
【redis】2、Redis的Value的常见数据类型以及使用场景
之前已经介绍了redis的三种安装方式,为什么redis的性能这么好呢?主要是因为以下几点:
- redis是基于内存的操作,操作不需要进行磁盘交互
- redis本身是基于类似k-v这种键值对结构,所以查询数据非常快
- redis底层对于多种数据结构的优化使用,比如调表、SDS
- redis执行命令是单线程的,没有线程切换的时间消耗,同时在IO过程中使用了多路复用机制,每个线程中通过记录每个sock(IO流)的状态来管理多个I/O流
此外,redis本身在数据一致性方面提供了持久化机制和多种过期策略,并且提供了高可用集群方案
1、redis的数据结构
1.1、redis的数据结构
redis的数据结构如下图所示:
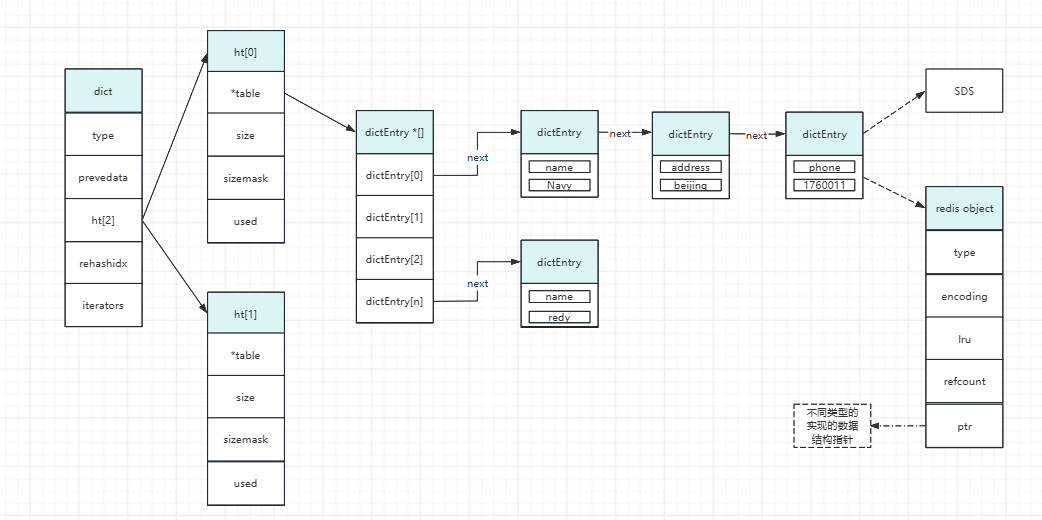
整体是一个dict的结构,在dict里边定义了一个长度为2的数组dictht,主要利用空间换时间的理念,在扩缩容的时候会用到,平时只会用到ht[0]。在ht[0].table里边是一个dictEntry数组,每个dictEntry是一个key-value的格式,其中key是redis定义的SDS格式,value是RedisObject对象格式,根据数据不同会采用不能的数据类型
1.2、扩容
ht[0]的size默认大小为4
-
扩容条件
- 当没有子进程进行数据持久化的时候(同步数据到磁盘),ht[0].used>=ht[0].size的时候
- 当有子进程在进行数据持久化的时候,ht[0].used>ht[0].size*5
-
扩容时机
- 添加数据的时候:
dictReplace->dictAddRaw
- 添加数据的时候:
-
如何扩容
- 当触发扩容的时候,如果当前状态是正在扩容,或者计算出来扩容后的大小跟ht[0]的size一样,则不进行其它操作
- new一个新的dictht,大小为ht[0].size*2然后向上取临近的2的n次幂
当要扩容的时候,redis会new一个dictht,并且空间大小是原来的size的两倍并向上取接近2的幂次方,比如原来usedsize=4,扩容后新的dictht的大小就是8,如果之前usedsize为6,则扩容后的大小为16
- ht[1]=new的dictht,rehashidx=0(准备好了数据,可以迁移了)
- 数据迁移(渐进式迁移,不会阻塞当前线程任务)
- 每次增删改查的时候如果rehashidx!=-1的时候,都会进行数据迁移,但是不会每次全部迁移,只会迁移一个hash桶,比如上面图示的dictEntry[0],第一个桶迁移完成后rehashidx加1,下次迁移第二个hash桶
- 定时任务触发(serverCron事件迁移),同样只会迁移部分数据,但是可能一次会迁移N个哈希桶,定时可配(server.hz,默认100ms一次)一次迁移数据量可配(默认100个桶,但是要求在指定时间之内完成,在这个时间内能迁移多少个就迁移多少个)
- 遇到空桶继续迁移,直到循环超过10个空桶、或者达到要迁移的桶数,比如要迁移20个桶,当在迁移第19个的时候发现是个空桶,则继续看第20个桶,如果第20个还是空桶,继续看第21个,直到再迁移2个达到20个桶迁移的目标,或者接下来10个桶都是空桶的化,则本次迁移到此为止,也就是只迁移了前面的18个桶
