import requests
import re
class DouBanBookSpider(object):
"""豆瓣图书爬虫"""
def __init__(self):
self.url = "https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start={}&type=T"
self.cookies = """ll="108304"; bid=R6Pt4oTxZi8; _vwo_uuid_v2=D7A53E36D669FBBB91A373A6A66501916|90ed43ffd4cc7e306714b0e17bb6abe1; __utmz=30149280.1588666895.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=30149280; __utma=30149280.1990509793.1588598310.1588601953.1588666895.3; __utmt=1; dbcl2="154205275:TJys/10xBNM"; ck=luz-; __utmt_douban=1; __utmc=81379588; __utma=81379588.192167986.1588666947.1588666947.1588666947.1; __utmz=81379588.1588666947.1.1.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; gr_user_id=0188176d-b263-4c37-a574-475ea719d4f8; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03=32e1b649-e9db-4370-bcd7-a67f4f9b64d6; gr_cs1_32e1b649-e9db-4370-bcd7-a67f4f9b64d6=user_id%3A1; _pk_ref.100001.3ac3=%5B%22%22%2C%22%22%2C1588666947%2C%22https%3A%2F%2Faccounts.douban.com%2Fpassport%2Flogin%3Fredir%3Dhttps%253A%252F%252Fbook.douban.com%252F%22%5D; _pk_ses.100001.3ac3=*; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03_32e1b649-e9db-4370-bcd7-a67f4f9b64d6=true; __yadk_uid=cUz687nYvCDbnaYMwl7wHOJWvxhllC7h; __gads=ID=cc9d743007559993:T=1588666950:S=ALNI_MYzY1BkdckBD1ZdHdqirBbTlqnRxA; push_noty_num=0; push_doumail_num=0; __utmb=30149280.4.10.1588666895; __utmb=81379588.3.10.1588666947; _pk_id.100001.3ac3=0b04a4ce0ca8175d.1588666947.1.1588666983.1588666947."""
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36",
"Cookie":self.cookies
}
def create_url(self):
"""构造url地址"""
return [self.url.format(i*20) for i in range(100)]
def run(self):
# 创建保存数据的csv文件
with open("./books.csv","a+",encoding="utf-8") as f:
f.writelines("ID,Name,Rat,Pin,,Raise\n")
# 构造url地址
url_list = self.create_url()
# 模拟浏览器发送请求,获取响应
for i in url_list:
responses = requests.get(i,headers=self.headers)
print(responses.content.decode())
data = responses.content.decode()
# 数据的提取和保存
self.extract_data(data)
def extract_data(self,data):
patter = "subject_id:\'(.*?)\'"
book_ids = list(set(re.compile(patter).findall(data)[1:]))
book_id = []
book_names = []
# print(book_id)
for i in book_ids:
book_id = i
book_name_patter = "<a href=\"https://book.douban.com/subject/{}/\" title=\"(.*?)\"".format(i)
book_name = re.compile(book_name_patter).findall(data)
book_names.append(book_name)
book_pin_num_patter = """ <span class="pl">
(.*?)
</span>"""
book_rat_patter = "<span class=\"rating_nums\">(.*?)</span>"
book_raise_patter = """<div class="pub">
(.*?)
