- 修改数据表名 rename table 旧表名 to 新表名; alter table 旧表名 rename 新表名; -- 修改表编码信息 alter table 表名 charset 字符编码; -- 修改表结构信息 -- 数据表中添加新的表结构字段 alter table <表名> add column <字段名称> <数据类型> <约束与属性> [comment '注释'] [选项参数]; -- 插入字段微信号到student表中的age字段之后 alter table student add column wechat varchar(64) not null unique key comment '微信号' after age; -- 插入字段手机号到student表中最前列(默认追加) alter table student add column telephone varchar(11) not null unique key comment '手机号' first;
-- 数据表中修改已有表结构字段(数据类型 约束与属性) alter table <表名> modify column <字段名称> <数据类型> <约束与属性> [comment '注释'] [选项参数]; -- 修改数据表已有表结构字段(字段名称 数据类型 约束与属性) alter table <表名> change column <旧字段名称> <新字段名称> <数据类型> <约束与属性> [comment '注释'] [选项参数]; -- 数据表中删除已有表结构字段 alter table <表名> drop column <字段名称>; -- 删除数据表中已有表结构字段(约束与属性) alter table <表名> drop index <字段名称> ;
- 删除表
drop table <表名>;
定义数据表规范说明:
-
创建数据表名称规范:要和业务有关(含库前缀),不要有大写字母,不要数字开头,不要含有系统关键字信息,名称不要太长;
-
创建数据表属性规范:属性信息显示设置,引擎选择InnoDB,字符集选择utf8/utf8mb4,表信息添加注释;
-
创建数据列属性规范:名称要有意义,不要含有系统关键字信息,名称不要太长;
-
创建数据类型的规范:数据类型选择合适的、足够的、简短的;
-
创建数据约束的规范:每个表中必须都要有主键,最好是和业务无关列,实现自增功能,建议每个列都非空(避免索引失效)/加注释
-
删除数据表操作规范:对于普通用户不能具有删表操作,需要操作删表时需要严格审核
-
修改数据表结构规范:在数据库8.0之前,修改数据表结构需要在业务不繁忙时进行,否则会产生严重的锁
如果出现紧急修改表结构信息需求时,可以使用工具进行调整,比如使用:pt-osc、gh-ost,从而降低对业务影响
数据库面试题⭐⭐⭐
请查看以下建表语句给出规范和优化建议:(物流公司日常工作表信息)


create table 't_area_distribution_cost' ( 'id' bigint(20) not null auto_increment comment '主键', 'city_id' varchar(200), 'city_name' varchar(200), 'warehouse_id' varchar(200), 'warehouse_name' varchar(200) , 'station_region_id' varchar(200), 'station_region_name' varchar(200), 'replenish_type' varchar(200), 'distribution_cost' varchar(200), 'c_t' varchar(200) default '0' comment '创建时间', 'create_user' varchar(200) default '0' comment '创建人ID', 'creater' varchar(200) comment '创建人', 'u_t' varchar(200) default '0' comment '修改时间', 'update_user' varchar(200) default '0' comment '修改人ID', 'updater' varchar(200), 'is_deleted' varchar(200) comment '删除标记(1 ,删除;0,不删除,有效)', primary key ('id'), key 'i_abc_city_id' ('city_id') comment '城市ID索引', key 'i_abc_warehouse_id' ('warehouse_id'), key 'i_abc_station_region_id' ('station_region_id') ) ENGINE=innodb default charset=utf8 comment='区域配送运费设置';
# 修改建议01:表明信息略长可以进行调整 create table 't_area_distribution_cost' # 修改建议02:数据类型信息设定尽量合适 'city_id' varchar(200), 'city_name' varchar(200), # 修改建议03:定义索引信息没有设置非空 'city_id' varchar(200), 'warehouse_id' varchar(200), 'station_region_id' varchar(200), # 修改建议04:表中字段列信息可以加注释 'city_id' varchar(200), 'city_name' varchar(200), 'warehouse_id' varchar(200), 'warehouse_name' varchar(200) , 'station_region_id' varchar(200),
研发同学需要紧急上线,需要DBA审核SQL,请问以下语句需要如何评估后上线执行,请写审核SQL要点
alter table t_enter_cooperate_info add account_day INT not null default 0 comment '账期天数', alter table t_enter_cooperate_info add account_detay_day INT not null default 0 comment '账期付款天数', alter table t_pop_basic add account_day INT not null default 0 comment '账期天数', alter table t_pop_basic add account_detay_day INT not null default 0 comment '账期付款天数'
