Kafka(3)- GroupCoordinator
- 负责管理消费组,包括消费组的位移提交和消费组的成员管理,GroupCoordinator存储着消费组的成员元信息。
- 负责Consumer Rebalance,当发生以下任意情况时,会触发Consumer Rebalance:
- 消费组内的成员变化(比如新加入消费者,消费者主动退出或崩溃;
- 服务端的分区发生变化,比如消费者增加了新的topic订阅或删除了部分topic,或者某个topic的某个partition所在broker崩溃等。
1. GroupCoordinator的选取
一个消费者组(consumer group)在服务端对应着一个GroupCoordinator,该GroupCoordinator负责管理该consumer group的分区分配信息,位移提交信息。kafka的所有消费位移都保存在内部主题__consumer_offset中,通过服务端配置参数offsets.topic.num.partitions来配置__consumer_offset的分区数量大小,默认为50。某个group对应的GroupCoordinator所在节点的位置,计算方式如下:
(1)计算消费者组对应的分区号 = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount,groupMetadataTopicPartitionCount为主题__consumer_offset的分区数;
(2)找到了消费者组对应的分区号,再寻找该分区对应的leader节点,leader节点所在的节点即为GroupCoordinator所在的位置。
一个消费者组的所有消费位移,都是提交到__consumer_offset的同一个分区,该分区的计算方式和消费者组对应的GroupCoordinator的计算方式一致。这样就保证了GroupCoordinator所在节点就是该消费组位移提交所在节点。同时,消费组内分区分配信息也都保存在GroupCoordinator上。这种机制保证了消费位移管理,消费组成员管理都在GroupCoordinator节点完成,减少了不必要的网络开销。
2. 再均衡(consumer rebalance)的过程
在文章开篇,我们提到了GroupCoordinator的职责之一是负责consumer rebalance并介绍了触发rebalance的情况。当出现consumer rebalance时,所有消费者需要重新加入消费组,并且重新分配消费分区,每个消费者完成consumer rebalance都需要经历以下过程:
(1)FindCoordinator:这一步是需要找到GroupCoordinator所在broker节点的位置。如果消费者已经保存了消费者组GroupCoordinator的节点信息,且它们之间的网络连接是正常的,则此步骤可以跳过。否则,需要像集群中的leastLoadedNode节点(负载最小的节点)发送FindCoordinatorRequest,获取GroupCoordinator的node_id,host, port等信息。
(2)JoinGroup:这一步,消费者会发送JoinGroupRequest,请求加入消费者组。GroupCoordinator收到所有Consumer的请求,需要选取消费者leader节点和分区分配策略。消费者leader的选取策略为第一个加入消费组的消费者即为消费者leader;分区分配策略为所有消费者都支持的第一个分区分配策略(消费者在发送JoinGroup请求时,会携带自身所有支持的分区分配策略)。完成消费者leader选举和分区策略选取之后,GroupCoordinator会发送JoinGroupResponse返回给消费者。其中发送给消费者leader的JoinGroupResponse还携带了所有的group member的metadata信息。
(3)SyncGroup:消费者leader会根据分区分配策略,对分区进行分配,将分配结果填充到SyncGroupRequest中,发送给GroupCoordinator;其他消费组内的成员也会发送SyncGroupRequest,只是不包含分区分配信息。GroupCoordinator将从消费组leader收到分区分配结果,填充到SyncGroupResponse中,将分配结果下发到所有消费者。分区的分配是由消费者leader完成的,这样能一定程度减轻GroupCoordinator的负载。
(4)消费者向GroupCoordinator发送OffsetFetchRequest,拉取消费位移,开始消费;并通过heartbeat与GroupCoordinator保持连接。
2.1 group management protocol
整个再均衡的过程,基于kafka设计的group management protocol(组管理协议),该协议规定了实现组管理的一系列动作,包括:
- Group Registration: Group members register with the coordinator providing their own metadata(such as the set of topics they are interested in)
- Group/Leader Selection: The coordinator select the members of the group and chooses one member as the leader.
- State Assignment: The leader collects the metadata from all the members of the group and assigns state.
- Group Stabilization: Each member receives the state assigned by the leader and begins processing.