- 数据迁移完成后,ht[0]=ht[1],ht[1]释放:即ht[1].table=null, ht[1].size=0,并且dict的rehashidx的标识改为-1(当前没有任务在做迁移)
2、redis的value常见数据类型
从redis的 官方文档 支持的命令就可以看到,redis支持的数据类型特别丰富
2.1、String类型
2.1.1、String相关的命令

比如:
- 给key为name设置值为Navy:
127.0.0.1:6379> set name Navy
OK
127.0.0.1:6379>
127.0.0.1:6379> get name
"Navy"
- 给名称为
name的这个key设置过期时间为5s(ttl key查看key的过期时间)
127.0.0.1:6379> setex name 5 name
OK
127.0.0.1:6379> get name
"name"
127.0.0.1:6379> ttl name
(integer) 3
127.0.0.1:6379> get name
"name"
127.0.0.1:6379> get name
"name"
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> ttl name
(integer) 0
- 删除key
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
- 批量设置
name的value是liu,age是18
127.0.0.1:6379> mset name liu age 18
OK
127.0.0.1:6379> get name
"liu"
127.0.0.1:6379> get age
"18"
String类型的对应的value能够存储的数据类型非常多,如String、number、float、bits等,其中数字类型的比如number、float都可以用incrby命令,比如
127.0.0.1:6379> set score 85.2
OK
127.0.0.1:6379> incrbyfloat score 10
"95.2"
整型的就直接
incrby
其value最大值是512mb。redis的key都是String存储的,所以key的最大值也是512mb
2.1.2、应用场景
2.1.2.1、缓存
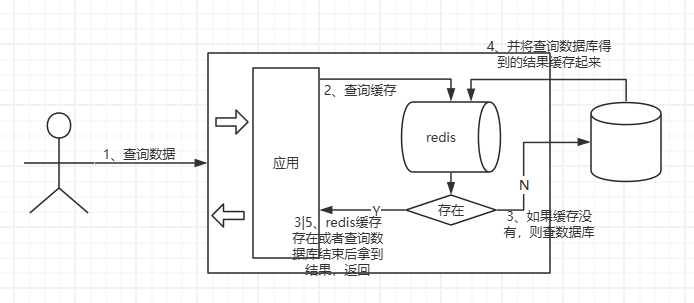
String类型的主要使用场景就是作为缓存使用,比如为了减少前端和数据库的交互减轻数据库的压力,对于一些没有强实时性要求的数据,可以将数据在redis中缓存一份,如果前端请求过来的时候先从缓存里拿,如果缓存中没有,则再去查数据库,查到数据的时候再往缓存里写一份并返回,这样下次再来查询同样的数据的时候就可以直接走缓存了不用再去查数据库了
2.1.2.2、全局id
前面在介绍String类型数据用法的时候提到一个incr 、incrby指令,由于redis的指令是原子性的,所以可以利用这个指令来生成全局递增的ID。此外也可以利用这个来做分布式场景下的计数
2.1.3、底层数据结构-SDS
在redis中,String的底层并没有采用c的char来实现,而是自定义了一种SDS(Simple Dynamic String)的数据结构。下面就是定义的五种SDS结构:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings.