问题解答分析: 本身语句是没有任何问题的,但需要说明,尽量业务繁忙时不要进行发布,选择夜里业务不繁忙时进行发布; 通过对以上SQL语句信息解读,可以看出语句操作属于DDL操作,线上操作DDL语句可能会产生比较严重的锁进制等待(死锁问题); 可以结合企业的数据业务存储的负载压力(TPS),可能当前时间段的TPS数值较高,原则上不建议进行线上操作; 但是考虑到业务需求的紧急情况,建议使用PT-osc工具进行数据库线上操作,减少对线上业务的影响,但不能提高操作效率;
DML:数据管理语言⭐⭐⭐⭐⭐
-- insert:数据表数据插入命令语法
insert into <表名> [( <字段名1>[,..<字段名n > ])] values ( 值1 )[, ( 值n )];
-- update:数据表数据修改命令语法
update 表名 set 字段=新值,… where 条件;
-- delete:数据表数据删除命令语法 delete from 表名 where 表达式; -- 如果不加条件会逐行删除表数据
禁止修改命令(update/delete)不加条件信息执行命令⭐⭐⭐
- 修改后命令生效条件
-- WHERE 子句使用主键或索引列 DELETE FROM 表名 WHERE 主键列 = 值; DELETE FROM 表名 WHERE 索引列 = 值; -- 使用 LIMIT 子句(即使没有索引) DELETE FROM 表名 WHERE 条件 LIMIT 行数;
- 服务端
# 方法1:临时执行 set global sql_safe_updates=1; # 退出重新登陆生效 # 方法2:永久生效 [root@db01 ~]# vi /etc/my.cnf [mysqld] init-file=/opt/init.sql # init-file:用于指定一个包含 SQL 语句的文件,该文件会在 MySQL 服务器启动时自动执行 # 新建脚本 echo 'set global sql_safe_updates=1;' >/opt/init.sql chmod +x /opt/init.sql /etc/init.d/mysqld restart # 检验 [root@db01 ~]# mysql -uroot -proot -e "select @@global.sql_safe_updates"
- 客户端
# 方法一:将sate_updates=1加入到my.cnf的client标签下 # 方法2:设置数据库别名操作方式 alias mysql='mysql -U' U --safe-updates Only allow UPDATE and DELETE that uses keys 表示以安全更新模式登录数据库,并放入/etc/profile永久生效
伪删除(本质:利用update代替delete)⭐⭐⭐
伪删除是通过更新状态字段标记数据为"删除"状态,而非物理删除数据,从而保留数据可恢复性的技术手段
-- 在原有表中添加新的状态列 alter table student add column state tinyint not null default 1; -- 将要删除的信息的状态改为0,实现伪删除效果 update student set state=0 where id=1; -- 实现查询时不要获取状态为0的信息,即不查看获取伪删除数据信息 select * from student where state=1;
drop/truncate/delete 三者区别⭐⭐⭐⭐⭐
| 区别分析 | drop table 表名; | truncate table 表名; | delete from 表名; |
|---|---|---|---|
| 功能效果 | 删除表结构+数据 | 删除表数据(释放空间) | 删除表数据(标记删除) |
| 删除逻辑 | 彻底删除 | 物理删除(段区页层面删除) | 逻辑删除(逐行删除) |
| 删除效率 | 效率快(和数据量无关) | 效率快(和数据量无关) | 效率慢(和数据量有关) |
| 自增影响 | 新增自增序列 | 重置自增序列(释放高水位线) | 延续自增序列 |
| 数据恢复 | 利用日志文件恢复 | 利用备份恢复/延时从库恢复 | 利用日志文件恢复(快速) |
自增列信息值调整方法:alter table 表名 auto_increment=10;
DQL:数据库查询语言⭐⭐⭐⭐
查询服务配置信息
查询获取信息命令语法
mysql> select @@配置参数信息; mysql> show variables like '检索的配置信息';
数据库服务在线调整配置参数方法
-- 表示在线临时调整配置参数,并且只是当前会话生效(session是默认方式,不是所有配置都可以调整) mysql > set session innodb_flush_log_at_trx_commit=1 mysql > set sql_log_bin=0; -- 表示在线临时调整配置参数,并且将会影响所有连接(global是全局方式,可以进行所有配置调整) mysql > set global innodb_flush_log_at_trx_commit=1 -- 数据库服务配置参数在线调整参数,只是临时生效,数据库服务重启后配置会失效,想要永久生效需要修改配置文件信息
获取函数输出信息(concat)
mysql> select concat(user,"@","'",host,"'") from mysql.user; +-------------------------------+ | concat(user,"@","'",host,"'") | +-------------------------------+ | root@'172.16.1.%' | +-------------------------------+
单表查询⭐⭐⭐
# 数据表数据查询命令语法 select <字段1,字段2,...> from <表名> [WHERE 条件] group by <字段1,字段2,...> \
having 条件 order by 字段 limit 限制信息;
- 测试文件下载地址:https://dev.mysql.com/doc/index-other.html