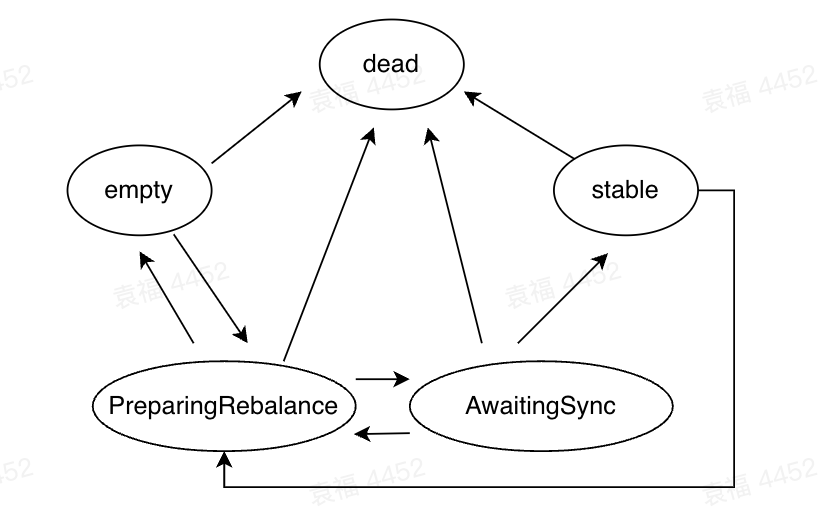
图1 group内同步过程中的状态机
- dead:group内没有任何成员,且group的元数据也已经被清除,所有到coordinator的响应,返回response 都是UNKNOWN_MEMBER_ID;
- empty:组内没有任何成员,但是组的元数据还没有过期,可以响应JoinGroupRequest;
- PreparingRebalance:从收到第一个JoinGroupRequest,到coordinator完成leader和group protocol选举,返回JoinGroupResponse期间;
- AwaitingSync:各成员发送SyncGroupRequest,coordinator park住所有的request,直到consumer group leader返回partition assignment,coordinator将分配结果组装到SyncGroupResponse中,并通知到所有group member;
- stable:所有成员都收到了自己的分区分配信息,开始拉取消费位移,正常消费。
2.2. consumer rebalance详情
基于2.1的协议,我们再来回顾一下consumr rebalance的所有重要步骤。
2.2.1 JoinGroup阶段
JoinGroupRequest

图2 JoinGroupRequest的格式
其中比较核心的参数包括:
- group_id:消费组id,在初始化consumer时不允许为空;
- session_timeout:对应消费端参数session.timeout.ms,默认10000,当GroupCoordinator超过此时间没收到消费者的心跳报文时,就认为该消费者下线了;