*/
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */ //已使用的长度
uint8_t alloc; /* excluding the header and null terminator */ //分配的总容量 不包含头和空终止符
unsigned char flags; /* 3 lsb of type, 5 unused bits*/ //低三位类型 高5bit未使用
char buf[]; //数据buf 存储字符串数组
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
可以看到主要定义了一个char数组,保存具体的值,并且定义了一个标识字段flags(只用到低三位)。此外在除sdshdr5外的其它几种类型中,都定义了已使用长度字段len和预分配了不包含头和空终止符的内存总容量字段alloc
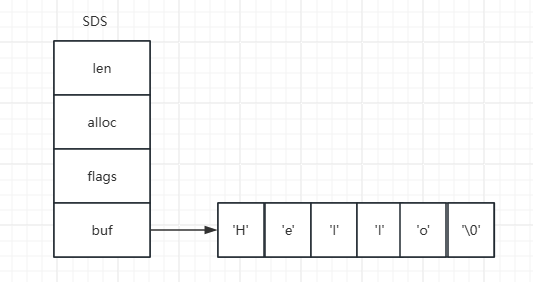
SDS的结构大概如上图所示,比如现在初始对应的是‘Hello’这个字符串。其中flags表示使用的是哪种SDS,比如等于1意思用sdshdr8(小于2^8的长度都用sdshdr8,len和alloc都只用两个字节),这个值会根据len去计算选择。另外在SDS中直接保存了字符串的长度,所以如果要获取一个字符串的长度是非常快的,不用像便利字数组那边遍历。后续会根据存放的内容动态进行扩容
2.1.3.1、空间换时间
- 预分配
我们知道,像在hashmap等数据结构中要保存数据,经常会涉及到扩容的问题,同样的,SDS也考虑到了这一点。因为要追求极致的性能,所以redis在设计sds的时候秉承着这一点就采用了空间换时间的理念进行空间预分配。在小于1mb的长度的时候,redis会以两倍的空间分配,大于1mb的时候,会每次加1mb
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC) //小于1M 2倍
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; //大于1M,每次预分配长度+1M
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation.
*/
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc
*/
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
- 惰性释放
在空间动态调整的过程中,可能后续用不到这么多的内存,比如对字符串进行截取的时候,redis并不会立即释放,仅提供相关的API出来,如果用户没有显示释放,则对应的空间还能够继续使用。
2.1.3.2、二进制安全
sds的二进制安全是相对于c的字符串来说的。
在c中,字符串的结尾是以空字符串为标识的,也就是说在字符串中间不能出现空字符串,这也就限制了c的字符串只能保存字符串文本。
而在sds中,它的结束标识符是'\0',这就意味着它可以存放任何非'\0'的字符,也就是说它甚至可以通过二进制的形式保存图片、音频、视频等内容。
2.1.4、优缺点
-
优点
- 查询长度比较快(SDS里边记录了字符串的长度)
- 减少修改字符长度带来的内存重新分配(预分配、惰性释放)
- 二进制安全
-
缺点
浪费空间
2.2、Hash类型
2.2.1、Hash类型相关的指令

比如:
- 设置一个人的信息
127.0.0.1:6379> hset person name navy age 18 address shanghai phone 17610001100
(integer) 4
127.0.0.1:6379> hget person name
"navy"
127.0.0.1:6379> hget person age
"18"
127.0.0.1:6379> hget person address
"shanghai"
- 查看
person这个key的完整内容
127.0.0.1:6379> hgetall person
1) "name"
2) "navy"
3) "age"
4) "18"
5) "address"
6) "shanghai"
7) "phone"