- -- 将world.sql数据库文件上传到数据库服务器中,根据存储路径进行加载恢复数据库数据
- mysql> source ~/world-db/world.sql
区间条件表示方法
| 符号 | 解释说明 |
|---|---|
| < | 表示小于指定数值的信息作为条件 |
| > | 表示大于指定数值的信息作为条件 |
| <= | 表示小于等于指定数值的信息作为条件 |
| >= | 表示大于等于指定数值的信息作为条件 |
| != / <> | 表示不等于指定数值的信息作为条件 |
逻辑判断符号
| 逻辑判断符号 | 解释说明 |
|---|---|
| and(并且)/ && | 表示多个条件均都满足才能被查找出来 |
| or(或者)/ || | 表示多个条件之一满足就能被查找出来 |
| not (取反) / ! | 表示查找除过滤查找的信息以外的内容 |
like、in、not in、between and、distinct、is null、is not null
# 查询国家代号是CH开头的城市信息 mysql> SELECT * FROM city WHERE countrycode LIKE 'CH%'; # 查询中国和美国的所有城市 mysql> SELECT * FROM city WHERE countrycode in ('CHN','USA'); # 查询世界上的所有城市信息,但排除中国和美国的城市不查询 mysql> SELECT * FROM city WHERE countrycode not in ('CHN','USA'); # 查询人口数量在50w-100w之间的城市信息 mysql> SELECT * FROM city WHERE population between 500000 and 10000000; # 查询city表中所有CountryCode为'USA'的城市,并返回去重后的CountryCode列表 mysql> select Distinct CountryCode from city where CountryCode='USA'; # 查询国家编码字段为非空和空的信息 mysql> select * from city where CountryCode not null; mysql> select * from city where CountryCode is null;
聚合函数
| 函数信息 | 解释说明 |
|---|---|
| count() | 此函数表示对数量信息进行统计 |
| sum() | 此函数表示对数值信息进行求和 |
| avg() | 此函数表示对数值信息进行求平均值 |
| min() | 此函数表示对数值信息进行取最小值 |
| max() | 此函数表示对数值信息进行取最大值 |
| group_concat() | 此函数表示输出信息无法匹配分组和聚合函数时,进行拼接整合显示 |
| distinct | 此指令表示作用是对表中的单个字段或多个字段去重操作 |

select+from+where+group by+聚合函数+having+order by+limit # 查询统计每个国家的人口总数,只显示人口数量超过5千万的信息,并且按照国家人口总数从大到小排序,只显示前三名 mysql > select countrycode,sum(population) from world.city group by countrycode having sum(population)>50000000 order by sum(population) desc limit 3; mysql > select countrycode,sum(population) from world.city group by countrycode having sum(population)>50000000 order by sum(population) desc limit 0,3; mysql > select countrycode,sum(population) from world.city group by countrycode having sum(population)>50000000 order by sum(population) desc limit 3 offset 0; # 查询统计每个国家的人口总数,只显示人口数量超过5千万的信息,并且按照国家人口总数从大到小排序,只显示三~五名 mysql > select countrycode,sum(population) from world.city group by countrycode having sum(population)>50000000 order by sum(population) desc limit 2,3; mysql > select countrycode,sum(population) from world.city group by countrycode having sum(population)>50000000 order by sum(population) desc limit 3 offset 2; -- 跳过前2名,显示后面的三名数据信息
多表查询⭐⭐⭐
查询命令语法格式
# 笛卡尔乘积连接多表: select * from t1,t2; # 内连接查询多表(两个表中有关联条件的行显示出来) select * from t1,t2 where t1.列=t2.列; select * from t1 [inner] join t2 on t1.列=t2.列; # 外连接查询多表:左外连接 select * from t1 left join t2 on t1.列=t2.列; # 外连接查询多表:右外连接 select * from t1 right join t2 on t1.列=t2.列;
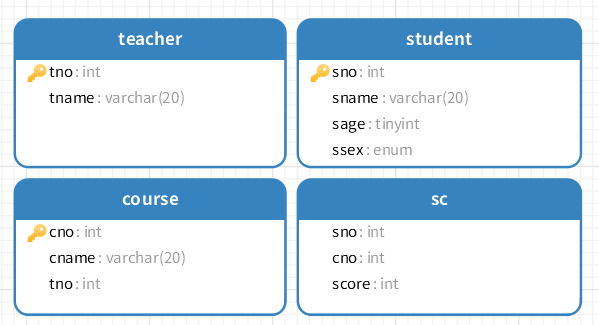
测试环境
CREATE DATABASE school CHARSET utf8;