</div>"""
book_rat = re.compile(book_rat_patter).findall(data)
book_pin_num = re.compile(book_pin_num_patter).findall(data,re.S)
book_raise = re.compile(book_raise_patter).findall(data,re.S)
print("图书id:{} 图书名称:{} 图书评分:{} 图书评价人数:{} 图书价格:{}".format(book_ids,book_names,book_rat,book_pin_num,book_raise))
# num = 0
with open("./books.csv","a+",encoding="utf-8") as f:
# if num ==0:
# f.writelines("ID,Name,Rat,Pin,,Raise\n")
# num+=1
# else:
content = [book_ids[i]+","+book_names[i][0]+","+book_rat[i]+",+"+book_pin_num[i]+","+book_raise[i]+"\n" for i in range(len(book_ids))]
print(content)
[f.writelines(i) for i in content]
def main():
dou_ban_spider = DouBanBookSpider()
dou_ban_spider.run()
if __name__ == '__main__':
main()
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
file_path = "./books.csv"
df = pd.read_csv(file_path)
# 获取所有电影评分
rat_all_list = df["Rat"]
# 评分最低分
min_rat = min(rat_all_list)
# 评分最高分
max_rat = max(rat_all_list)
# 最低分与最高分的差值
dis = max_rat - min_rat
# 直方图的组距
interval = 0.5
# 将图形分为多少组进行呈现
num_bins = int(dis//interval)
# 绘制直方图
font = {
"family":"Microsoft YaHei",
"weight":"bold",
"size":15
}
# 设置中文字体
matplotlib.rc('font',**font)
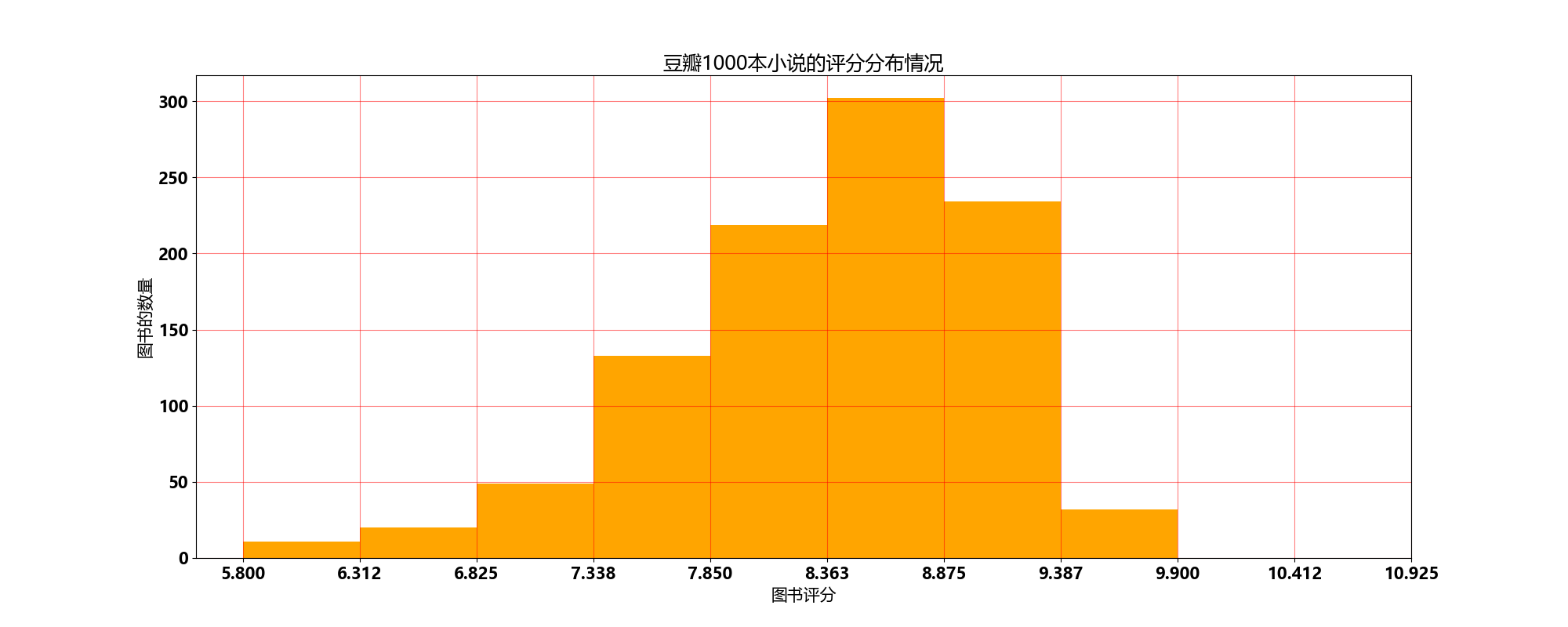
plt.figure(figsize=(20,8),dpi=100)
plt.hist(rat_all_list,num_bins,color='orange')
plt.grid(alpha=0.5,color='r')
x_ticks = [min_rat]
index = min_rat
while index< max_rat + dis/num_bins:
index += dis/num_bins
x_ticks.append(index)
plt.xticks(x_ticks)
plt.xlabel("图书评分")
plt.ylabel("图书的数量")
plt.title("豆瓣1000本小说的评分分布情况")
plt.show()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号