8) "17610001100"
- 给年龄加5岁
127.0.0.1:6379> hincrby person age 5
(integer) 23
127.0.0.1:6379> hgetall person
1) "name"
2) "navy"
3) "age"
4) "23"
5) "address"
6) "shanghai"
7) "phone"
8) "17610001100"
2.2.2、使用场景
结合上面简单的使用,可以看出hash类型大概的结构就是一个key下面可以设置多个属性。这一点是不是跟我们java中对象的定义非常像?所以一般用来存储对象比较多。
举例:
我们现在要做一个短视频的统计数据,比如点赞数、评论数、收藏数、转发数,可以用这个视频的id作为key,这几个指标作为field,每次有对应的操作执行一次incrby,效率不也是杠杠的
2.2.3、底层数据结构-ziplist+dictht哈希表
2.2.3.1、ziplist 压缩列表
ziplist是基于偏移量来定位的
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
字节数 开始位置 entry的长度 entry数据 entry结束
而entry的格式为:
<prevlen> <dncoding> <entry-data>
上一个entry的长度 编码 entry数据
大致的意思如下图所示:

一个偏移量找到a,在找2个偏移量找到ab,再找3个偏移量找到abc,再找4个偏移量得到abcd,再找5个偏移量,找到abcde
但是这样依赖对于数据的变更就非常不友好了,比如将ab改成了abx,这意味着后续的所有数据都要同步更新。而且如果数据越多,连锁更新的影响更大。所以ziplist只适用于数据量小的场景
当数据量达到一定程度的时候,redis的hash结构使用的是hash表,也就是dictht
2.2.3.2、dictht 哈希表
在redis.conf配置文件中,有一个配置:
#entries的数量不能超过512
hash-max-ziplist-entries 512
#value的最大值不能超过64byte
hash-max-ziplist-value 64
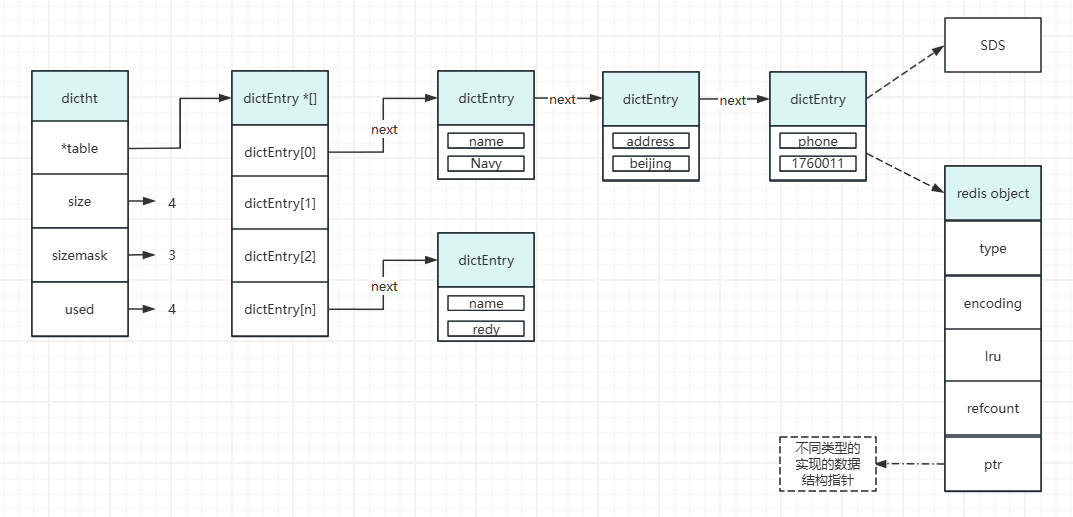
也就是在entry(field)少于512且每个的value不超过64byte的时候会用ziplist,超过这个配置的值就会使用哈希表。前面介绍了dictht的结构大致如下图所示,不同的数据类型主要体现在RedisObject上,如果当前采用的是哈希表的化,则redisObject里边嵌套的就是一个dictht,组成key field value这种结构:
2.3、List类型
2.3.1、List类型相关的指令

- 从左边往list里边添加几个元素
127.0.0.1:6379> lpush students lilei
(integer) 1
127.0.0.1:6379> lpush students hanmeimei
(integer) 2
127.0.0.1:6379> lpush students lily
(integer) 3
127.0.0.1:6379> lpush students lucy
(integer) 4
- 从左边拿一个元素
127.0.0.1:6379> lpop students 1
1) "lucy"
- 查看list里边的所有元素
127.0.0.1:6379> lrange students 0 -1
1) "lily"
2) "hanmeimei"
3) "lilei"
- 在lily和hanmeimei之前插入一个David
127.0.0.1:6379> linsert students before hanmeimei David
(integer) 4
127.0.0.1:6379> lrange students 0 -1
1) "lily"
2) "David"
3) "hanmeimei"
4) "lilei"
2.3.2、应用场景
刚才简单使用了一下list,可以发现它的几个特别,首先就是一个队列,其次是有序分前后。所以我们可以用它来做一些需要排队的场景,比如取号、
2.3.3、底层数据结构- quicklist+ziplist