CREATE TABLE student ( sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号', sname VARCHAR(20) NOT NULL COMMENT '姓名', sage TINYINT UNSIGNED NOT NULL COMMENT '年龄', ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别' ) ENGINE=INNODB CHARSET=utf8; INSERT INTO student(sno,sname,sage,ssex) VALUES (1,'zhang3',18,'m'), (2,'zhang4',18,'m'), (3,'li4',18,'m'), (4,'wang5',19,'f'), (5,'zh4',18,'m'), (6,'zhao4',18,'m'), (7,'ma6',19,'f'), (8,'oldboy',20,'m'), (9,'oldgirl',20,'f'), (10,'oldp',25,'m');
CREATE TABLE course ( cno INT NOT NULL PRIMARY KEY COMMENT '课程编号', cname VARCHAR(20) NOT NULL COMMENT '课程名字', tno INT NOT NULL COMMENT '教师编号' ) ENGINE=INNODB CHARSET=utf8; INSERT INTO course(cno,cname,tno) VALUES (1001,'linux',101), (1002,'python',102), (1003,'mysql',103), (1004,'go',105);
CREATE TABLE sc ( sno INT NOT NULL COMMENT '学号', cno INT NOT NULL COMMENT '课程编号', score INT NOT NULL DEFAULT 0 COMMENT '成绩' ) ENGINE=INNODB CHARSET=utf8; INSERT INTO sc(sno,cno,score) VALUES (1,1001,80), (1,1002,59), (2,1002,90), (2,1003,100), (3,1001,99), (3,1003,40), (4,1001,79), (4,1002,61), (4,1003,99), (5,1003,40), (6,1001,89), (6,1003,77), (7,1001,67), (7,1003,82), (8,1001,70), (9,1003,80), (10,1003,96);
CREATE TABLE teacher ( tno INT NOT NULL PRIMARY KEY COMMENT '教师编号', tname VARCHAR(20) NOT NULL COMMENT '教师名字' ) ENGINE=INNODB CHARSET=utf8; INSERT INTO teacher(tno,tname) VALUES (101,'oldboy'), (102,'xiaoQ'), (103,'xiaoA'), (104,'xiaoB');
案例
# 利用内连接显示teacher和course表中相关联的信息 mysql> select * from teacher [inner] join course on teacher.tno=course.tno; # 利用左外连接显示teacher和course表中相关联的信息 mysql> select * from teacher left join course on teacher.tno=course.tno; # 利用右外连接显示teacher和course表中相关联的信息 mysql> select * from teacher right join course on teacher.tno=course.tno; # 统计zhang3,学习了几门课? mysql> select student.sname,count(*) from student \ join sc on student.sno=sc.sno \ where student.sname='zhang3';
# 查询zhang3,学习的课程名称有哪些? mysql> select student.sname,group_concat(course.cname) from student \ join sc on student.sno=sc.sno join course on sc.cno=course.cno \ where student.sname='zhang3'; # 查询xiaoA老师教的学生名 mysql>select teacher.tname,group_concat(student.sname) from teacher \ join course on teacher.tno=course.tno join sc on course.cno=sc.cno join student on sc.sno=student.sno \ where teacher.tname='xiaoA' group by teacher.tno;
# 查询xiaoA老师教课程的平均分数 mysql> select teacher.tname,avg(sc.score) from teacher \ join course on teacher.tno=course.tno join sc on course.cno=sc.cno \ where teacher.tname='xiaoA' group by teacher.tno,course.cno;
# 每位老师所教课程的平均分,并按平均分排序? mysql> select teacher.tname,course.cname,avg(sc.score) from teacher \ join course on teacher.tno=course.tno join sc on course.cno=sc.cno \ group by teacher.tno,course.cno order by avg(sc.score);
# 查询xiaoA老师教的不及格的学生姓名? mysql> select teacher.tname,group_concat(student.sname) from teacher \ join course on teacher.tno=course.tno join sc on course.cno=sc.cno join student on sc.sno=student.sno \ where teacher.tname='xiaoA' and sc.score<60 group by teacher.tno;
# 查询所有老师所教学生不及格的信息? mysql> select teacher.tname,group_concat(student.sname) from teacher \ join course on teacher.tno=course.tno join sc on course.cno=sc.cno join student on sc.sno=student.sno \ where sc.score<60 group by teacher.tno;
嵌套查询
