pandas 数据分组 -- groupby
groupby:
import random import numpy as np random.seed() df = pd.DataFrame({'data':['a', 'a', 'b', 'b', 'a'], 'num':['one', 'two', 'one', 'two', 'one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)})
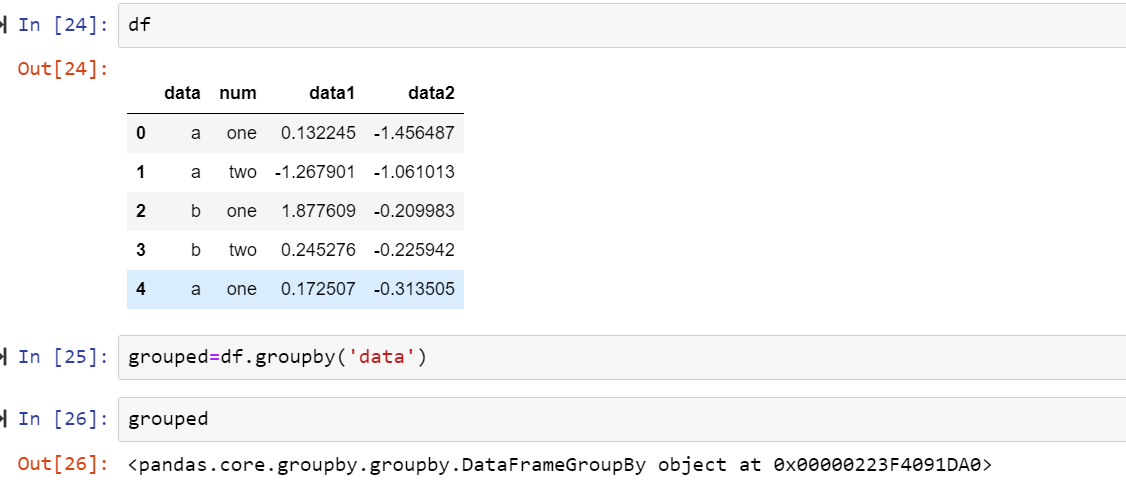

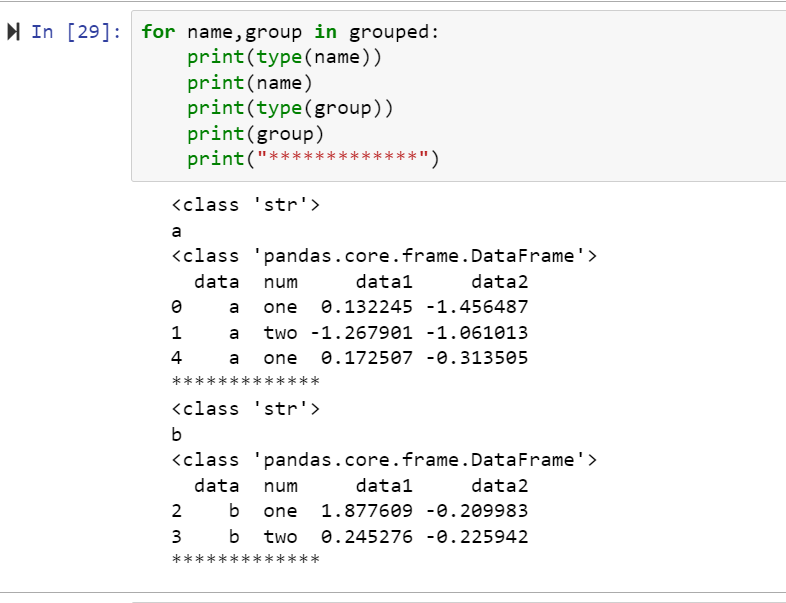
groupby:
import random import numpy as np random.seed() df = pd.DataFrame({'data':['a', 'a', 'b', 'b', 'a'], 'num':['one', 'two', 'one', 'two', 'one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号