在老版本中,list采用的是LinkedList,但是在新版本中采用的是quickList。quickList兼顾了ziplist的节省内存能力,也解决了它的连锁更新问题,因为它采用的是quicklist的节点下挂ziplist的这种结构
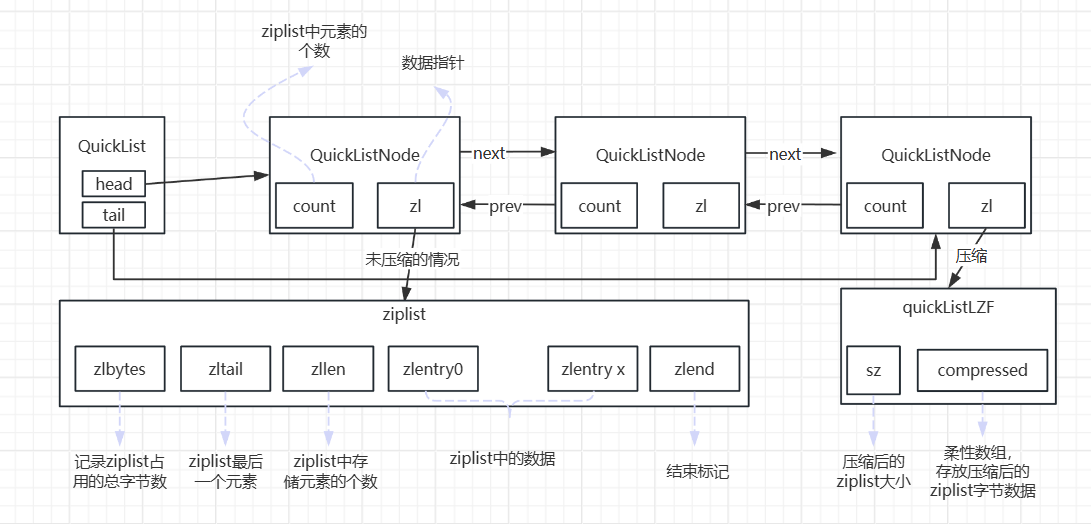
ziplist将列表中的每一个元素存放在一个前后连续的地址空间,整体占用一大块内存。经过压缩后的qucklistLZF使用一个柔性数组,存放压缩后的ziplist字节数据,同时记录压缩后的ziplist的数据大小
采用这种数据结构之后,连锁更新的问题被限制在quicklist的一个node上,而不影响整体的性能,所以兼顾了ziplist的节省内存的特性和规避了连锁更新的问题。那每个node下ziplist放多少数据呢?这个redis也把控制权下放给用户了,可以在redis.conf配置文件进行配置
list-max-ziplist-size -2
默认值是
-2-1:4kb(good)好
-2:8kb(good)好
-3:16kb(probably not recomment)一般不建议
-4:32kb(not recommend)不建议
-5:64kb(not recommend for normal workloads)正常的工作负载下不建议
2.4、Set类型
2.4.1、Set类型相关指令

比如:
- 往集合里边添加几个元素
127.0.0.1:6379> sadd hobby football
(integer) 1
127.0.0.1:6379> sadd hobby tabletennis
(integer) 1
127.0.0.1:6379> sadd hobby drawing
(integer) 1
127.0.0.1:6379> sadd hobby singing
(integer) 1
127.0.0.1:6379> smembers hobby
1) "football"
2) "tabletennis"
3) "drawing"
4) "singing"
- 再添加一个集合,计算两个集合的交集
127.0.0.1:6379> sadd experts singing
(integer) 1
127.0.0.1:6379> sadd experts dancing
(integer) 1
127.0.0.1:6379> sadd experts speeching
(integer) 1
127.0.0.1:6379> smembers experts
1) "singing"
2) "dancing"
3) "speeching"
127.0.0.1:6379> sinter hobby experts
1) "singing"
- 计算两个集合的并集
127.0.0.1:6379> sunion experts hobby
1) "football"
2) "singing"
3) "dancing"
4) "speeching"
5) "drawing"
6) "tabletennis"
- 从
hobby集合中随机取出一个元素
127.0.0.1:6379> spop hobby 1
1) "tabletennis"
2.4.2、使用场景
简单体验了一下set的使用,可以看到Set是一个无序的集合,可以添加元素、随机取元素、取集合的交集并集等。所以我们可以结合这些能力做一些事情,比如抽奖、找共同好友、找共同话题等等
2.4.3、底层的数据结构-intset+dictht
redis的set类型value采用了两种数据结构,一个是intset,另一个是dictht哈希表
2.4.3.1、intset
如果set里存放的都是整形数据,且集合里边的元素个数小于512(默认)则采用的是intset,而且它是有序的。intset的结构如下图所示:
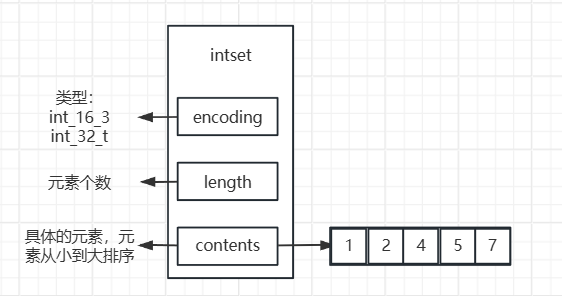
当元素个数越来越多的时候,要进行集合的一些操作就越来越困难,性能会越来越差,所以就引入了dictht哈希表,而这个阈值也是可以在redis.conf文件中进行配置的:
set-max-intset-entries 512
2.4.3.2、dictht
如果集合里边存放的不都是整数,或者集合里边的元素个数超过512个,redis则采用哈希表来存储set类型的value。dictht哈希表的格式前面已经介绍过了,这里不再赘述。