select 列名 from 表名 where 列名 > (select avg(列名) from 表名); # 取出大于Linux课程的平均分学生都有哪些; select name from student where sc > (select avg(sc) from students); # 取出Linux课程成绩大于70分的所有男同学信息; select s.name,s.sc,s.gender from (select * from students where gender='M') AS s where s.sc >70;
元数据⭐⭐⭐⭐⭐
描述database的数据,属性,状态等相关信息(表示在数据库服务中有哪些数据库,库中有哪些表,表中有多少字段,字段是什么类型等等)
show命令获取元数据
-- 查询数据库服务中的所有数据库信息(数据库名称-元数据) mysql> show databases; -- 查询数据库服务中的相应数据表信息(数据表名称-元数据) mysql> show tables; mysql> show tables from mysql; -- 查询数据库服务中的建库/建表语句信息 mysql> show create database <库名>; mysql> show create table <表名>; -- 查询数据库服务中的数据表的结构(数据表的列定义信息-元数据) mysql> desc <表名>; mysql> show columns from <表名>; -- 查询数据库服务中的相应数据表状态 (数据表的状态信息/统计信息-元数据) mysql> show table status from <库名>; -- 查看数据库服务中的具体数据库表的状态信息(属于单库或单表查询) mysql> show table status from world like 'city' \G *************************** 1. row *************************** Name: city -- 数据表名称信息 Engine: InnoDB -- 使用的数据库引擎信息 Version: 10 Row_format: Dynamic Rows: 4046 -- 数据表的行数信息 Avg_row_length: 101 -- 平均行长度 Data_length: 409600 Max_data_length: 0 Index_length: 114688 -- 索引长度信息 Data_free: 0 Auto_increment: 4080 -- 自增列的值计数 Create_time: 2022-11-04 09:13:27 -- 数据表创建时间 Update_time: NULL Check_time: NULL Collation: utf8mb4_0900_ai_ci -- 校对规则信息 Checksum: NULL Create_options: Comment: -- 查询数据库服务中的相应数据表的索引情况(了解即可) mysql> show index from world.city; -- 查询数据库服务中的用户权限属性配置信息 mysql> show grants for root@'localhost'; -- 查询数据库服务的系统状态信息,表示当前数据库的所有连接情况 mysql> show [full] processlist; -- 查询数据库服务的所有配置信息 mysql> show variables; mysql> show variables like '%xx%'; -- 查询数据库服务的系统整体状态,表示当前数据库服务运行的即时状态情况 mysql> show status; mysql> show status like '%lock%'; -- 查询数据库服务的所有二进制日志信息(binlog日志) mysql> show binary logs; -- 查询数据库服务正在使用的二进制日志 mysql> show master status; -- 查询数据库服务具体二进制日志内容事件信息 mysql> show binlog events in 'binlog.000009'; -- 查询数据库服务存储引擎相关信息 mysql> show engine innodb status \G -- 在数据库服务主库查看从库信息 mysql> show slave hosts; -- 查询数据库服务主从状态信息 mysql> show slave status;
利用库中视图(information_schema)⭐⭐⭐⭐⭐
将查询基表元数据语句信息方法封装在一个变量或别名中,这个封装好的变量或别名就成为视图,视图信息都是存储在内存中的表
information_schema库中的内存表都是每次数据库服务启动时生成的,里面存储了查询元数据基表的视图信息
视图的基础使用
select a.tname as '老师名',group_concat(d.sname) as '不及格学生名' from teacher as a join course as b on a.tno=b.tno join sc as c on b.cno=c.cno join student as d on c.sno=d.sno where c.score<60 group by a.tno;
create view tv as select a.tname as '老师名',group_concat(d.sname) as '不及格学生名' from teacher as a join course as b on a.tno=b.tno join sc as c on b.cno=c.cno join student as d on c.sno=d.sno where c.score<60 group by a.tno;
# 调取视图信息等价于调取复杂的查询语句 mysql> select * from tv;
视图查询⭐⭐⭐