- rebalance_timeout:对应消费端参数max.poll.interval.ms,默认30000,即5分钟。此参数表示当消费组再平衡时,GroupCoordinator等待各消费者重新加入的最长时间;
- member_id:GroupCoordinator分配给消费者的id标志,在未分配之前为null;
- protocol_type:对应为consumer;
- group_protocols:消费者支持的分区分配协议,GroupCoordinator依赖该字段选取各个consumer都支持的协议;常见的分区分配协议有:RangeAssignor,RoundRobinAssignor,StickyAssignor。
Select ConsumerLeader&protocol
JoinGroup之后,GroupCoordinator选取第一个加入消费组的consumer作为ConsumerLeader,如果ConsumerLeader下线,再次选举ConsumerLeader的过程可以认为是随机的。由于每个消费者在发送JoinGroupRequest的时候,携带了自身支持的所有protocols,该数组的顺序代表了消费者对该协议的支持顺序,靠前的优先支持。GroupCoordinator就从所有consumer提交的所支持的protocols中选取所有消费者都支持的第一个protocol。如果有消费者不支持选举出来的protocol,就会报错IllegalArgumentException: Member does not support protocol。
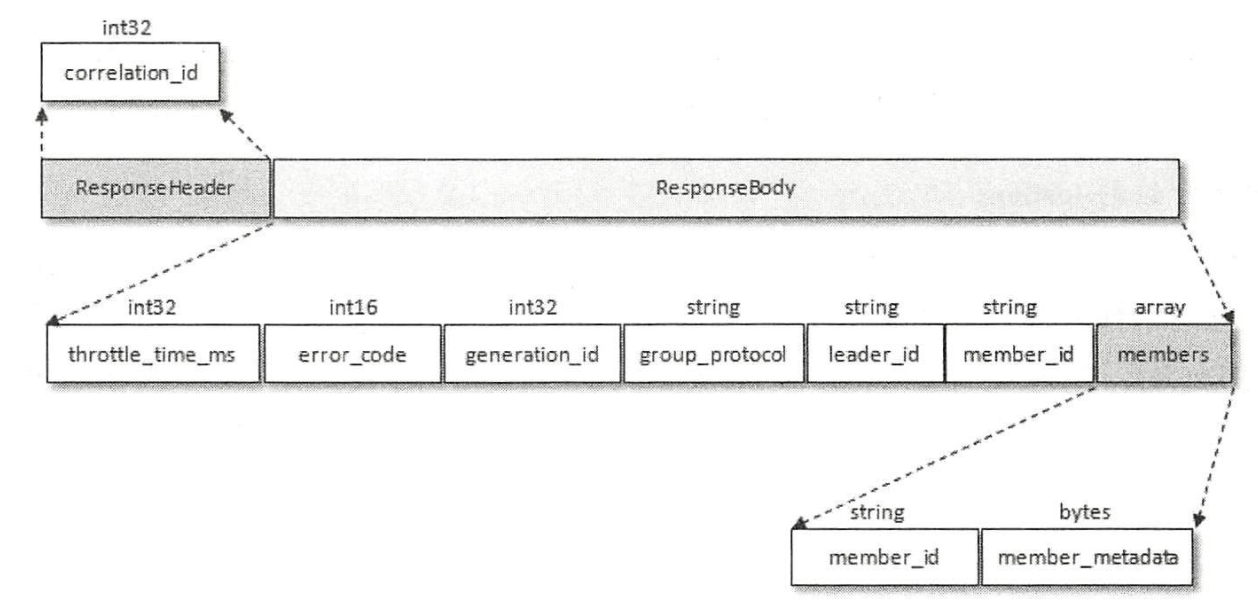
JoinGroupResponse
JoinGroupResponse的结构如下:
2.2.2 SyncGroup阶段