但是我们知道哈希表是一个key-value的格式,它如何保存set的呢?其实在redis中存放set元素的时候,这个哈希表只用到了每个dictEntry的key,没有用到value,也就是说它是将这些元素保存在哈希表的key中的,所有dictEntry的value都是null。
2.5、Sorted Set类型
2.5.1、Sorted Set类型相关的指令

比如:
- 往集合中添加几个元素,表示某个人的朋友圈,其中的数值代表亲密度
127.0.0.1:6379> zadd friends 19 polly
(integer) 1
127.0.0.1:6379> zadd friends 11 lucy
(integer) 1
127.0.0.1:6379> zadd friends 16 lily
(integer) 1
127.0.0.1:6379> zadd friends 14 hanmeimei
(integer) 1
- 查看朋友列表
127.0.0.1:6379> zrange friends 0 -1 REV
1) "polly"
2) "lily"
3) "hanmeimei"
4) "lucy"
可以看到亲密度最高的polly,其次是lily。zrange默认是升序排列的,上面的命令加了一个REV参数,表示反转
- 给lucy的亲密度增加10
127.0.0.1:6379> zincrby friends 10 lucy
"21"
127.0.0.1:6379> zrange friends 0 -1 REV
1) "lucy"
2) "polly"
3) "lily"
4) "hanmeimei"
可以看到,lucy就跑最上边去了
- 随机找两个好朋友
127.0.0.1:6379> zrandmember friends 2
1) "polly"
2) "lucy"
2.5.2、使用场景
前面简单体验了一下sorted set的类型,主要比set多了一个score,redis会根据这个score值进行排序,默认升序,查询的时候可以指定升序还是降序。前面示例演示的是一个朋友圈的例子,其实只要是在一些有序集合的场景都可以尝试一下看能不能用sorted set来解决我们的业务问题。比如文章或视频的热度排序、公司内部排名等
2.5.3、底层数据结构-ziplist+skiplist(跳表)
2.5.3.1、ziplist
为了节约空间,redis的sorted set类型默认情况下也会考虑用ziplist。但由于它的硬伤是连锁更新问题,所以也只能在一定数据量的条件下使用,这个阈值同样可配:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
元素个数小于128个,value的长度小于64个字节
2.5.3.2、skiplist
跳表是二分法查找的实现,也是一种空间换时间的思想。它的代码定义如下所示:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; //sds数据
double score; //score
struct zskiplistNode *backward; //后退指针
//层级数组
struct zskiplistLevel {
struct zskiplistNode *forward; //前进指针
unsigned long span; //跨度
} level[];
} zskiplistNode;
//跳表列表
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //头尾节点
unsigned long length; //节点数量
int level; //最大的节点层级
} zskiplist;
比如要在下面这个结构中找到27:
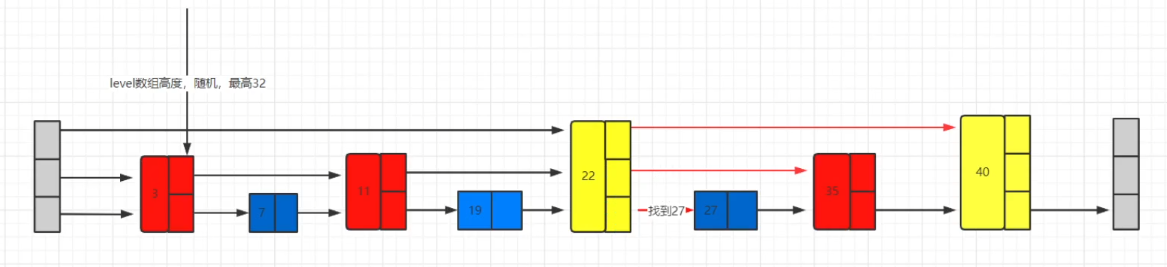
首先遍历第一层,找到22、40,而27刚好处于这个区间
然后遍历第二层,从22开始,找到22、35,而27也刚好在这个区间
然后遍历第三层,从22开始,找到22、27,然后就找到了
跳表的层级设计在数据量比较大的时候性能优势会更加明显,在redis中最大支持32层,因为层级越高查询性能越慢。
2.6、bitmap类型