# 切换进入information_schema数据库中查看表信息 mysql> use information_schema; mysql> show tables; -- 此时看到的所有表信息,其实都是视图信息 # 查看获取视图信息创建语句 mysql> show create view tables; -- 查看tables这个视图表的创建过程 # 统计数据库资产信息(数据资产),获取每个库中表的个数和名称信息(业务相关) mysql> select table_schema,count(*),group_concat(table_name) \ from information_schema.tables group by table_schema; -- 获取相应数据库中表的个数,与数据库中拥有的表信息 # 统计数据库资产信息(数据资产),获取每个数据库数据占用磁盘空间 mysql> select table_schema,sum(table_rows*avg_row_length+index_length)/1024/1024 \ from information_schema.tables \ where table_schema not in ('mysql','sys','performance_schema','information_') \ group by table_schema; # 统计数据库资产信息(数据资产),获取具有碎片信息的表 mysql> select table_schema,table_name,data_free from information_schema.tables \ where table_schema not in ('mysql','sys','performance_schema','information_') and data_free >0; -- 碎片信息过多会导致索引信息失效,以及统计信息不真实的情况 # 统计数据库资产信息(数据资产),处理具有碎片信息的表 -- 可以对已经是innodb存储引擎的表做操作,实现整理碎片功能 mysql> alter table t1 engine=innodb; -- 可以对已经是innodb存储引擎的表做操作,实现批量整理碎片功能 mysql> select concat("alter table ",table_schema,".",table_name," engine=innodb") \ from information_schema.tables \ where table_schema not in ('mysql','sys','performance_schema','information_') and data_free >0; # 统计数据库资产信息(数据资产),获取数据库中非innodb表信息 -- 获取非innodb数据库引擎表 mysql>select table_schema,table_name,engine from information_schema.tables \ where table_schema not in ('mysql','sys','performance_schema','information_') and engine!='innodb'; -- 模拟创建一些myisam引擎数据表 mysql> use school; mysql> create table t1 (id int) engine=myisam; mysql> create table t2 (id int) engine=myisam; mysql> create table t3 (id int) engine=myisam; # 统计数据库资产信息(数据资产),修改数据库中非innodb表信息替换成innodb mysql> alter table world.t1 engine=innodb; -- 可以对不是innodb存储引擎的表做操作,实现数据表引擎修改 mysql> select concat("alter table ",table_schema,".",table_name," engine=innodb") \ from information_schema.tables \ where table_schema not in ('mysql','sys','performance_schema','information_') and engine !='innodb'; mysql> select concat("alter table ",table_schema,".",table_name," engine=innodb;") \ from information_schema.tables \ where table_schema not in ('mysql','sys','performance_schema','information_') and engine!='innodb' into outfile '/tmp/alter.sql'; ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
vim /etc/my.cnf [mysqld] secure-file-priv=/tmp -- 修改配置文件参数信息,实现将数据库操作的数据信息导入到系统文件中,配置完毕重启数据库服务 mysql> source /tmp/alter.sql -- 可以对不是innodb存储引擎的表做操作,实现数据表批量化引擎修改,调用数据库脚本信息
视图表字段说明(information_schema.tables)⭐⭐⭐
| 字段信息 | 解释说明 |
|---|---|
| TABLE_SCHEMA | 表示数据表所属库的名称信息 |
| TABLE_NAME | 表示数据库中所有数据表名称 |
| ENGINE | 表示数据库服务中的引擎信息 |
| TABLE_ROWS | 表示数据库相应数据表的行数 |
| AVG_ROW_LENGTH | 表示数据表中每行的平均长度 |
| INDEX_LENGTH | 表示数据表中索引信息的长度 |
| DATA_FREE | 表示数据库服务碎片数量信息 |
| CREATE_TIME | 表示数据表创建的时间戳信息 |
| UPDATE_TIME | 表示数据表修改的时间戳信息 |
| TABLE_COMMENT | 表示数据表对应所有注释信息 |
说明:使用information_schema的视图查看功能,可以看到全局数据库或数据表的元数据信息,探究全局层面的元数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号