在JoinGroup阶段,Leader消费者知晓了消费组成员状况和分区分配策略,在SyncGroup阶段,Leader消费者会在SyncGroupRequest中携带分区分配结果(分配是由Leader消费者完成的),SyncGroupRequest的结构如下:
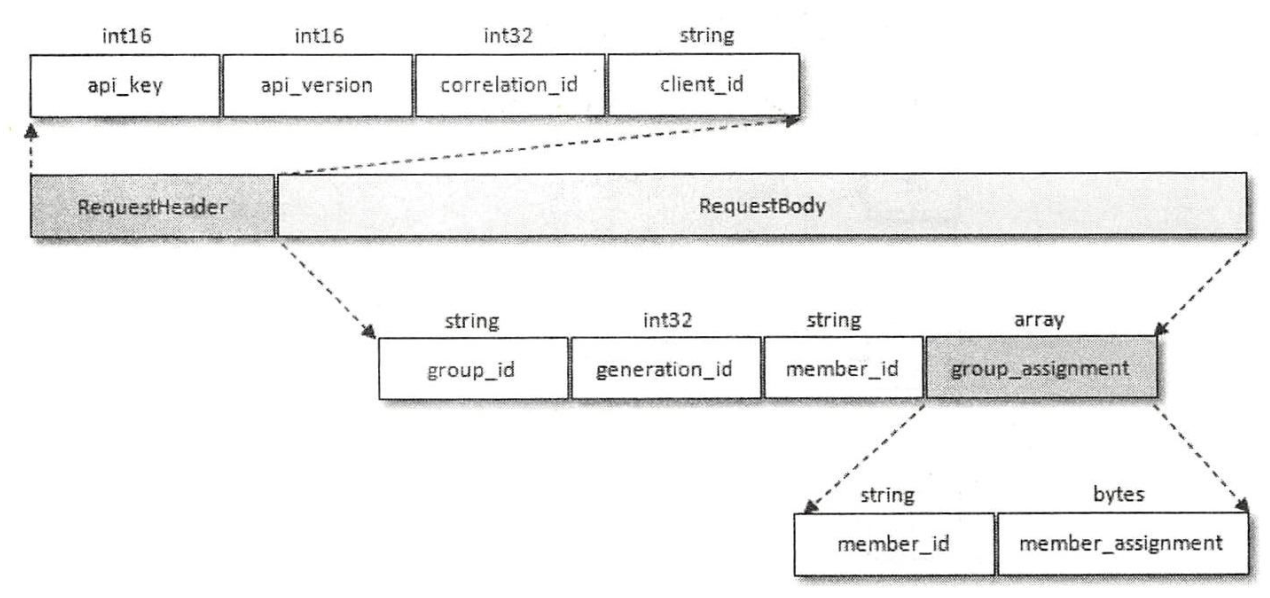
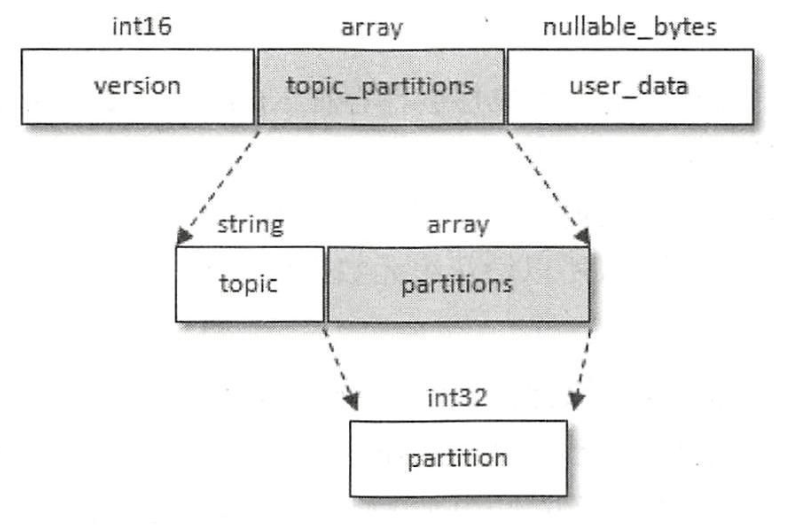
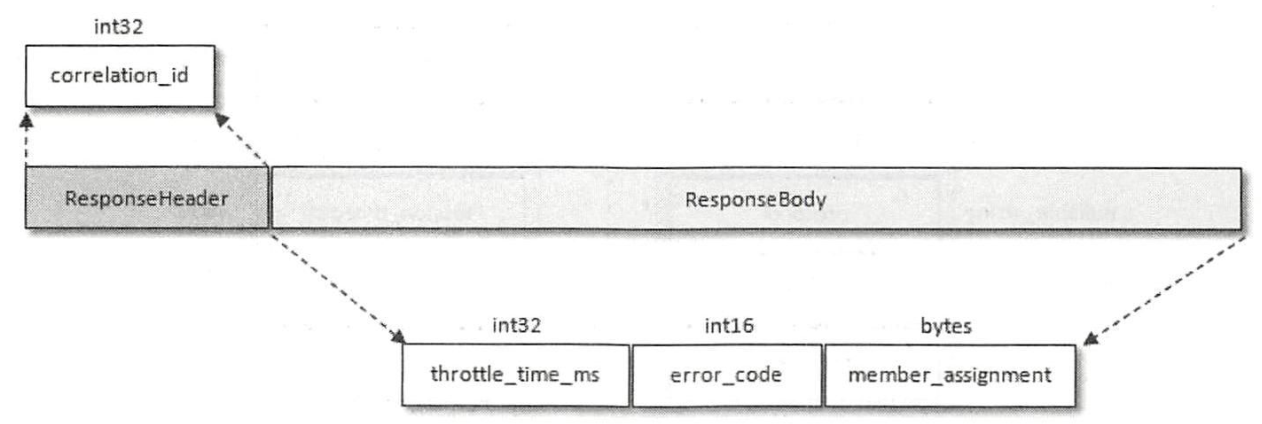
2.2.3 Heartbeat
3. 消费位移管理
kafka的所有消费位移,都会被当成一条消息,写入内部topic __consumer_offset中。一个consumer写入消费位移的broker和GroupCoordinator所在的broker是同一个broker,这样能保证消费者元数据,消费位移和GroupCoodinator在同一个broker实例上,方便GroupCoodinator对消费组进行管理。在consumer的介绍中,提到了提交消费位移有同步和异步两种,本质都是发送OffsetCommitRequest,只是异步提交会先将请求放入缓存,在下一次client.poll中发送;同步提交将请求放入缓存后,会立即调用client.poll进行发送。commitOffsetRequest的具体格式如下:
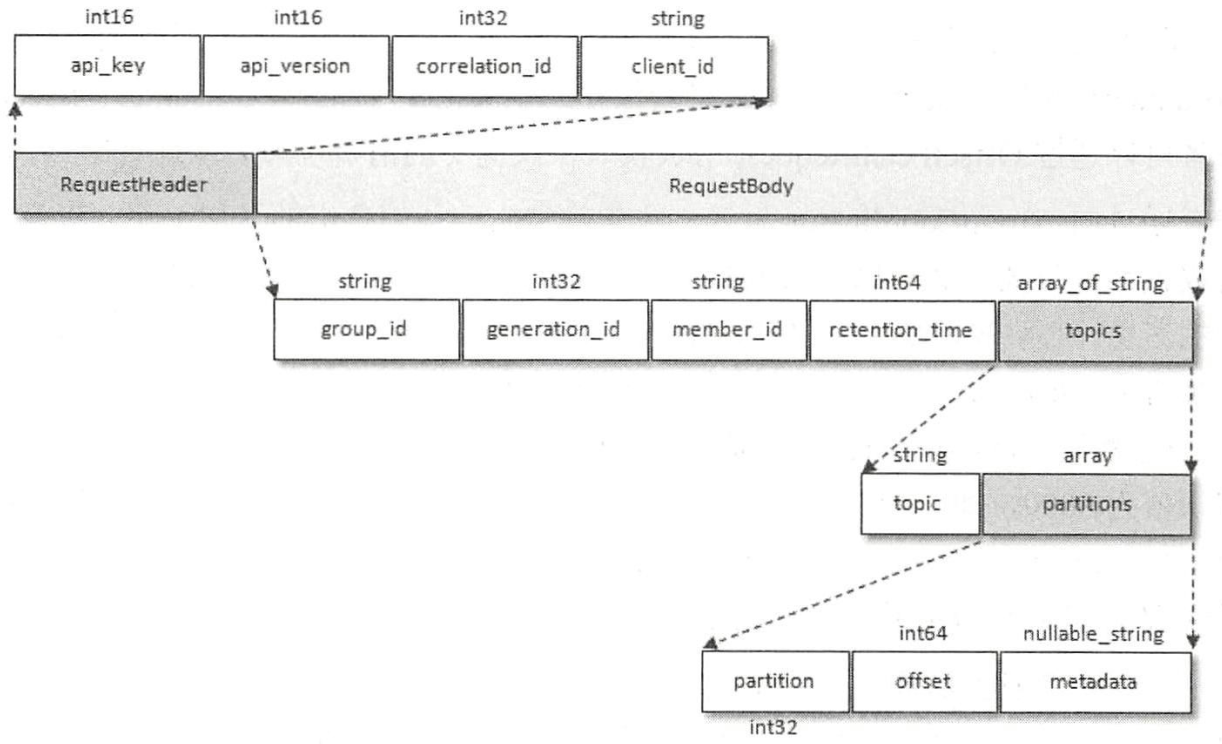
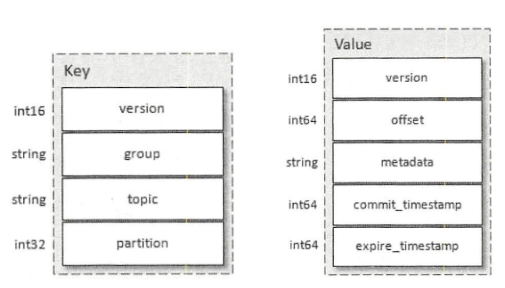
图8 consumer offset的保存格式
4. 总结
本文重点讲解了kafka consumer rebalance的过程,主要是想让大家明白一次consumer rebalance的代价。读完这篇文章,相信不少人还有以下疑惑:
(1)触发rebalance之后,其他之前正常消费的consumer怎么知道需要重新加入消费组?
(2)消费者发送JoinGroupRequest之后,GroupCoordinator会park住所有的request,直到收到所有consumer的请求。GroupCoordinator怎么知道需要收到哪些consumer的请求呢?
对于问题(1),一旦触发了rebalance,GroupCoordinator会从stable状态转移到PreparingRebalance状态,后续所有的consumer再次与GroupCoordinator通信时,就会知道需要重新加入消费组了,所以是GroupCoordinator通过状态转移通知了所有消费者重新加入消费组。对于问题(2),GroupCoordinator有一个消费组所有消费者的元信息,自然知道应该有多少个消费者需要发送JoinGroupRequest。理论上,每次rebalance的最大时长应该等于max(rebalance_timeout),rebalance_timeout为每个消费者设置的rebalance超时时间。一旦消费者感知到了需要重新加入消费组,会先完成后续的善后工作(比如处理完本次消息并提交消费位移),然后发送JoinGroupRequest,这个时间间隔一般很短。极端情况下,某个consumer在rebalance的时候下线了,那么此次rebalance的耗时就会很高。
参考资料
- 《深入理解 Kafka :核心设计与实践原理》
- What happens when a new consumer joins the group in Kafka
- Kafka 0.9 Consumer Rewrite Design

 浙公网安备 33010602011771号
浙公网安备 33010602011771号