2.6.1、bitmap类型相关指令

比如:
- 设置bitmap的第3位为1
127.0.0.1:6379> setbit bitmap 1 1
(integer) 0
127.0.0.1:6379>
127.0.0.1:6379> getbit bitmap 1
(integer) 1
127.0.0.1:6379> setbit bitmap 1558456912 1
(integer) 0
- 查看设置了多少位
127.0.0.1:6379> bitcount bitmap
(integer) 2
bitmap的操作比较简单,核心的指令就是设置某一个bit位的数值和获取某一个bit位的数值。由于是基于bit位的存储方式,所以占用的内存也比较小,假设一共有10亿位,则占用的空间:10 0000 0000 / 8 / 1024 / 1024 ≈ 119.2 mb
2.6.2、使用场景
前面的使用可以体验到用极致的空间来达到一个比较大的数据量的存储,而且是基于位的,使用起来也非常简单,还可以统计设置了多少个bit位,所以这让我们一下就想到了统计在线人数的场景。用用户id对应的比特位作为该用户的标识,如果用户在线,则将对应的位标记为1,否则就是0,要查看用户是否在线也非常简单,直接getbit就可以了。但是要注意用户id不连续导致的空间浪费问题
此外,类似的还可以来统计日活和次日留存,比如
# 记录2023-01-01的活跃用户
SETBIT dau:20230101 1001 1
SETBIT dau:20230101 1002 1
# 计算两日重叠用户数(交集)
BITOP AND dau:retention dau:20230101 dau:20230102
BITCOUNT dau:retention
签到、连续打卡
2.6.3、底层数据结构- SDS
Redis的Bitmap底层是基于String类型实现的一个bit位数组,Bitmap操作直接在SDS的二进制数据上执行,避免额外的内存开销。
2.7、HyperLogLog 类型(基于String类型)
2.7.1、HyperLogLog类型相关指令

比如:
- 添加几个元素(两个key分别表示学习Java、php以及python的学生)
127.0.0.1:6379> pfadd stu:java lily david
(integer) 1
127.0.0.1:6379> pfadd stu:php lilei hanmeimei polly
(integer) 1
127.0.0.1:6379> pfadd stu:python polly lucy
(integer) 1
- 统计学生总数
127.0.0.1:6379> pfmerge stu stu:java stu:php stu:python
OK
127.0.0.1:6379> pfcount stu
(integer) 6
先将几个key合并,然后统计
2.7.2、使用场景
从上面的演示案例以及redis提供的指令可以看到,HyperLogLog 擅长的是基数统计方面的功能,所以可以用来做网站或app的日活、pv、uv统计等
注意:HyperLogLog是基于伯努利过程的概率学基数统计,所以并不是完全精确的值
2.7.3、底层数据结构
HyperLogLog的定义如下:
struct hllhdr {
char magic[4];
uint8_t encoding;
uint8_t notused[3];
uint8_t card[8];
uint8_t registers[];
};
1、magic[4]:这个字段是一个 4 字节的字符数组,用来表示数据结构的标识符。在 HyperLogLog 中,它的值始终为"HYLL",用来标识这是一个 HyperLogLog 数据结构。
2、encoding:这是一个 1 字节的字段,用来表示 HyperLogLog 的编码方式。它可以取两个值之一:
HLL_DENSE:表示使用稠密表示方式。HLL_SPARSE:表示使用稀疏表示方式。3、notused[3]:这是一个 3 字节的字段,目前保留用于未来的扩展,要求这些字节的值必须为零。
4、card[8]:这是一个 8 字节的字段,用来存储缓存的基数(基数估计的值)。
5、egisters[]:这个字段是一个可变长度的字节数组,用来存储 HyperLogLog 的数据。
结构如图所示:
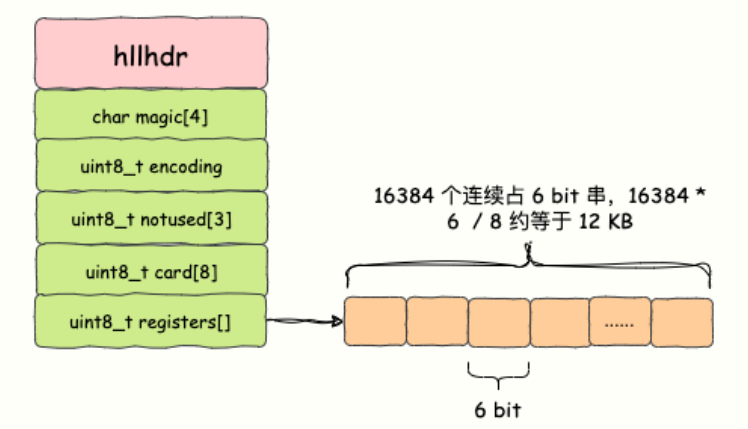
Redis 对 HyperLogLog 的存储进行了优化,在计数比较小的时候,存储空间采用系数矩阵,占用空间很小。只有在计数很大,稀疏矩阵占用的空间超过了阈值才会转变成稠密矩阵,占用 12KB 空间。
2.8、Geospatial 类型
2.8.1、Geospatial类型相关指令

比如:
- 添加两个坐标,北京和武汉
127.0.0.1:6379> geoadd China 116.7244748284355 39.90504785214505 beijing
(integer) 1
127.0.0.1:6379> geoadd China 114.30524758454877 30.592752001304746 wuhan
(integer) 1
127.0.0.1:6379> geoadd China 116.70892241361364 39.50940532715634 langfang
(integer) 1
- 计算北京到武汉的距离
127.0.0.1:6379> geodist China beijing wuhan
"1058699.1391"
用百度地图工具测量一下:https://map.baidu.com/
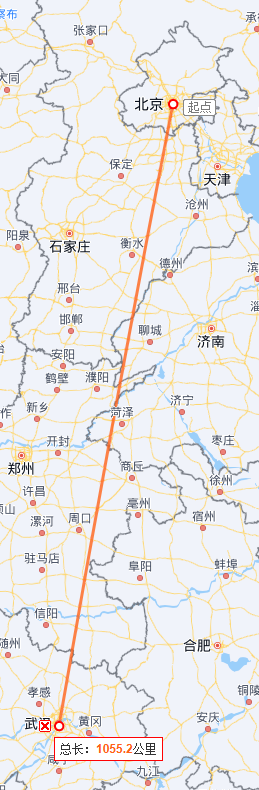
可以看到还是毕竟精确的,结果大差不差
- 查看北京的坐标
127.0.0.1:6379> geopos China beijing
1) 1) "116.7244765162468"
2) "39.90504672149917"
- 查看附近的元素
127.0.0.1:6379> georadius China 117.00631090246314 39.76171292883689 100 km
1) "langfang"
2) "beijing"
127.0.0.1:6379> georadius China 117.00631090246314 39.76171292883689 30 km withcoord
1) 1) "beijing"
2) 1) "116.7244765162468"
2) "39.90504672149917"
127.0.0.1:6379> georadius China 117.00631090246314 39.76171292883689 130 km withcoord count 1
1) 1) "beijing"
2) 1) "116.7244765162468"
2) "39.90504672149917"
127.0.0.1:6379> georadius China 117.00631090246314 39.76171292883689 130 km withcoord count 2
1) 1) "beijing"
2) 1) "116.7244765162468"
2) "39.90504672149917"
2) 1) "langfang"
2) 1) "116.70892506837845"
2) "39.50940463045911"
127.0.0.1:6379> georadius China 117.00631090246314 39.76171292883689 130 km withcoord withdist count 1
1) 1) "beijing"
2) "28.8725"
3) 1) "116.7244765162468"
2) "39.90504672149917"
117.00631090246314 39.76171292883689是廊坊市香河县的坐标
count:查询几个结果
withcoord:把查询结果的经纬度也带出来
withdist:把结果的距离也带出来
2.8.2、使用场景
使用场景就比较明显了,主要用在地图领域
2.8.3、底层数据结构
Geospatial 底层是基于zset进行封装的,比如我们可以用zset的指令操作集合里的元素
127.0.0.1:6379> zrange China 0 -1
1) "wuhan"
2) "langfang"
3) "beijing"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号